Evaluate a Pipeline
After you created a pipeline, it’s time for experiments. Test your pipeline against an evaluation dataset and share it with other users to collect their feedback.
What You Should Know Before You Start
Currently, deepset Cloud supports the evaluation of Preprocessor, Retriever, and Reader nodes. You can combine all types of nodes in your pipelines, but only these three are evaluated.
If you need more information about the metrics and their meaning, see Experiments and metrics..
You must be an Admin user to perform this task.
Evaluate Your Pipeline
Here's what you need to do to find out how your pipeline's performing:
- Upload your files.
- Prepare the evaluation dataset and upload it to deepset Cloud.
- Run an experiment.
- (Optional) Update your pipeline.
- Check user statistics.
Upload Your Files
When creating an evaluation run, you can choose which files you want to include. Your pipeline will run on the files that you indicate. The more files, the more difficult the task of finding the right answers is.
- In deepset Cloud go to Data>Files>Upload File.
- Drag your files and folders to deepset Cloud. You can upload PDF and txt files.
- Click Upload. Your files are now listed on the Files page.
Prepare the Evaluation Dataset
What's an evaluation dataset?
An evaluation dataset is annotated data that your model never saw during the training. You can use it to estimate your model skills.
The evaluation dataset in deepset Cloud is based on the files that you uploaded to Data>Files. After you add your evaluation set, deepset Cloud automatically matches the labels in your dataset with the files in your workspace using file names. If there are labels for which there is no match, deepset Cloud lets you know. The evaluation dataset only works for the files that existed in deepset Cloud at the time when you uploaded the evaluation set.
The evaluation dataset must be a .csv file with the following columns:
- question
- text
- context
- file_name
- answer_start
- answer_end
To learn more about evaluation datasets, see Evaluation datasets.
How do I prepare my own question-answer pairs?
If you want to prepare an annotated dataset for question answering, you can use deepset's Annotation Tool.
- To create an annotated dataset, open the Annotation tool. You will need to set up a free account. Follow the instructions in Annotate datae for question answering to create your dataset.
- If you need more information on how to annotate data, see Guidelines for annotating data.
An example dataset
Here's an evaluation dataset for Harry Potter. This example is meant to show you the format your dataset should follow.
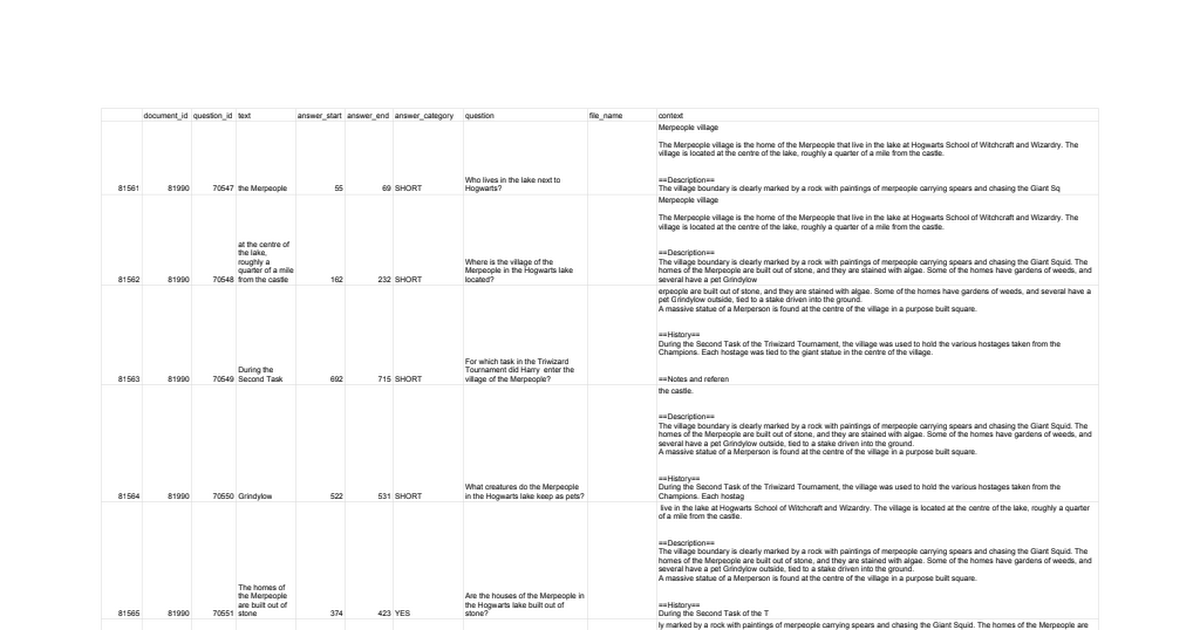
Once you have a dataset ready, upload it to your workspace:
- Log in to deepset Cloud and go to Data>Evaluation Sets>Import Eval Sets.
