About Pipelines
Pipelines contain the processing stages needed to execute a query and index your files. These stages are pipeline nodes, that are connected in series so that the output of one node is used by the next node in the pipeline.
How Do Pipelines Work?
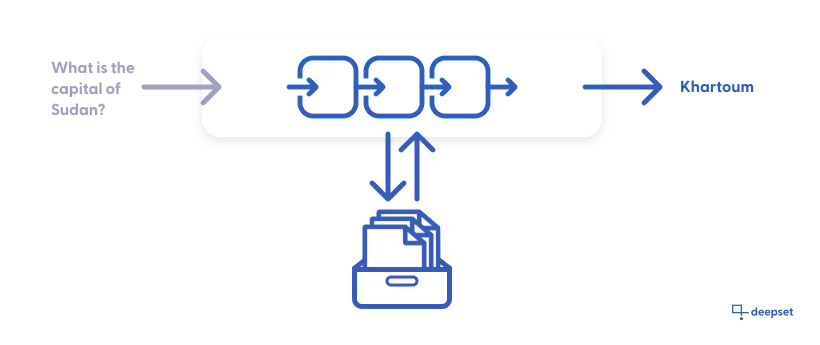
Pipelines define how data flows through its nodes to achieve the best search results. For example, a basic pipeline can be made up of a Retriever and a Reader. When given a query, the retriever goes through all the documents in your deepset Cloud workspace and selects the most relevant ones to the query. Then, the reader uses the documents selected by the retriever and highlights the word, phrase, sentence, or paragraph that answers your query.
Nodes are like building blocks that you can mix and match or replace. They can be connected as a Directed Acyclic Graph (DAG), thus allowing for more complex workflows, such as decision nodes or having the output of multiple nodes combined. When connecting nodes, it's important to understand that the output of one node must be the same as the input of the next node. Go to a node's documentation page to check which nodes it can be combined with. See also Pipeline Nodes.
Pipelines run on the files you uploaded to deepset Cloud. You can't pass files in a query. When you deploy your pipeline, it indexes the files, turns them into Documents, and stores them in the DocumentStore from where they're retrieved at the time of the search. The exact steps involved in indexing are defined in your indexing pipeline. Documents inherit metadata from files. Multiple documents may come from one file.
Your files are indexed once; they aren't indexed every time a pipeline runs. If you add a new file after you deploy your pipeline, only this file is indexed and included in the files the pipeline runs on, without you having to redeploy the pipeline. The same is true for conversion. If you're using a converter node, such as TextConverter or PDFToTextConverter, that converts your files into documents, it does so only once; it doesn't convert them every time you run your search.
deepset Cloud currently supports question answering, information retrieval, and generative pipelines using large language models.
Indexing and Query Pipelines
To run a search in deepset Cloud, you must define two pipelines in your pipeline file:
- A query pipeline that contains a recipe for how to execute a query. It runs on the Documents created from files you uploaded to deepset Cloud. These documents are stored in the DocumentStore.
The input of a query pipeline is alwaysQueryand the output is theAnswer.
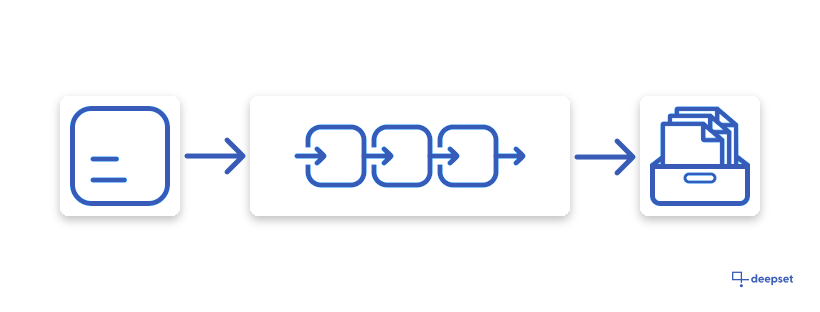
- An indexing pipeline that defines how you want to preprocess your files before running a search on them.
The input of the indexing pipeline is alwaysFileand the output areDocuments.
In deepset Cloud, you define the indexing and query pipelines in one file, which you later deploy to use for search.
