Understand Your Pipeline Usage
You can monitor your current usage of pipelines, pipeline hours, and storage units anytime on the Usage dashboard.
Navigating the Usage Dashboard
All your usage information is visible on the Usage dashboard you can access from your profile. Click your name in the top right corner and choose Usage.
The top of the dashboard shows a summary of all the information. To see how the data breaks down by pipeline, check the table at the bottom of the dashboard.
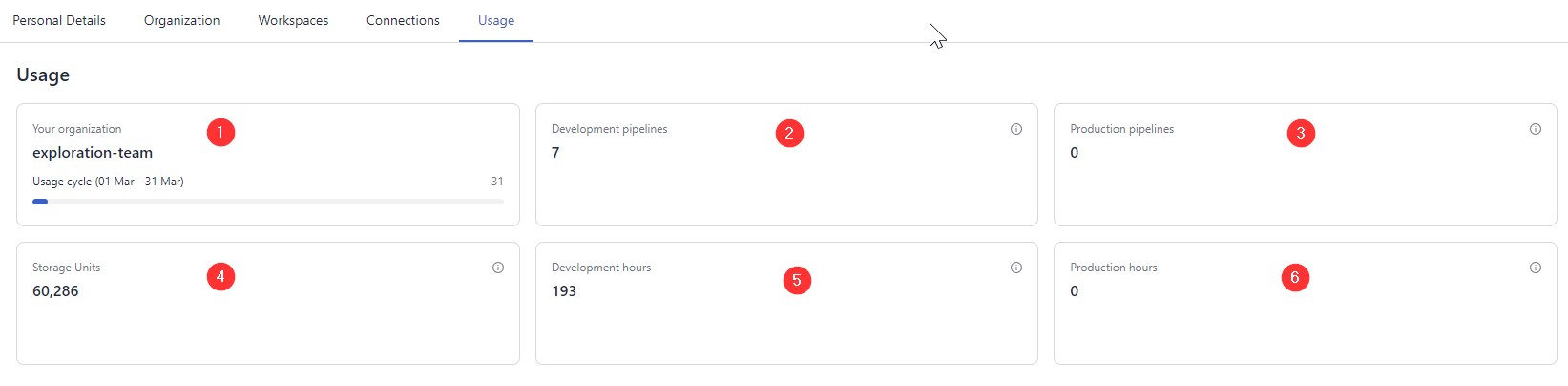
You can check the following information:
-
Organization and usage cycle: Your organization name and the timeframe for the usage data.
-
Development pipelines: The number of pipelines set to a "development" service level that is currently deployed. Note that only deployed pipelines count towards the usage.
To learn more about development pipelines, see Pipeline Service Levels. -
Production pipelines: The number of pipelines set to a "production" service level that is currently deployed. Only deployed pipelines are considered.
To understand production pipelines, see Pipeline Service Levels. -
Storage units: This is the number of documents created from your files multiplied by a factor that reflects the dimensionality of the model used to create embeddings. 768 embedding dimensions of the model correspond to the multiplier of 1. The number of documents you get from a file depends on how you split your files and the embedding model you use.
For example, using the recommended embedding model with 768 dimensions for 5,000 files results in 83,697 documents, equating to 83,697 storage units (document count x 1.)
If you use a model twice as big with 1,536 dimensions, it corresponds to the multiplier of 2, so your storage unit count will be 83, 697 x 2 = 167,394 units.If you use a keyword-based retriever (such as BM25) or if you don't use vector storage, the multiplier is 0.2.
-
Development hours: The number of hours the development pipelines were deployed during this usage cycle. This includes pipelines that were deployed and later deleted. When a pipeline is inactive, no hours are metered. This metric also covers time spent on indexing.
-
Production hours: The number of hours your production pipelines were deployed within the current cycle, including time spent on indexing. This includes pipelines that were already deleted but contributed to production hours during this usage cycle.
