Use Unstructured to Process Documents
Convert files to documents using the Unstructured API.
Unstructured provides tools to extract content from files and transform it into clean documents ready to be chunked and embedded. For a list of supported formats, see Unstructured documentation. You can use free Unstructured API or paid Unstructured Serverless API.
Prerequisites
You need an API key to your Unstructured account.
Use Unstructured
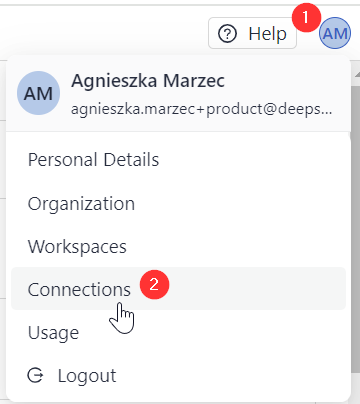
First, connect deepset Cloud to Unstructured through the Connections page:
-
Click your initials in the top right corner and select Connections.
-
Click Connect next to the provider.
-
Enter your user access token and submit it.
Then, add the UnstructuredFileConverter component to your indexing pipeline.
Usage Examples
This is an example of an indexing pipeline that uses Unstructured API to process files:
components:
...
unstructured_converter:
type: haystack_integrations.components.converters.unstructured.converter.UnstructuredFileConverter
init_parameters: {}
splitter:
type: deepset_cloud_custom_nodes.preprocessors.document_splitter.DeepsetDocumentSplitter
init_parameters:
split_by: word
split_length: 250
split_overlap: 30
respect_sentence_boundary: True
language: en
document_embedder:
type: haystack.components.embedders.sentence_transformers_document_embedder.SentenceTransformersDocumentEmbedder
init_parameters:
model: "intfloat/e5-base-v2"
writer:
type: haystack.components.writers.document_writer.DocumentWriter
init_parameters:
document_store:
type: haystack_integrations.document_stores.opensearch.document_store.OpenSearchDocumentStore
init_parameters:
embedding_dim: 768
similarity: cosine
policy: OVERWRITE
connections: # Defines how the components are connected
- sender: unstructured_converter.documents
receiver: splitter.documents
- sender: splitter.documents
receiver: document_embedder.documents
- sender: document_embedder.documents
receiver: writer.documents
max_loops_allowed: 100
inputs: # Define the inputs for your pipeline
files: "file_classifier.sources" # This component will receive the files to index as input
Updated about 1 month ago