- Drop your file on the Evaluation Set Import page.
- Click Upload File under your file.
- When the file is successfully uploaded, return to the Evaluation Sets page.
- Find your file and click the copy icon to copy the set's ID. The ID is copied to your clipboard. You will need it when running experiments in a Jupyter Notebook.
Run an Experiment
So this is the part where you actually check how your pipeline is doing.
Create and Start an Experiment Run:
- Log in to deepset Cloud and go to Experiments > New Experiment.
- Choose the pipeline that you want to evaluate.
- Choose the evaluation dataset that you want to use for this experiment.
- Choose the files that you want to use for the experiment.
Your pipeline searches these files to find the answers to the questions from your evaluation dataset. The more files you specify, the more difficult task your pipeline has. - Give your experiment a meaningful name. You can also add tags that will let you identify the experiment later on.
You create tags for the whole workspace, they're not tied to a single experiment. You can use the same tag for multiple experiments. - Choose one of the following:
- To start the experiment now, click Start Experiment. The experiment starts running.
- To save your experiment as a draft, click Save as Draft.
Review Your Experiment
- Log in to deepset Cloud and go to Experiments.
- Click the name of the experiment whose details you want to see. The Experiment Details page opens.
What does this information mean?
The Experiment Details page shows you:
- The experiment status. If the experiment failed, check the Debug section to see what went wrong.
- The details of the experiment: the pipeline and the evaluation set used.
- Metrics for pipeline components. You can see both metrics for integrated and isolated evaluation. For more information about metrics, see Experiments and metrics.
- The pipeline parameters and configuration used for this experiment. It may be different from the actual pipeline as you can update your pipeline just for an experiment run, without modifying the actual pipeline.
You can't edit your pipeline in this view. - Detailed predictions. Here you can see how your pipeline actually did and what answers it returned (predicted answer) in comparison to the expected answers. For each predicted answer, deepset Cloud displays exact match, F1 score, and a rank. The predictions are shown for each node separately.
You can export these data into a CSV file. Open the node whose predicitons you want to export and click Download CSV.
Optional: Update Your Experiment
Coming soon!
Why would I do that?
If you're not happy with the results of your experiment, you can modify, the files, the dataset, or even the pipeline configuration you used for it and see if it improves the results. For example, you can experiment with pipeline nodes by exchanging them for other nodes or modifying their parameters. You can then run the experiment with the updated pipeline and see if the search results are better. You can also update experiment details such as its name or tags.
The changes that you make to the pipeline when updating an experiment run do not affect the actual pipeline. The pipeline is only updated for this particular experiment run to evaluate its performance. If you want to update the actual pipeline, you must copy the pipeline configuration from the experiment run and update the actual pipeline with it.
- Log in to deepset Cloud and go to Experiments.
- Find the experiment that you want to update, click the menu to the right of the experiment name, and select Edit.
- Modify the experiment run and save your changes. Remember that if you update the pipeline in the experiment, the actual pipeline saved on the Pipelines page is not updated.
Update Your Pipeline
If you modified the pipeline for your experiment run and it performed better than the original pipeline configuration, you may want to update the original pipeline with the settings from the experiment run. To do that:
-
Click the name of the experiment to open its details and find the pipeline configuration.
-
Copy the pipeline and paste it to a Notebook or other text editor.
-
In the left-hand navigation, click Pipelines and open the pipeline that you want to update.
-
Replace the contents of the pipeline YAML file with the pipeline that you copied to a Notebook in step 2.
-
Save your changes.
Check User Statistics
You can also check what your users think about your search system and how they actually use it:
- Invite users.
With deepset Cloud, you can easily demonstrate what your pipeline can do. Invite people to your organization, let them test your search, and collect their feedback. Everyone listed on the Organization page can run a search with your pipelines. See also Guidelines for onboarding users. - Review search statistics.
This is another way to see how your pipeline’s doing. On the Dashboard, go to the LATEST REQUESTS section. Here, you can check:- The actual query
- The answer with the highest score
- The pipeline used for the search
- Top file, which for a QA pipeline is the file that contains the top answer, and for a document retrieval pipeline is the file with the highest score
- Who ran the search
- How many seconds it took to find the answer
Updated over 1 year ago