ReferencePredictor
Use this component in retrieval augmented generation (RAG) pipelines to predict references for the generated answer.
Basic Information
- Type:
deepset_cloud_custom_nodes.augmenters.reference_predictor.ReferencePredictor - Components it can connect with:
- Generators: A Generator sends the generated replies to ReferencePredictor that adds predicted references to each answer.
- AnswerBuilder: AnswerBuilder can receive the answers with references from ReferencePredictor.
Inputs
| Name | Type | Description |
|---|---|---|
answers | List of GeneratedAnswer objects | The generated answers to which you want to add references. |
Outputs
Name | Type | Description |
|---|---|---|
| List of GeneratedAnswer objects | Generated answers with a metadata field
|
Overview
ReferencePredictor shows references to documents on which the LLM's answer is based. Pipelines that contain ReferencePredictor return answers with references next to them. You can easily view the reference to check if the answer is based on it and ensure the model didn't hallucinate.
The default ReferencePredictor model only works for English data. For other languages, use DeepsetAnswerBuilder, and in the prompt, instruct the model to add references to the generated answers.
This is what the references look like in the interface:
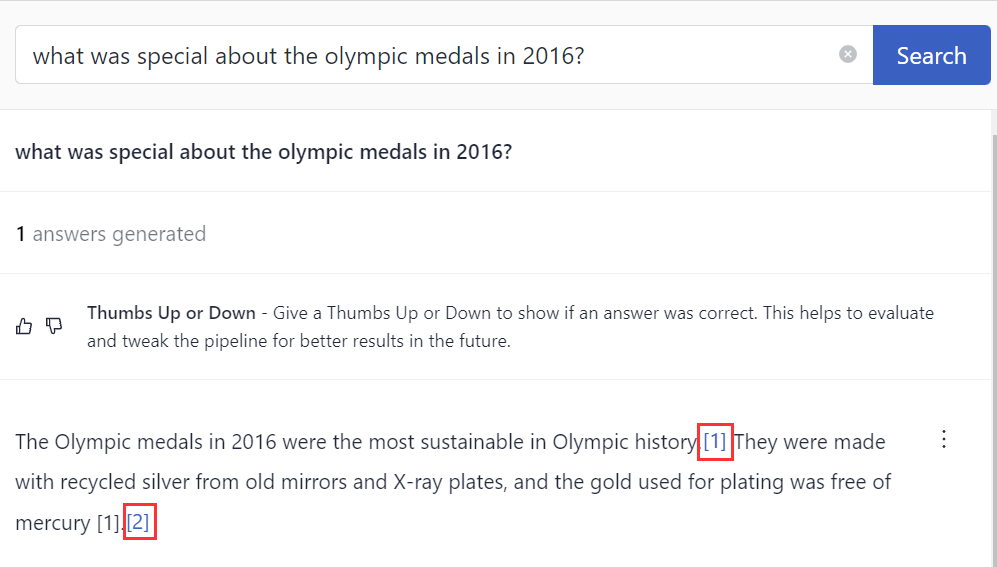
Recommended Settings
Reference Prediction Model
Reference prediction model is the model ReferencePredictor uses to compare the similarity of sentences between the answer and source documents. The default model is cross-encoder/ms-marco-MiniLM-L-6-v2.
Verifiability Model
You can indicate a model you want to use to verify if the generated answers need verification in the verifiability_model_name_or_path parameter. ReferencePredictor uses the tstadel/answer-classification-setfit-v2-binary model by default. We trained this model to reject answers that are noise, out of context, or information there was no answer found. It was trained on English data and works at the sentence level, meaning it verifies full sentences. If your data is in other languages, either provide your own model or set verifiability_model_name_or_path to null.
Splitting Rules
To make sure answers are split correctly, we recommend applying additional rules to the sentence-splitting tokenizer. To apply the rules, set use_split_rules to True.
Abbreviations
We recommend extending the number of abbreviations Punkt tokenizer detects to ensure better sentence splitting. You can do this by setting extend_abbreviations to True.
Usage Example
This is an example of a query pipeline in which ReferencePredictor sends answers with references to AnswerBuilder:
components:
...
reference_predictor:
type: deepset_cloud_custom_nodes.augmenters.reference_predictor.ReferencePredictor
init_parameters:
use_split_rules: True
extend_abbreviations: True
answer_builder:
type: haystack.components.builders.answer_builder.AnswerBuilder
init_parameters: {} # In this example, we're using AnswerBuilder with default parameters
...
connections:
...
- sender: reference_predictor.answers
receiver: answer_builder.answersParameters
Init Parameters
These are the parameters you can configure in Pipeline Builder:
Parameter | Type | Possible values | Description |
|---|---|---|---|
| String | Default: | The name identifier of the model from Hugging Face or the path to a local model folder. |
| String | Default: | The revision of the model to be used. Optional. |
| Integer | Default: | The maximum number of tokens that a sequence should be truncated to before inference. |
| Language | Default: | The language of the data that you want to generate references for. Needed to apply the right sentence splitting rules. |
| ComponentDevice | Default: | The device on which the model is loaded. If |
| Integer | Default: | The batch size that should be used for inference. |
| Integer | Default: | The number of sentences of an answer that should be included in one span for inference. |
| Integer | Default: | The stride size for answer window. Required. |
| Integer | Default: | The number of sentences of a document that should be included in one span for inference. |
| Integer | Default: | The stride size for document window. |
| Secret | Default: | The token to use as HTTP bearer authorization for remote files. |
| String |
| The activation function to use on top of the logits. |
| Dictionary | Default: | The minimum prediction score threshold for each corresponding label. |
| Dictionary | Default: | If using a model with a multi label prediction head, pass in a dictionary mapping label names to a float value. |
| Integer | Default: | The minimum score threshold to determine if a prediction should be included as reference or not. |
| String | Default: | A fallback class that should be used if the predicted score doesn't match any threshold. |
| String | Default: | The name identifier of the verifiability model to be used on the Hugging Face hub or the path to a local model folder. |
| String | Default: | The revision of the verifiability model to be used. |
| Integer | Default: | The batch size that should be used for verifiability inference. |
| List of strings | Default: | The class names to be used to determine if a sentence needs verification. |
| Boolean |
| If |
| Boolean |
| If |
| Dictionary | Default: | Additional keyword arguments for the model. |
| Dictionary | Default: | Additional keyword arguments for the verifiability model. |
Run Method Parameters
These are the parameters you can configure for the component's run() method. This means you can pass these parameters at query time through the API, in Playground, or when running a job. For details, see Modify Pipeline Parameters at Query Time.
Run() method parameters take precedence over initialization parameters.
Parameter | Type | Description |
|---|---|---|
| List of | Replies returned by the Generator. |
Updated 29 days ago