ReferencePredictor
Use this component in retrieval augmented generation (RAG) pipelines to predict references for the generated answer.
ReferencePredictor shows references to documents that the LLM's answer is based on. Pipelines that contain ReferencePredictor return answers with references next to them. You can easily view the reference to check if the answer is based on it and make sure the model didn't hallucinate.
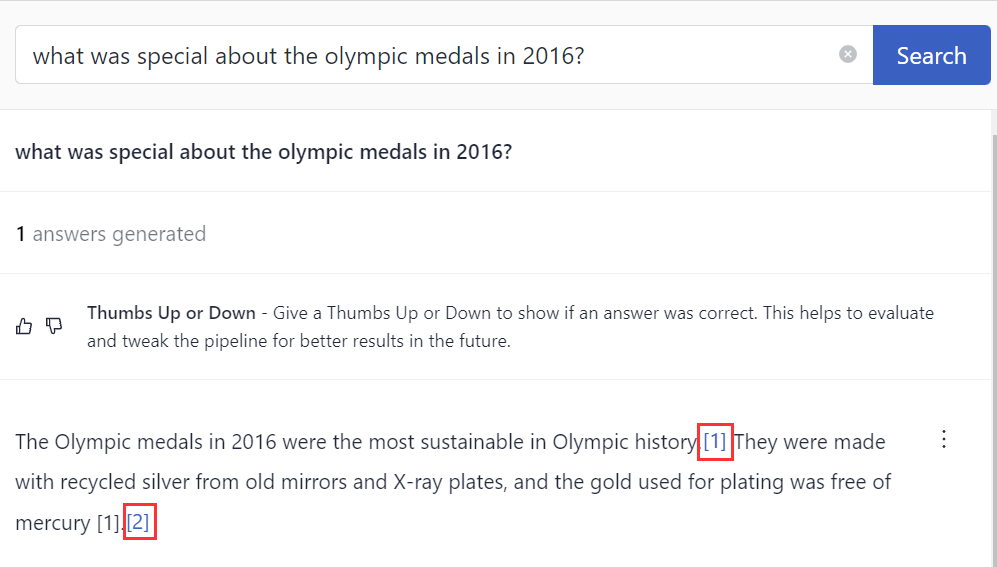
Basic Information
- Pipeline type: Used in generative query pipelines.
- Nodes that can precede it in a pipeline: PromptNode
- Nodes that can follow it in a pipeline: PromptNode, but it's typically used as the last node in a pipeline
- Input: Documents, Answers
- Output: Answers
Recommended Settings
Reference Prediction Model
This is the model ReferencePredictor uses to compare the similarity of sentences between the answer and source documents. The default model is cross-encoder/ms-marco-MiniLM-L-6-v2.
Verifiability Model
You can indicate a model you want to use to verify if the generated answers need verification in the verifiability_model_name_or_path parameter. ReferencePredictor uses the tstadel/answer-classification-setfit-v2-binary model by default. We trained this model to reject answers that are noise, out of context, or information there was no answer found. It was trained on English data and works at the sentence level, meaning if verifies full sentences. If your data is in other languages, either provide your own model or set verifiability_model_name_or_path to null.
Splitting Rules
To make sure answers are split correctly, we recommend applying additional rules to the sentence-splitting tokenizer. To apply the rules, set use_split_rules to True.
Abbreviations
We recommend extending the number of abbreviations Punkt tokenizer detects to ensure better sentence splitting. You can do this by setting extend_abbreviations to True.
Usage Example
When using ReferencePredictor in a pipeline with PromptNode, make sure the prompt doesn't instruct the model to generate references. ReferencePredictor takes care of this.
ReferencePredictor expects an answer object as input, so make sure the PromptNode that precedes it outputs an answer. To do this, explicitly define PromptTemplate setting its output_parser parameter to AnswerParser. For example, to use a prompt from Prompt Studio templates, specify its name and set the parameters:
- name: qa_template #give the template a name
type: PromptTemplate
params:
prompt: deepset/question-answering #This uses one of the ready-made templates from Prompt Studio, you can replace it with an actual prompt
output_parser:
type: AnswerParser
- name: PromptNode
type: PromptNode
params:
default_prompt_template: qa_template #here you're passing the prompt template you defined above to PromptNode
Use this component in generative QA pipelines to show possible references for the answer. First, configure it in the components section, and then add it to your query pipeline. This pipeline uses the recommended settings for ReferencePredictor, which specify the language, additional split rules, and extending abbreviations:
components:
...