At the bottom of the page, you can check the detailed usage per pipeline:
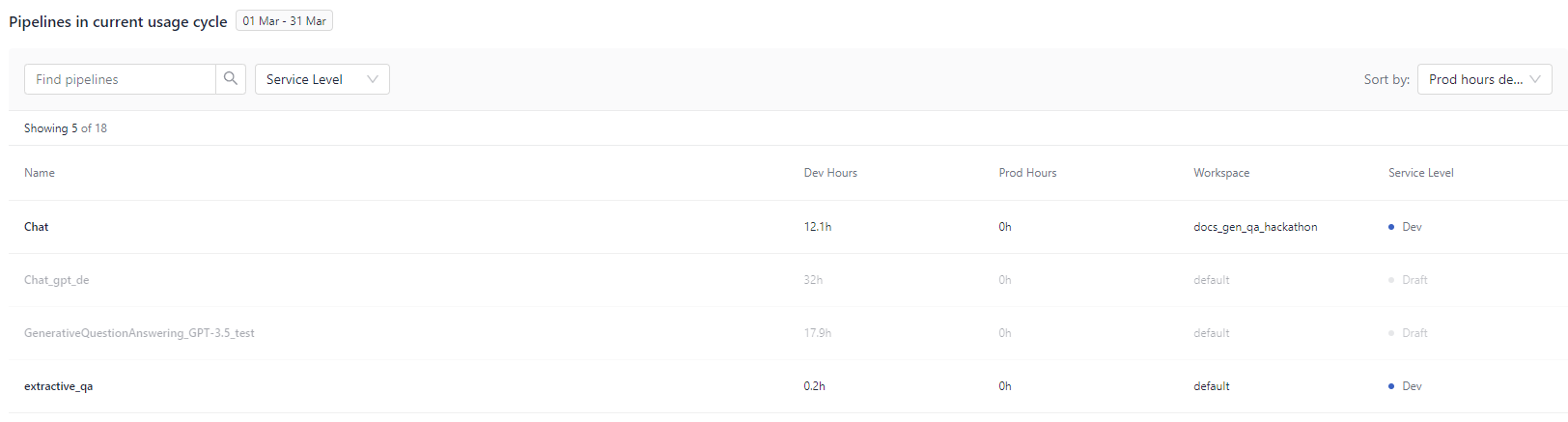
For each pipeline, you can check the number of hours it was at the development and production service level and the workspace it's in. Draft pipelines are pipelines that are undeployed.
Managing Your Storage
Predicting Your Storage Needs
The number of documents you get from your files depends on how you split them during indexing and the embedding dimensions of the model you use with your EmbeddingRetriever to obtain vector representations of your files. The formula for calculating storage units is: number of documents * multiplier. The vector dimension of the embedding model determines the multiplier. A dimension of 768 equates to a multiplier of 1. A dimension of 1024 equates to a multiplier of 1.3.
Let's assume you use one of the recommended embedding models, like intfloat/e5-base-v2, which has a vector dimension of 768 (equal to a multiplier of 1) and default PreProcessor's settings, which are:
components:
- name: Preprocessor
type: PreProcessor
params:
split_by: word
split_length: 200
This configuration splits files by word, resulting in documents of 200 words each. To calculate the anticipated number of documents, divide the total word count of your files by 200.
For example, with 5,000 files, each containing 1000 words, you have a total of 5 million words. Now, divide this total by 200 (the default split length), and you get 25,000 documents. If you use the intfloat/e5-base-v2 model, you must now multiply the document count by 1. You obtain 25,000 storage units.
Optimizing Storage Usage
As you near your storage capacity, you can reduce storage consumption by:
- Deleting duplicate files.
- Reducing irrelevant files starting from the largest ones. Detecting irrelevant files is specific to your use case. You can use the Search History endpoint to check user queries, files, and documents used.
- Adjusting settings in PreProcessor:
- If your
split_overlapsetting is high, consider decreasing it. - If your
split_lengthsetting is low, try increasing it. Rembemer that it's important to avoid too large values to avoid Retriever and Generator nodes cutting the documents.
- If your
Updated 6 months ago