AmazonBedrockDocumentEmbedder
Calculate document embeddings using models through the Amazon Bedrock API.
Amazon Bedrock is a fully managed service that makes state-of-the-art language models available for use through a unified API. To learn more, see Amazon Bedrock documentation.
You can use this component with the following models:
- amazon.titan-embed-text-v1
- cohere.embed-english-v3
- cohere.embed-multilingual-v3
- amazon.titan-embed-text-v2:0
The embedding model you use to embed documents in your index must be the same as the embedding model you use to embed the query in your pipeline.
This means the embedders for your indexes and pipelines must match. For example, if you use CohereDocumentEmbedder to embed your documents, you should use CohereTextEmbedder with the same model to embed your queries.
Only Cohere models support computing embeddings for more documents with the same request.
Key Features
- Computes vector embeddings for documents using Amazon Bedrock models.
- Supports multiple embedding models, including Amazon Titan and Cohere.
- Can embed document metadata alongside document text to improve retrieval quality.
- Supports batch processing for Cohere models.
- Stores embeddings in the
embeddingfield of eachDocumentobject. - Use
AmazonBedrockDocumentEmbedderto embed documents in indexes. To embed a query string, useAmazonBedrockTextEmbedderinstead.
Configuration
Configuration
To use this component, connect Haystack Platform with Amazon Bedrock first. You'll need the region name, access key ID, and secret access key.
Add Workspace-Level Integration
- Click your profile icon and choose Settings.
- Go to Workspace>Integrations.
- Find the provider you want to connect and click Connect next to them.
- Enter the API key and any other required details.
- Click Connect. You can use this integration in pipelines and indexes in the current workspace.
Add Organization-Level Integration
- Click your profile icon and choose Settings.
- Go to Organization>Integrations.
- Find the provider you want to connect and click Connect next to them.
- Enter the API key and any other required details.
- Click Connect. You can use this integration in pipelines and indexes in all workspaces in the current organization.
For detailed explanation, see Use Amazon Bedrock and SageMaker Models.
- Drag the
AmazonBedrockDocumentEmbeddercomponent onto the canvas from the Component Library. - Click on the component to open the configuration panel.
- On the General tab:
- Select the embedding model from the list.
- Go to the Advanced tab to configure additional settings, such as
batch_size,progress_bar,meta_fields_to_embed,embedding_separator, andboto3_config.
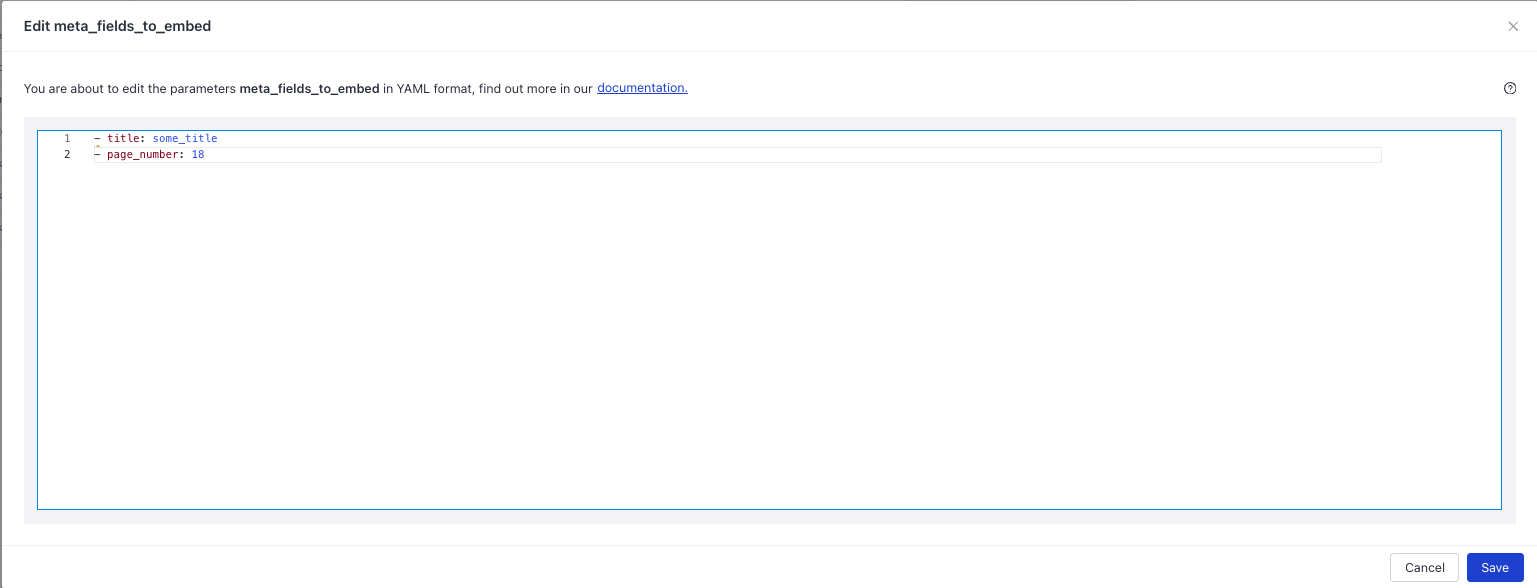
Embedding Document Metadata
You can embed documents' metadata along with the document text. This is useful if the metadata is semantically meaningful and embedding it can improve retrieval. To do this, list the fields to embed in the meta_fields_to_embed parameter:
Connections
AmazonBedrockDocumentEmbedder receives a list of documents to embed. Connect a preprocessor like DocumentSplitter to its documents input.