- name: qa
type: PromptTemplate
params:
output_parser:
type: AnswerParser # this ensures PromptNode returns an answer object that ReferencePredictor expects
prompt: >
You are a technical expert.
{new_line}You answer questions truthfully based on provided documents.
{new_line}For each document check whether it is related to the question.
{new_line}Only use documents that are related to the question to answer it.
{new_line}Ignore documents that are not related to the question.
{new_line}If the answer exists in several documents, summarize them.
{new_line}Only answer based on the documents provided. Don't make things up.
{new_line}Always use references in the form [NUMBER OF DOCUMENT] when using information from a document. e.g. [3], for Document[3].
{new_line}The reference must only refer to the number that comes in square brackets after passage.
{new_line}Otherwise, do not use brackets in your answer and reference ONLY the number of the passage without mentioning the word passage.
{new_line}If the documents can't answer the question or you are unsure say: 'The answer can't be found in the text'.
{new_line}These are the documents:
{join(documents, delimiter=new_line, pattern=new_line+'Document[$idx]:'+new_line+'$content')}
{new_line}Question: {query}
{new_line}Answer:
- name: PromptNode
type: PromptNode
params:
default_prompt_template: qa
max_length: 400 # The maximum number of tokens the generated answer can have
model_kwargs: # Specifies additional model settings
temperature: 0 # Lower temperature works best for fact-based qa
model_name_or_path: gpt-3.5-turbo
- name: ReferencePredictor
type: ReferencePredictor # This component uses the default settings
params:
language: en
use_split_rules: True
extend_abbreviations: True
pipelines:
- name: query
nodes:
- name: BM25Retriever
inputs: [Query]
- name: EmbeddingRetriever
inputs: [Query]
- name: JoinResults
inputs: [BM25Retriever, EmbeddingRetriever]
- name: Reranker
inputs: [JoinResults]
- name: PromptNode
inputs: [Reranker]
- name: ReferencePredictor # ReferencePredictor comes after PromptNode and processes PromptNode's output
inputs: [PromptNode]
...
# here comes the indexing pipeline
Here's an example of a pipeline where ReferencePredictor uses a custom model and is configured to work with German documents, again using the recommended settings with additional split rules and extended abbreviations:
components:
...
- name: qa_de
type: PromptTemplate
params:
prompt: deepset/question-answering # this is the name of a ready-made prompt from Prompt Studio
output_parser:
type: AnswerParser #this makes sure PromptNode outputs an answer object that ReferencePredictor expects
- name: PromptNode
type: PromptNode
params:
default_prompt_template: qa_de
max_length: 400 # The maximum number of tokens the generated answer can have
model_kwargs: # Specifies additional model settings
temperature: 0 # Lower temperature works best for fact-based qa
model_name_or_path: gpt-3.5-turbo
- name: ReferencePredictor
type: ReferencePredictor # This component uses settings to make it work in german
params:
model_name_or_path: svalabs/cross-electra-ms-marco-german-uncased
language: de
answer_window_size: 2
answer_stride: 2
use_split_rules: True
extend_abbreviations: True
verifiability_model_name_or_path: null #The default verifiability model was trained on English data so it's not going to work for German
pipelines:
- name: query
nodes:
- name: BM25Retriever
inputs: [Query]
- name: EmbeddingRetriever
inputs: [Query]
- name: JoinResults
inputs: [BM25Retriever, EmbeddingRetriever]
- name: Reranker
inputs: [JoinResults]
- name: PromptNode
inputs: [Reranker]
- name: ReferencePredictor # ReferencePredictor comes after PromptNode and processes PromptNode's output
inputs: [PromptNode]
...
