Enable References for Generated Answers
Enhance your AI-generated answers with source references to make your app more trustworthy and verifiable.
About This Task
When using an LLM to generate answers, making it cite its resources can significantly enhance the credibility and traceability of the information provided. There are two ways to accomplish this:
- Using the ReferencePredictor component.
- Instructing the LLM to generate references.
The ReferencePredictor component excels at avoiding incorrect or hallucinated references, making it a reliable choice for maintaining accuracy. On the other hand, LLM-generated references perform better when sentences draw information from multiple sources, offering more flexibility in complex scenarios.
You can experiment with both approaches to find the one that's best for your use case.
Pipeline TemplatesReference functionality is already included in RAG pipeline templates in deepset AI Platform through LLM-generated references.
Adding References with ReferencePredictor
ReferencePredictor shows references to documents on which the LLM's answer is based. Pipelines that contain ReferencePredictor return answers with references next to them. You can easily view the reference to check if the answer is based on it and ensure the model didn't hallucinate.
This is what the references look like in the interface:
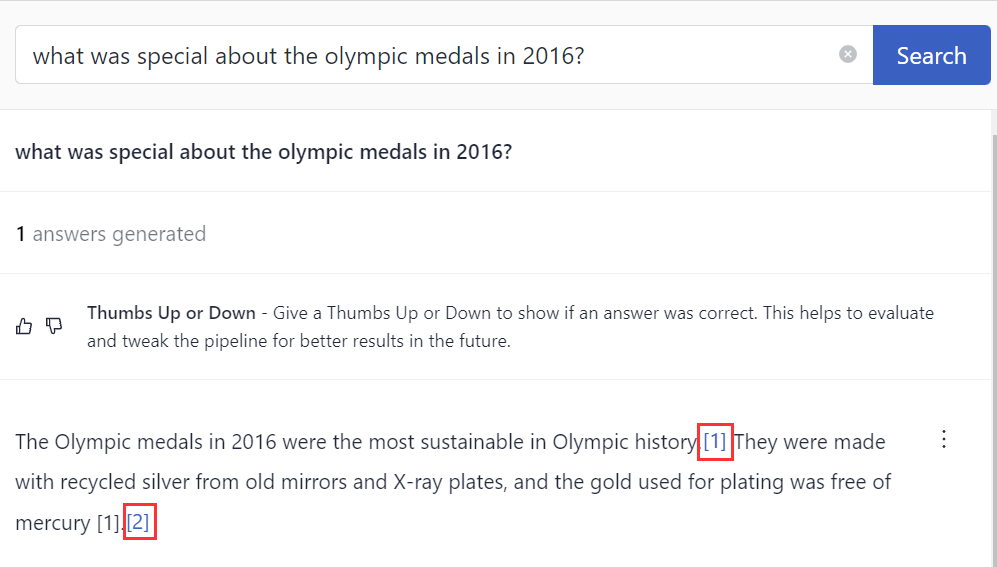
To learn more about this component, see ReferencePredictor.
ReferencePredictor is used in query pipelines after DeepsetAnswerBuilder, from which it receives answers. The answers must include documents to construct references, so you must make sure DeepsetAnswerBuilder receives documents from a preceding component, like a Ranker or a Retriever. DeepsetAnswerBuilder then adds these documents to the answers it sends to ReferencePredictor.
To add ReferencePredictor to your pipeline:
- Add
ReferencePredictorto thecomponentssection of the query pipeline:components: ... reference_predictor: # Finds and displays references to the generated answers from the retrieved documents type: deepset_cloud_custom_nodes.augmenters.reference_predictor.ReferencePredictor init_parameters: model: "cross-encoder/ms-marco-MiniLM-L-6-v2" # The default model used to compare similarity of sentences between the answer and source documents verifiability_model: "tstadel/answer-classification-setfit-v2-binary" # A default model for verifying if the generated answers need verification, it rejects noise and out-of-context answers. It works for English only. Set to `null` for other lanugages. use_split_rules: True # Keep this parameter setting for better splitting extend_abbreviations: True # Extends abbreviations handled with a curated list language: en # The language of the data for which you want to generate the references, defaults to en model_kwargs: # Specifies additional model settings torch_dtype: torch.float16
- The default model used to compare the similarity of sentences between the answer and source documents is
cross-encoder/ms-marco-MiniLM-L-6-v2. You can change it to another model by providing a path to a local model or the model identifier from Hugging Face. - The verifiability model checks if the generated answers need verification. By default, it uses a model we trained to ignore the noise, out-of-context answers, or no answer found. Our model works on English data only, so if your data is in other languages, set
verifiability_mode_name_or_path: nulll. - Setting
use_split_rulestoTrueensures answers are split correctly. - Setting
extend_abbreviationstoTrueextends the number of abbreviations Punkt tokenizer detects to ensure better sentence splitting. - By default, the language of the data is set to English.
