Enable References for Generated Answers
Enhance your AI-generated answers with source references to make your app more trustworthy and verifiable.
About This Task
When using an LLM to generate answers, making it cite its resources can significantly enhance the credibility and traceability of the information provided. There are two ways to accomplish this:
- Using the ReferencePredictor node.
- Instructing the LLM to generate references.
The ReferencePredictor node excels at avoiding incorrect or hallucinated references, making it a reliable choice for maintaining accuracy. On the other hand, LLM-generated references perform better when sentences draw information from multiple sources, offering more flexibility in complex scenarios.
You can experiment with both approaches to find the one that's best for your use case.
Pipeline Templates
Reference functionality is already included in RAG pipeline templates in deepset Cloud. Depending on the model, it's added either through ReferencePredictor or LLM-generated references.
Adding References with ReferencePredictor
ReferencePredictor shows references to documents that the LLM's answer is based on. Pipelines that contain ReferencePredictor return answers with references next to them. You can easily view the reference to check if the answer is based on it and make sure the model didn't hallucinate.
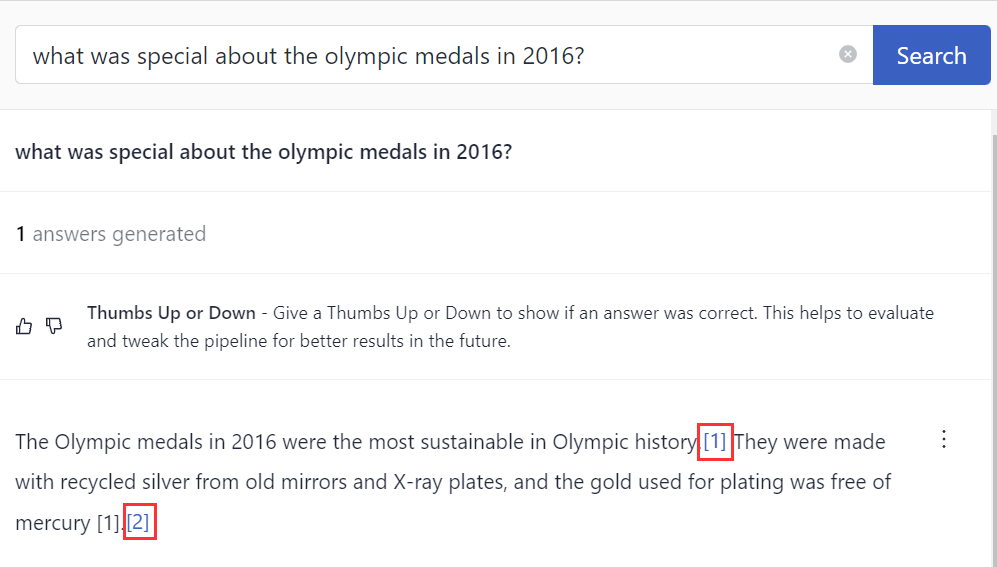
To learn more about this node, see ReferencePredictor.
ReferencePredictor is most often added as the last node in the query pipeline after a PromptNode. It expects an Answer object as input, so make sure the prompt template of the preceding PromptNode has output_parser set to AnswerParser:
name: qa_template
type: PromptTemplate
params:
prompt: deepset/question-answering
output_parser: # This setting is needed for ReferencePredictor
type: AnswerParser
Here is an example of how to add ReferencePredictor to your pipeline:
- Add ReferencePredictor to the
componentssection:
components:
...
- name: ReferencePredictor
type: ReferencePredictor # This component uses settings to make it work in german
params:
model_name_or_path: cross-encoder/ms-marco-MiniLM-L-6-v2 # The default model used to compare similarity of sentences between the answer and source documents
language: en # The language of the data for which you want to generate the references, defaults to en
use_split_rules: True # Keep this parameter setting for better splitting
extend_abbreviations: True # Extends abbreviations handled with a curated list
verifiability_model_name_or_path: tstadel/answer-classification-setfit-v2-binary # A default model for verifying if the generated answers need verification, it rejects noise and out-of-context answers. It works for English only. Set to `null` for other lanugages.
- The default model used to compare the similarity of sentences between the answer and source documents is
cross-encoder/ms-marco-MiniLM-L-6-v2. You can change it to another model by providing a path to a local model or the model identifier from Hugging Face. - By default, the language of the data is set to English.
- Setting
use_split_rulestoTrueensures answers are split correctly. - Setting
extend_abbreviations: Trueextends the number of abbreviations Punkt tokenizer detects to ensure better sentence splitting. - The verifiability model checks if the generated answers need verification. By default, it uses a model we trained to ignore noise, out-of-context answers, or no answer found. Our model works on English data only so if your data is in other languages, set
verfiability_model_name_or_path: null.
