PreProcessing Data with Pipeline Components
Learn about optimal ways to prepare your data using pipeline components available in deepset Cloud. If you need tips and guidelines, you'll find them here.
Indexing Pipeline for Preprocessing
The indexing pipeline converts your files to documents, preprocesses them, and finally stores them in the OpenSearchDocumentStore. The query pipeline then uses the documents from the document store for search.
deepset Cloud offers preprocessing components that you can add to your indexing pipeline. This way, when the pipeline runs, your files are automatically converted, split, and cleaned. Pipeline templates available in deepset Cloud include indexing pipelines that preprocess TXT, PDF, MD, DOCX, and PPTX files out of the box. For other formats, you may need to preprocess outside of deepset Cloud.
Integrations for Processing Data
You can use unstructured.io through UnstructuredFileConverter to preprocess your files. To learn how to do this, see Use Unstructured to Process Documents.
How to Prepare Your Files
Here's an outline of how to plan file preprocessing:
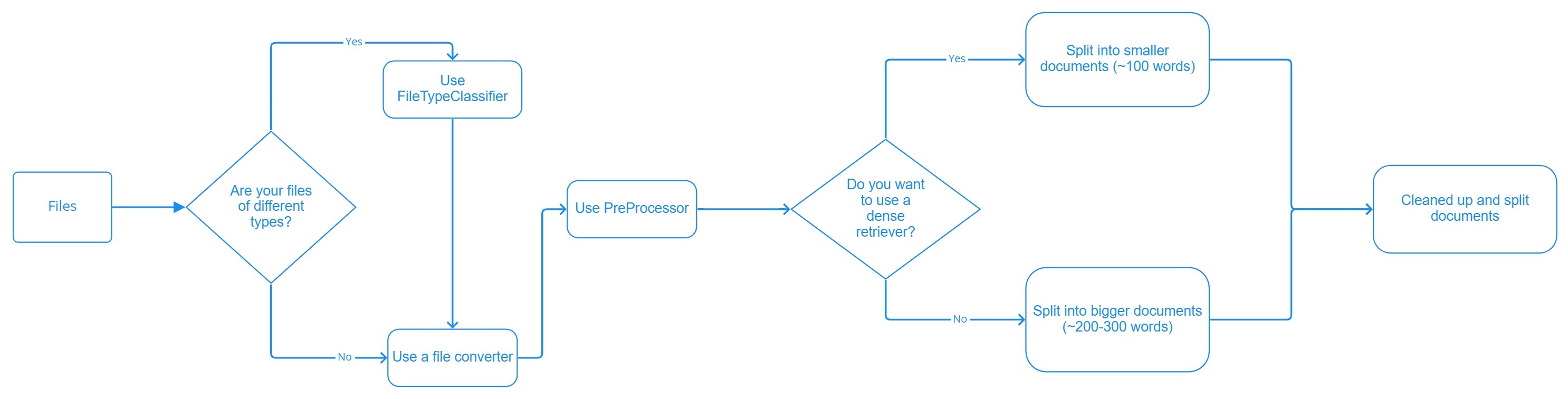
Your files determine which components to use in the indexing pipeline:
- If all your files are of one type, use a file converter appropriate for handling this type as the first component in your indexing pipeline. For supported converters, see Converters.
- If you have multiple file types, use FileTypeRouter as the first component in your indexing pipeline, and a file converter as the second node. FileTypeRouter classifies your files based on their extension and sends them to the converter that can best handle them.
The converter's task is to convert your files into documents. However, the documents you obtain this way may not be of the optimal length for the retriever you want to use and may still need cleaning up. Cleaners and Splitters are the components that handle the cleaning and splitting of documents. They remove headers and footers, which is useful for retaining the flow of sentences across pages; they delete empty lines and split your documents into smaller chunks.
Smaller documents speed up your pipeline. They're also optimal for vector retrievers, which often can't handle longer text passages. We recommend 100-word splits for vector retrievers. Keyword retrievers can work on slightly longer documents of around 200-300 words.
Use these suggestions as a starting point for your indexing pipeline. You may need to experiment with your settings to reach the optimal values for your use case.
Pipeline Components for Preprocessing
Components are very flexible, and you can use them in all types of pipelines, but several ones are typically used for indexing. Have a look at this table to help you choose the right components:
| Preprocessing Step | Node That Does It |
|---|---|
| Sort files by type and route them to appropriate converters for the file type. | FileTypeRouter |
| Convert a file to a document object. You can choose a converter that matches your file types. For file types for which a converter is unavailable, we recommend preprocessing your files outside of deepset Cloud. | Converters |
| Validate text language based on the ISO 639-1 format. | Converters |
| Remove numeric rows from tables. | Converters |
| Add metadata to the returned document. | Converters |
| Split long documents into smaller ones. | DocumentSplitter |
| Get rid of headers, footers, whitespace, and empty lines. | DocumentCleaner |
| Extract text and tables from PDF, JPEG, PNG, MBP, and TIFF files. | Converters |
| Extract content using Unstructured API. | UnstructuredFileConverter |
| Extract entities from documents in the document store and add them to the documents' metadata. | NamedEntityExtractor |
| Calculate embeddings for documents. | Document Embedders |
| Write cleaned and split documents into the document store. | DocumentWriter |
Updated about 1 month ago