For detailed explanations of parameters, see ReferencePredictor.
- In the
connectionssection, configure the connections:- Make sure
DeepsetAnswerBuilderreceives documents and answers from the preceding components. - Connect
DeepsetAnswerBuilder'sanswerstoReferencePredictor.
This is what it should look like... connections: ... - sender: ranker.documents # This can be any component that can send documents to Answerbuilder receiver: answer_builder.documents - sender: llm.replies receiver: answer_builder.replies # Answer builder takes the generated replies and turns them into answers - sender: answer_builder.answers receiver: reference_predictor.answers
- Make sure
- Make sure you specify
ReferencePredictor's output as the final output of the pipeline:outputs: answers: reference_predictor.answers
Here's an example of a query pipeline that uses ReferencePredictor:
components:
bm25_retriever: # Selects the most similar documents from the document store
type: haystack_integrations.components.retrievers.opensearch.bm25_retriever.OpenSearchBM25Retriever
init_parameters:
document_store:
init_parameters:
use_ssl: True
verify_certs: False
hosts:
- ${OPENSEARCH_HOST}
http_auth:
- "${OPENSEARCH_USER}"
- "${OPENSEARCH_PASSWORD}"
type: haystack_integrations.document_stores.opensearch.document_store.OpenSearchDocumentStore
top_k: 20 # The number of results to return
query_embedder:
type: haystack.components.embedders.sentence_transformers_text_embedder.SentenceTransformersTextEmbedder
init_parameters:
model: "intfloat/e5-base-v2"
device: null
embedding_retriever: # Selects the most similar documents from the document store
type: haystack_integrations.components.retrievers.opensearch.embedding_retriever.OpenSearchEmbeddingRetriever
init_parameters:
document_store:
init_parameters:
use_ssl: True
verify_certs: False
http_auth:
- "${OPENSEARCH_USER}"
- "${OPENSEARCH_PASSWORD}"
type: haystack_integrations.document_stores.opensearch.document_store.OpenSearchDocumentStore
top_k: 20 # The number of results to return
document_joiner:
type: haystack.components.joiners.document_joiner.DocumentJoiner
init_parameters:
join_mode: concatenate
ranker:
type: haystack.components.rankers.transformers_similarity.TransformersSimilarityRanker
init_parameters:
model: "intfloat/simlm-msmarco-reranker"
top_k: 8
device: null
model_kwargs:
torch_dtype: "torch.float16"
prompt_builder:
type: haystack.components.builders.prompt_builder.PromptBuilder
init_parameters:
template: |-
You are a technical expert.
You answer questions truthfully based on provided documents.
If the answer exists in several documents, summarize them.
Ignore documents that don't contain the answer to the question.
Only answer based on the documents provided. Don't make things up.
If no information related to the question can be found in the document, say so.
These are the documents:
{% for document in documents %}
Document[{{ loop.index }}]:
{{ document.content }}
{% endfor %}
Question: {{question}}
Answer:
llm:
type: haystack.components.generators.openai.OpenAIGenerator
init_parameters:
api_key: {"type": "env_var", "env_vars": ["OPENAI_API_KEY"], "strict": False}
model: "gpt-3.5-turbo"
generation_kwargs:
max_tokens: 400
temperature: 0.0
seed: 0
answer_builder:
init_parameters: {}
type: deepset_cloud_custom_nodes.augmenters.deepset_answer_builder.DeepsetAnswerBuilder
reference_predictor: # Finds and displays references to the generated answers from the retrieved documents
type: deepset_cloud_custom_nodes.augmenters.reference_predictor.ReferencePredictor
init_parameters:
model: "cross-encoder/ms-marco-MiniLM-L-6-v2"
verifiability_model: "tstadel/answer-classification-setfit-v2-binary"
use_split_rules: True # Uses additional rules for better splitting
extend_abbreviations: True # Extends abbreviations handled with a curated list
language: en
model_kwargs: # Specifies additional model settings
torch_dtype: torch.float16
connections: # Defines how the components are connected
- sender: bm25_retriever.documents
receiver: document_joiner.documents
- sender: query_embedder.embedding
receiver: embedding_retriever.query_embedding
- sender: embedding_retriever.documents
receiver: document_joiner.documents
- sender: document_joiner.documents
receiver: ranker.documents
- sender: ranker.documents
receiver: prompt_builder.documents
- sender: ranker.documents
receiver: answer_builder.documents
- sender: prompt_builder.prompt
receiver: llm.prompt
- sender: llm.replies
receiver: answer_builder.replies
- sender: answer_builder.answers
receiver: reference_predictor.answers
max_loops_allowed: 100
inputs: # Define the inputs for your pipeline
query: # These components will receive the query as input
- "bm25_retriever.query"
- "query_embedder.text"
- "ranker.query"
- "prompt_builder.question"
- "answer_builder.query"
filters: # These components will receive a potential query filter as input
- "bm25_retriever.filters"
- "embedding_retriever.filters"
outputs: # Defines the output of your pipeline
documents: "ranker.documents" # The output of the pipeline is the retrieved documents
answers: "reference_predictor.answers" # The output of the pipeline is the generated answersAdding References with an LLM
To add references using an LLM, you simply need to include specific instructions in your prompt. This method allows the language model to generate references based on its training and the query context.