For detailed explanations of parameters, see ReferencePredictor Parameters.
- Add ReferencePredictor at the end of the query pipeline and indicate a PromptNode as its input:
pipelines: - name: query nodes: - name: BM25Retriever inputs: [Query] - name: EmbeddingRetriever inputs: [Query] - name: JoinResults inputs: [BM25Retriever, EmbeddingRetriever] - name: Reranker inputs: [JoinResults] - name: PromptNode inputs: [Reranker] - name: ReferencePredictor # ReferencePredictor comes after PromptNode and processes PromptNode's output inputs: [PromptNode] - In the
componentssection of your pipeline YAML, find the PromptTemplate of the PromptNode that precedes ReferencePredictor and make sure it hasoutput_parsertype set toAnswerParser:- name: qa type: PromptTemplate params: output_parser: type: AnswerParser # this ensures PromptNode returns an answer object that ReferencePredictor expects prompt: > # here goes the prompt text
This is an example of a RAG pipeline with ReferencePredictor:
components:
- name: DocumentStore
type: DeepsetCloudDocumentStore
params:
embedding_dim: 768
similarity: cosine
- name: BM25Retriever # The keyword-based retriever
type: BM25Retriever
params:
document_store: DocumentStore
top_k: 15 # The number of results to return
- name: EmbeddingRetriever # Selects the most relevant documents from the document store
type: EmbeddingRetriever # Uses a Transformer model to encode the document and the query
params:
document_store: DocumentStore
embedding_model: intfloat/e5-base-v2 # Model optimized for semantic search. It has been trained on 215M (question, answer) pairs from diverse sources.
model_format: sentence_transformers
top_k: 15 # The number of results to return
- name: JoinResults # Joins the results from both retrievers
type: JoinDocuments
params:
join_mode: concatenate # Combines documents from multiple retrievers
- name: Reranker # Uses a cross-encoder model to rerank the documents returned by the two retrievers
type: SentenceTransformersRanker
params:
model_name_or_path: intfloat/simlm-msmarco-reranker # Fast model optimized for reranking
top_k: 8 # The number of results to return
batch_size: 30 # Try to keep this number equal or larger to the sum of the top_k of the two retrievers so all docs are processed at once
model_kwargs: # Additional keyword arguments for the model
torch_dtype: torch.float16
- name: qa_template
type: PromptTemplate
params:
output_parser:
type: AnswerParser
prompt: |-
You are a technical expert.
You answer questions truthfully based on provided documents.
For each document check whether it is related to the question.
Only use documents that are related to the question to answer it.
Ignore documents that are not related to the question.
If the answer exists in several documents, summarize them.
Only answer based on the documents provided. Don't make things up.
If the documents can't answer the question or you are unsure say: 'The answer can't be found in the text'.
These are the documents:
{join(documents, delimiter=new_line, pattern=new_line+'Document[$idx]:'+new_line+'$content')}
Question: {query}
Answer:
- name: PromptNode
type: PromptNode
params:
default_prompt_template: qa_template
max_length: 400 # The maximum number of tokens the generated answer can have
model_kwargs: # Specifies additional model settings
temperature: 0 # Lower temperature works best for fact-based qa
model_name_or_path: gpt-3.5-turbo
truncate: false
- name: ReferencePredictor # Finds and displays references to the generated answers from the retrieved documents
type: ReferencePredictor
params:
model_name_or_path: cross-encoder/ms-marco-MiniLM-L-6-v2
verifiability_model_name_or_path: tstadel/answer-classification-setfit-v2-binary
language: en
use_split_rules: True # Uses additional rules for better splitting
extend_abbreviations: True # Extends abbreviations handled with a curated list
model_kwargs: # Specifies additional model settings
torch_dtype: torch.float16
- name: FileTypeClassifier # Routes files based on their extension to appropriate converters
type: FileTypeClassifier
params:
raise_on_error: False # If a file type is not recognized, this will make the pipeline skip the file
supported_types: ["txt", "pdf", "md", "docx", "pptx"] # All other file types will be skipped by default
- name: TextConverter # Converts files into documents
type: TextConverter
- name: MarkdownTextConverter # Converts files into documents
type: TextConverter
- name: PDFConverter # Converts PDFs into documents
type: PDFToTextConverter
- name: PptxConverter
type: PptxConverter
- name: DocxToTextConverter
type: DocxToTextConverter
- name: Preprocessor # Splits documents into smaller ones and cleans them up
type: PreProcessor
params:
# With a vector-based retriever, it's good to split your documents into smaller ones
split_by: word # The unit by which you want to split the documents
split_length: 250 # The max number of words in a document