Example of an indexing and a query pipeline
components: # define all the nodes that make up your pipeline:
- name: DocumentStore
type: DeepsetCloudDocumentStore
- name: Retriever
type: ElasticsearchRetriever
params:
document_store: DocumentStore # params can reference other Components defined in the YAML
top_k: 20
- name: Reader # custom-name for the component; helpful for visualization & debugging (coming soon)
type: FARMReader # Haystack class name for the Component
params:
model_name_or_path: deepset/roberta-base-squad2-distilled
context_window_size: 500
return_no_answer: true
- name: TextFileConverter
type: TextConverter
- name: Preprocessor
type: PreProcessor
params:
split_by: word
split_length: 250
language: en # Specify the language of your documents
pipelines:
# this is the query pipeline:
- name: query # a sample extractive-qa Pipeline
type: Query
nodes:
- name: Retriever
inputs: [Query]
- name: Reader
inputs: [Retriever]
# this is the indexing pipeline:
- name: indexing
type: Indexing
nodes:
- name: TextFileConverter
inputs: [File]
- name: Preprocessor
inputs: [ TextFileConverter]
- name: Retriever
inputs: [Preprocessor]
- name: DocumentStore #an indexing pipeline must always use a DocumentStore
inputs: [Retriever]
For more pipeline examples, see Pipeline Examples.
Pipeline Service Levels
To save costs and meet your infrastructure and service requirements, your pipelines are assigned service levels. There are three service levels available:
- Draft: This is a service level automatically assigned to new and undeployed pipelines so that you can easily distinguish them from the deployed ones.
- Development: Pipelines at this level are designed for testing and running experiments. They have no replicas by default, and their time to standby is short, so they can save resources whenever these pipelines aren’t used. When you deploy a draft pipeline, it becomes a development pipeline.
- Production: This level is recommended for business-critical scenarios where the pipeline needs to be scalable and reliable. Pipelines at this level include one replica by default and a longer time-to-standby period than other service levels. With heavy traffic, the number of replicas grows up to 10.
This table gives an overview of the settings that come with each service level:
| Service level | Description | Time to standby | Scaling (replicas) | How to enable |
|---|---|---|---|---|
| Production | Designed for critical business scenarios that require reliable and scalable pipelines. | 30 days | 1 at all times, scales up to 10 if traffic is heavy | - In deepset Cloud, on the Pipelines page - Through the Update Pipeline REST API endpoint |
| Development | Designed for testing and experimenting purposes. | 12 hours | 0 | - By switching off the Production service level for a deployed production pipeline in deepset Cloud - Through the Update Pipeline REST API endpoint - By deploying a draft pipeline |
| Draft | Indicates an undeployed pipeline. | n/a | 0 | - By undeploying a production or development pipeline - All new pipelines are automatically classified as drafts |
Time to standby is the time after which an unused pipeline enters a standby mode to save resources. Inactive pipelines don’t use up the pipeline hours included in your plan.
To use a pipeline on standby, activate it either on the Pipelines page or by initiating a search using that pipeline.
Replicas are the number of duplicate versions of a pipeline that are available. In case of any pipeline issues, deepset Cloud seamlessly switches to a functioning replica to maintain uninterrupted service. Pricing plans with production pipelines automatically include one replica. The pipeline hours (the hours your pipeline is deployed) of this replica are not billed separately.
For heavy pipelines, we can increase the maximum number of replicas on request. Contact your deepset Cloud representative to change this setting.
You can change your pipeline's service level at any time. For details, see Change the Pipeline's Service Level.
The Pipelines Page
All the pipelines created by your organization are listed on the Pipelines page. The pipelines listed under Deployed are the ones that you can run your search with. The pipelines under In Development are drafts you must deploy before you can use them for your search.
Clicking a pipeline opens Pipeline Details, where you can check all the information about your pipeline, including pipeline logs.
Pipeline Status
When you deploy a pipeline, it changes its status as follows:
- Not indexed: The pipeline is being deployed, but the files have not yet been indexed
- Indexing: Your files are being indexed. You can see how many files have already been indexed if you hover your mouse over the Indexing label.
- Indexed: Your pipeline is deployed, all the files are indexed, and you can use your pipeline for search.
- Partially indexed: At least one of the files wasn't indexed. This may be an NLP-related problem, a problem with your file, or a Node in the pipeline. You can still run a search if at least some files were indexed.
- Failed to deploy: It's a fatal state. Your pipeline was not deployed, and your files are not indexed. For ideas on how to fix it, see Troubleshoot Pipeline Deployment.
Updated 4 months ago