Here is a prompt we've tested and recommend for you to use:
You are a technical expert.
You answer the questions truthfully on the basis of the documents provided.
For each document, check whether it is related to the question.
To answer the question, only use documents that are related to the question.
Ignore documents that do not relate to the question.
If the answer is contained in several documents, summarize them.
Always use references in the form [NUMBER OF DOCUMENT] if you use information from a document, e.g. [3] for document [3].
Never name the documents, only enter a number in square brackets as a reference.
The reference may only refer to the number in square brackets after the passage.
Otherwise, do not use brackets in your answer and give ONLY the number of the document without mentioning the word document.
Give a precise, accurate and structured answer without repeating the question.
Answer only on the basis of the documents provided. Do not make up facts.
If the documents cannot answer the question or you are not sure, say so.
These are the documents:
{% for document in documents %}
Document[{{ loop.index }}]:
{{ document.content }}
{% endfor %}
Question: {{question}}
Answer:The Generator using the prompt must be connected with DeepsetAnswerBuilder, whose reference_pattern is set to acm for the references to be displayed properly.
Here are the detailed steps to add references with an LLM:
- Add the prompt with instructions to generate references to PromptBuilder:
components: ... prompt_builder: type: haystack.components.builders.prompt_builder.PromptBuilder init_parameters: template: |- <s>[INST] You are a technical expert. You answer the questions truthfully on the basis of the documents provided. For each document, check whether it is related to the question. To answer the question, only use documents that are related to the question. Ignore documents that do not relate to the question. If the answer is contained in several documents, summarize them. Always use references in the form [NUMBER OF DOCUMENT] if you use information from a document, e.g. [3] for document [3]. Never name the documents, only enter a number in square brackets as a reference. The reference may only refer to the number in square brackets after the passage. Otherwise, do not use brackets in your answer and give ONLY the number of the document without mentioning the word document. Give a precise, accurate and structured answer without repeating the question. Answer only on the basis of the documents provided. Do not make up facts. If the documents cannot answer the question or you are not sure, say so. These are the documents: {% for document in documents %} Document[{{ loop.index }}]: {{ document.content }} {% endfor %} Question: {{question}} Answer: [/INST] ... # Here you would also configure other components - Add
DeepsetAnswerBuilderand configure itsreference_patternparameter:components: ... prompt_builder: type: haystack.components.builders.prompt_builder.PromptBuilder init_parameters: template: |- <s>[INST] You are a technical expert. You answer the questions truthfully on the basis of the documents provided. For each document, check whether it is related to the question. To answer the question, only use documents that are related to the question. Ignore documents that do not relate to the question. If the answer is contained in several documents, summarize them. Always use references in the form [NUMBER OF DOCUMENT] if you use information from a document, e.g. [3] for document [3]. Never name the documents, only enter a number in square brackets as a reference. The reference may only refer to the number in square brackets after the passage. Otherwise, do not use brackets in your answer and give ONLY the number of the document without mentioning the word document. Give a precise, accurate and structured answer without repeating the question. Answer only on the basis of the documents provided. Do not make up facts. If the documents cannot answer the question or you are not sure, say so. These are the documents: {% for document in documents %} Document[{{ loop.index }}]: {{ document.content }} {% endfor %} Question: {{question}} Answer: [/INST] answer_builder: type: deepset_cloud_custom_nodes.augmenters.deepset_answer_builder.DeepsetAnswerBuilder init_parameters: reference_pattern: acm ... # here you would also configure other components, like the Generator - Connect the components:
- Connect
PromptBuilder's prompt to the Generator. - Connect the Generator's replies to
DeepsetAnswerBuilder.