# here comes the indexing pipeline
Parameters
Here are the parameters you can set for ReferencePredictor in pipeline YAML:
| Parameter | Type | Possible Values | Description |
|---|---|---|---|
model_name_or_path | String | Default: cross-encoder/ms-marco-MiniLM-L-6-v2 | The model you want ReferencePredictor to use. Specify the name identifier of the model from the Hugging Face Hub or the path to a locally saved model. Mandatory. |
model_kwargs | Dictionary | Default: None | Additional parameters you can pass to the ReferencePredictor model. Optional. |
model_version | String | Default: None | The version of the model to use. Optional. |
max_seq_len | Integer | Default: 512 | Specifies the maximum number of tokens the sequence text can have. The sequence text is the answer and the document span combined. Longer sequences are truncated. Mandatory. |
language | String | Default: en | The language of the data for which you want to generate references. It's needed to apply the correct sentence-splitting rules. Mandatory. |
use_gpu | Boolean | TrueFalseDefault: True | Uses a GPU if available. If not, falls back on a CPU. Mandatory. |
batch_size | Integer | Default: 16 | The number of batches to be processed at once. A batch is the number of answers and document spans that get processed. Mandatory. |
answer_window_size | Integer | Default: 1 | The length of the answer span for which you want ReferencePredictor to generate a reference. The length is in sentences, so setting it to 1 means that the answer span is one sentence, so there'll be a reference generated for each sentence in the answer.If answer_window_size=2, it means the answer span contains two sentences, so there's a reference generated for each answer span that consists of two sentences.Mandatory. |
answer_stride | Integer | Default: 1 | The number of sentences that overlap between adjacent answer spans. For example, if answer_window_size=3 (meaning the answer span is three sentences) and answer_stride=1, there is an overlap of one sentence between each answer span. So in this scenario, the first answer span would be sentences 1 to 3, the second answer span would be sentences 2 to 4, the third 3 to 5, and so on.Mandatory. |
document_window_size | Integer | Default: 3 | The length of the document span for which you want ReferencePredictor to generate a reference. The length is in sentences, so setting it to 1 means that the document span is one sentence, so there'll be a reference generated for each sentence in the answer.If document_window_size=3, it means the document span contains three sentences, so there's a reference generated for each document span that consists of three sentences.Mandatory. |
document_stride | Integer | Default: 3 | The number of sentences that overlap between adjacent document spans. For example, if document_window_size=3 (meaning the document span is three sentences) and document_stride=1, there is an overlap of one sentence between each document span. So, in this scenario, the first document span would be sentences 1 to 3, the second document span would be sentences 2 to 4, the third 3 to 5, and so on.Mandatory. |
use_auth_token | Union[string, Boolean] | Default: None | The token needed to access private models on Hugging Face. Use only if you're using a private model hosted on Hugging Face. Optional. |
devices | List[Union[string, torch.device]] | Default: None | Pass torch devices or identifiers to determine the device inference should run on. Optional |
function_to_apply | String | sigmoidsoftmaxnoneDefault: sigmoid | The activation function to use on top of the logits. Mandatory. |
min_score_2_label_thresholds | Dictionary | Default: None | The minimum prediction score threshold for each corresponding label. Optional. |
label_2_score_map | Dictionary | label: score (example: positive: 0.75)Default: None | If using a model with a multi-label prediction head, pass a dictionary mapping label names to a float value that will be used as a score. You do this to make it possible to aggregate and compare scores later on. Optional. |
reference_threshold | Float | Default: None | If you're using this component to generate references for answer spans, you can pass a minimum threshold that determines if you want the model to include a prediction as a reference for the answer or not. If you don't set any threshold, the model chooses the reference by picking the maximum score. Optional. |
default_class | String | Default: not_grounded | A class to be used if the predicted score doesn't match any threshold. Mandatory. |
verifiability_model_name_or_path | String | Default: tstadel/answer-classification-setfit-v2-binary | The name identifier of the verifiability model from Hugging Face or the path to a local model folder. This model verifies which sentences in the answer need verification, rejecting answers that are noise, out of context, or simply information that an answer couldn't be found. This model was trained for English only. For languages other than English, set this parameter to null.Optional |
verifiability_model_kwargs | Dictionary | Default: None | Additional parameters you can pass to the verifiability model. Optional. |
verifiability_batch_size | Integer | Default: 32 | The batch size to use for verifiability inference. Mandatory. |
needs_verification_classes | List of strings | Default: None | The class names to be used to determine if a sentence needs verification. Defaults to ["needs_verification"]. Mandatory. |
use_split_rules | Boolean | TrueFalseDefault: False | Applies additional rules to the sentence-splitting tokenizer to split the answers better. Mandatory. |
extend_abbreviations | Boolean | TrueFalseDefault: False | If True, the abbreviations used by NLTK's Punkt tokenizer are extended by a list of curated abbreviations if available. If False, the default abbreviations are used. Mandatory. |
Updated 6 months ago