Use Google Search API
Add a web search to your pipelines using Google Search API.
You can add a search engine that uses Google's Search API to your pipelines.
Prerequisites
You need an API key from Google Search API.
Use Search API
First, connect deepset AI Platform to SearchApi through the Integrations page. You can do so for a single workspace or for the whole organization:
Add Workspace-Level Integration
- Click your profile icon and choose Settings.
- Go to Workspace>Integrations.
- Find the provider you want to connect and click Connect next to them.
- Enter the API key and any other required details.
- Click Connect. You can use this integration in pipelines and indexes in the current workspace.
Add Organization-Level Integration
- Click your profile icon and choose Settings.
- Go to Organization>Integrations.
- Find the provider you want to connect and click Connect next to them.
- Enter the API key and any other required details.
- Click Connect. You can use this integration in pipelines and indexes in all workspaces in the current organization.
For details, see Add Integrations.
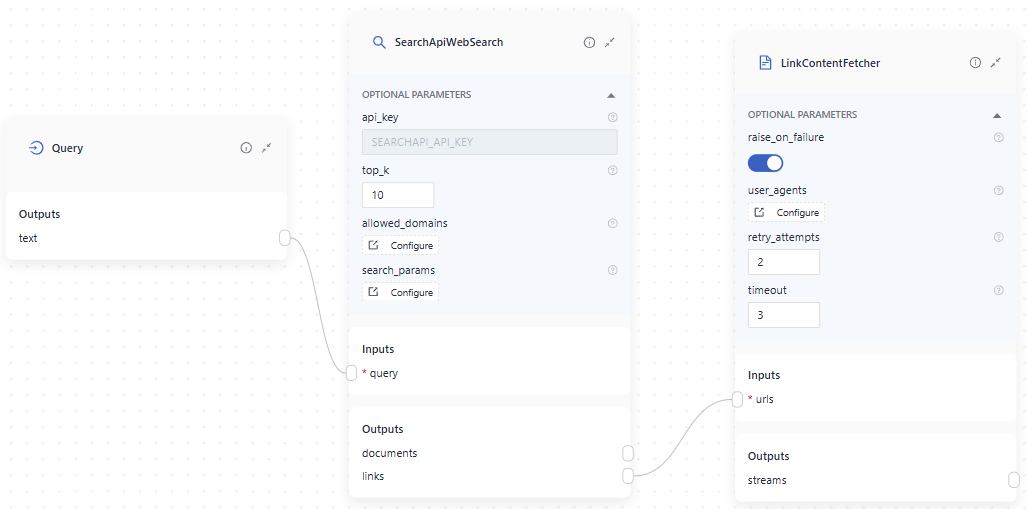
Then, add the SearchApiWebSearch component to your pipeline. This component uses page snippets to find relevant pages and returns a list of URLs. It's typically used before a LinkContentFecther or Converters.
Usage Examples
This is an example of a pipeline that uses SearchApi:
components:
...
web_retriever:
type: haystack.components.websearch.searchapi.SearchApiWebSearch
init_parameters:
top_k: 20
link_fetcher:
type: haystack.components.fetchers.link_content.LinkContentFetcher
init_parameters: {} # we're leaving the default value parameters
html_converter:
type: haystack.components.converters.html.HTMLToDocument
init_parameters:
# A dictionary of keyword arguments to customize how you want to extract content from your HTML files.
# For the full list of available arguments, see
# the [Trafilatura documentation](https://trafilatura.readthedocs.io/en/latest/corefunctions.html#extract).
extraction_kwargs:
output_format: txt # Extract text from HTML. You can also also choose "markdown"
target_language: null # You can define a language (using the ISO 639-1 format) to discard documents that don't match that language.
include_tables: true # If true, includes tables in the output
include_links: false # If true, keeps links along with their targets
...
connections:
...
- sender: web_retriever.links
- receiver: link_fetcher.urls
- sender: link_fetcher.urls
- receiver: html_converter.sources
...
inputs:
query:
- "web_retriever.query"
...Updated about 2 months ago