Here's what it should look like:connections: ... - sender: prompt_builder.prompt receiver: generator.prompt - sender: generator.replies receiver: answer_builder.replies
- Connect
- Indicate
DeepsetAnswerBuilder's output as the pipeline output:outputs: answers: answer_builder.answers
Here's an example of a query pipeline that uses this approach:
components:
bm25_retriever: # Selects the most similar documents from the document store
type: haystack_integrations.components.retrievers.opensearch.bm25_retriever.OpenSearchBM25Retriever
init_parameters:
document_store:
init_parameters:
use_ssl: True
verify_certs: False
hosts:
- ${OPENSEARCH_HOST}
http_auth:
- "${OPENSEARCH_USER}"
- "${OPENSEARCH_PASSWORD}"
type: haystack_integrations.document_stores.opensearch.document_store.OpenSearchDocumentStore
top_k: 20 # The number of results to return
query_embedder:
type: haystack.components.embedders.sentence_transformers_text_embedder.SentenceTransformersTextEmbedder
init_parameters:
model: "intfloat/e5-base-v2"
device: null
embedding_retriever: # Selects the most similar documents from the document store
type: haystack_integrations.components.retrievers.opensearch.embedding_retriever.OpenSearchEmbeddingRetriever
init_parameters:
document_store:
init_parameters:
use_ssl: True
verify_certs: False
http_auth:
- "${OPENSEARCH_USER}"
- "${OPENSEARCH_PASSWORD}"
type: haystack_integrations.document_stores.opensearch.document_store.OpenSearchDocumentStore
top_k: 20 # The number of results to return
document_joiner:
type: haystack.components.joiners.document_joiner.DocumentJoiner
init_parameters:
join_mode: concatenate
ranker:
type: haystack.components.rankers.transformers_similarity.TransformersSimilarityRanker
init_parameters:
model: "intfloat/simlm-msmarco-reranker"
top_k: 8
device: null
model_kwargs:
torch_dtype: "torch.float16"
prompt_builder:
type: haystack.components.builders.prompt_builder.PromptBuilder
init_parameters:
template: |-
<s>[INST] You are a technical expert.
You answer the questions truthfully on the basis of the documents provided.
For each document, check whether it is related to the question.
To answer the question, only use documents that are related to the question.
Ignore documents that do not relate to the question.
If the answer is contained in several documents, summarize them.
Always use references in the form [NUMBER OF DOCUMENT] if you use information from a document, e.g. [3] for document [3].
Never name the documents, only enter a number in square brackets as a reference.
The reference may only refer to the number in square brackets after the passage.
Otherwise, do not use brackets in your answer and give ONLY the number of the document without mentioning the word document.
Give a precise, accurate and structured answer without repeating the question.
Answer only on the basis of the documents provided. Do not make up facts.
If the documents cannot answer the question or you are not sure, say so.
These are the documents:
{% for document in documents %}
Document[{{ loop.index }}]:
{{ document.content }}
{% endfor %}
Question: {{question}}
Answer:
[/INST]
llm:
type: deepset_cloud_custom_nodes.generators.deepset_amazon_bedrock_generator.DeepsetAmazonBedrockGenerator
init_parameters:
model: "mistral.mistral-large-2402-v1:0"
aws_region_name: us-east-1
max_length: 400 # The maximum number of tokens the generated answer can have
model_max_length: 32000 # The maximum number of tokens the prompt and the generated answer can use
temperature: 0 # Lower temperature works best for fact-based qa
answer_builder:
type: deepset_cloud_custom_nodes.augmenters.deepset_answer_builder.DeepsetAnswerBuilder
init_parameters:
reference_pattern: acm
connections: # Defines how the components are connected
- sender: bm25_retriever.documents
receiver: document_joiner.documents
- sender: query_embedder.embedding
receiver: embedding_retriever.query_embedding
- sender: embedding_retriever.documents
receiver: document_joiner.documents
- sender: document_joiner.documents
receiver: ranker.documents
- sender: ranker.documents
receiver: prompt_builder.documents
- sender: ranker.documents
receiver: answer_builder.documents
- sender: prompt_builder.prompt
receiver: llm.prompt
- sender: llm.replies
receiver: answer_builder.replies
max_loops_allowed: 100
inputs: # Define the inputs for your pipeline
query: # These components will receive the query as input
- "bm25_retriever.query"
- "query_embedder.text"
- "ranker.query"
- "prompt_builder.question"
- "answer_builder.query"
filters: # These components will receive a potential query filter as input
- "bm25_retriever.filters"
- "embedding_retriever.filters"
outputs: # Defines the output of your pipeline
documents: "ranker.documents" # The output of the pipeline is the retrieved documents
answers: "answer_builder.answers"Updated 26 days ago