Handling Different Query Types
Queries come in different shapes—keywords, questions, and statements. You can optimize your search by routing each query type to a node that handles it best.
Query Types
There are three query types:
- Keyword queries
- Questions
- Statements
Keyword queries are just keywords. They don't have a sentence structure and the order of words doesn't matter, for example:
- last year results
- results 2022
- USA president
Questions, on the other hand, are complete, grammatical sentences, such as:
- What were the results last year?
- What were the results in 2022?
- Who is the president of the USA
(Pipelines in deepset Cloud don't need a question mark to process a query.)
Statements are declarative sentences, such as:
- Last year results were good.
- Results in 2022 were not satisfying.
- The president of the USA is Joe Biden.
Optimizing the Pipeline To Handle All Query Types
You can configure you pipeline so that each query type is routed to a node that's best at handling it, at the same time saving on GPU resources. For example, you can route questions and statements to a dense Retriever, such as DensePassageRetriever, and keywords to a sparse Retriever, such as BM25Retriever. deepset Cloud offers a node called QueryClassifier that's designed to do just that.
Here's what an example pipeline with this setup would look like:
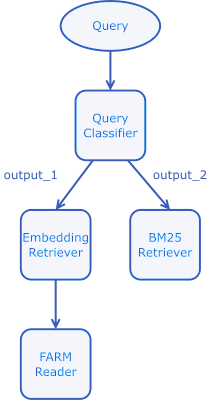
And here's the pipeline code:
components:
#here's how you specify QueryClassifier:
- name: QueryClassifier
type: TransformersQueryClassifier
params:
model_name_or_path: shahrukhx01/bert-mini-finetune-question-detection
- name: DocumentStore
type: DeepsetCloudDocumentStore
- name: DenseRetriever
type: EmbeddingRetriever
params:
document_store: DocumentStore
embedding_model: sentence-transformers/multi-qa-mpnet-base-dot-v1
model_format: sentence_transformers
top_k: 20
- name: SparseRetriever
type: BM25Retriever
params:
document_store: DocumentStore
- name: Reader
type: FARMReader
params:
model: deepset/deberta-v3-base-squad2
use_gpu: True
pipelines:
- name: query
nodes:
- name: QueryClassifier
inputs: [Query]
- name: DenseRetriever
inputs: [QueryClassifier.output_1]
- name: SparseRetriever
inputs: [QueryClassifier.output_2]
- name: Reader
inputs: [DenseRetriever]
... #here you'd need to specify the indexing pipeline
Updated 9 months ago