split_overlap: 20 # Enables the sliding window approach
language: en
split_respect_sentence_boundary: True # Retains complete sentences in split documents
# Here you define how the nodes are organized in the pipelines
# For each node, specify its input
pipelines:
- name: query
nodes:
- name: BM25Retriever
inputs: [Query]
- name: EmbeddingRetriever
inputs: [Query]
- name: JoinResults
inputs: [BM25Retriever, EmbeddingRetriever]
- name: Reranker
inputs: [JoinResults]
- name: PromptNode
inputs: [Reranker]
- name: ReferencePredictor
inputs: [PromptNode]
- name: indexing
nodes:
# Depending on the file type, we use a Text or PDF converter
- name: FileTypeClassifier
inputs: [File]
- name: TextConverter
inputs: [FileTypeClassifier.output_1] # Ensures that this converter receives txt files
- name: MarkdownTextConverter
inputs: [FileTypeClassifier.output_3] # Ensures that this converter receives md files
- name: PDFConverter
inputs: [FileTypeClassifier.output_2] # Ensures that this converter receives PDFs
- name: DocxToTextConverter
inputs: [FileTypeClassifier.output_4] # Ensures that this converter receives docx files
- name: PptxConverter
inputs: [FileTypeClassifier.output_5] # Ensures that this converter receives pptx files
- name: Preprocessor
inputs: [TextConverter, MarkdownTextConverter, PDFConverter, DocxToTextConverter, PptxConverter]
- name: EmbeddingRetriever
inputs: [Preprocessor]
- name: DocumentStore
inputs: [EmbeddingRetriever]
Adding References with an LLM
To add references using an LLM, you simply need to include specific instructions in your prompt. This method allows the language model to generate references based on its training and the context of the query.
Here is a prompt we've tested and recommend for you to use:
You are a technical expert.
You answer the questions truthfully on the basis of the documents provided.
For each document, check whether it is related to the question.
To answer the question, only use documents that are related to the question.
Ignore documents that do not relate to the question.
If the answer is contained in several documents, summarize them.
Always use references in the form [NUMBER OF DOCUMENT] if you use information from a document, e.g. [3] for document [3].
Never name the documents, only enter a number in square brackets as a reference.
The reference may only refer to the number in square brackets after the passage.
Otherwise, do not use brackets in your answer and give ONLY the number of the document without mentioning the word document.
Give a precise, accurate and structured answer without repeating the question.
Answer only on the basis of the documents provided. Do not make up facts.
If the documents cannot answer the question or you are not sure, say so.
These are the documents:
{join(documents, delimiter=new_line, pattern=new_line+'Document[$idx]:'+new_line+'$content')}
Question: {query}
Answer:
When using our standard prompt for LLM-generated references, configure the AnswerParser component of the PromptTemplate. Set the reference_pattern parameter of the AnswerParser to the value acm. This ensures that the references are correctly parsed and formatted in the final output.
This is what the complete PromptTemplate with AnswerParser should look like:
name: qa_template # you can change the name
type: PromptTemplate
params:
output_parser: # leave output parser's settings like this
type: AnswerParser
params:
reference_pattern: acm
prompt: |-
You are a technical expert.
You answer the questions truthfully on the basis of the documents provided.
For each document, check whether it is related to the question.
To answer the question, only use documents that are related to the question.
Ignore documents that do not relate to the question.
If the answer is contained in several documents, summarize them.
Always use references in the form [NUMBER OF DOCUMENT] if you use information from a document, e.g. [3] for document [3].
Never name the documents, only enter a number in square brackets as a reference.
The reference may only refer to the number in square brackets after the passage.
Otherwise, do not use brackets in your answer and give ONLY the number of the document without mentioning the word document.
Give a precise, accurate and structured answer without repeating the question.
Answer only on the basis of the documents provided. Do not make up facts.
If the documents cannot answer the question or you are not sure, say so.
These are the documents:
{join(documents, delimiter=new_line, pattern=new_line+'Document[$idx]:'+new_line+'$content')}
Question: {query}
Answer:
Make sure the PromptNode that generates the answers uses this template:
- name: PromptNode
type: PromptNode
params:
default_prompt_template: qa_template # pass the name of the prompt template here
max_length: 400
model_kwargs:
temperature: 0
model_name_or_path: gpt-3.5-turbo
truncate: false
Updated 5 months ago