It outputs the same documents with the embedding field populated. Connect its documents output to DocumentWriter to write the embedded documents into the document store.
Source Code
To check this component's source code, open document_embedder.py in the Haystack Core Integrations repository.
Usage Examples
Basic Configuration
AmazonBedrockDocumentEmbedder:
type: haystack_integrations.components.embedders.amazon_bedrock.document_embedder.AmazonBedrockDocumentEmbedder
init_parameters:
model: amazon.titan-embed-text-v1
aws_access_key_id:
type: env_var
env_vars:
- AWS_ACCESS_KEY_ID
strict: false
aws_secret_access_key:
type: env_var
env_vars:
- AWS_SECRET_ACCESS_KEY
strict: false
aws_session_token:
type: env_var
env_vars:
- AWS_SESSION_TOKEN
strict: false
aws_region_name:
type: env_var
env_vars:
- AWS_DEFAULT_REGION
strict: false
aws_profile_name:
type: env_var
env_vars:
- AWS_PROFILE
strict: false
batch_size: 32
progress_bar: true
meta_fields_to_embed:
- title: travelling_in_africa
- type: guide
embedding_separator: \n
Using the Component in an Index
This is an example of a standard English index where AmazonBedrockDocumentEmbedder receives the documents from DocumentJoiner and sends them to DocumentWriter. It also has a list of metadata fields to embed:
# haystack-pipeline
# If you need help with the YAML format, have a look at https://docs.cloud.deepset.ai/v2.0/docs/create-a-pipeline#create-a-pipeline-using-pipeline-editor.
# This section defines components that you want to use in your pipelines. Each component must have a name and a type. You can also set the component's parameters here.
# The name is up to you, you can give your component a friendly name. You then use components' names when specifying the connections in the pipeline.
# Type is the class path of the component. You can check the type on the component's documentation page.
components:
file_classifier:
type: haystack.components.routers.file_type_router.FileTypeRouter
init_parameters:
mime_types:
- text/plain
- application/pdf
- text/markdown
- text/html
- application/vnd.openxmlformats-officedocument.wordprocessingml.document
- application/vnd.openxmlformats-officedocument.presentationml.presentation
- application/vnd.openxmlformats-officedocument.spreadsheetml.sheet
- text/csv
text_converter:
type: haystack.components.converters.txt.TextFileToDocument
init_parameters:
encoding: utf-8
pdf_converter:
type: haystack.components.converters.pdfminer.PDFMinerToDocument
init_parameters:
line_overlap: 0.5
char_margin: 2
line_margin: 0.5
word_margin: 0.1
boxes_flow: 0.5
detect_vertical: true
all_texts: false
store_full_path: false
markdown_converter:
type: haystack.components.converters.txt.TextFileToDocument
init_parameters:
encoding: utf-8
html_converter:
type: haystack.components.converters.html.HTMLToDocument
init_parameters:
# A dictionary of keyword arguments to customize how you want to extract content from your HTML files.
# For the full list of available arguments, see
# the [Trafilatura documentation](https://trafilatura.readthedocs.io/en/latest/corefunctions.html#extract).
extraction_kwargs:
output_format: markdown # Extract text from HTML. You can also also choose "txt"
target_language: # You can define a language (using the ISO 639-1 format) to discard documents that don't match that language.
include_tables: true # If true, includes tables in the output
include_links: true # If true, keeps links along with their targets
docx_converter:
type: haystack.components.converters.docx.DOCXToDocument
init_parameters:
link_format: markdown
pptx_converter:
type: haystack.components.converters.pptx.PPTXToDocument
init_parameters: {}
xlsx_converter:
type: haystack.components.converters.xlsx.XLSXToDocument
init_parameters: {}
csv_converter:
type: haystack.components.converters.csv.CSVToDocument
init_parameters:
encoding: utf-8
joiner:
type: haystack.components.joiners.document_joiner.DocumentJoiner
init_parameters:
join_mode: concatenate
sort_by_score: false
joiner_xlsx: # merge split documents with non-split xlsx documents
type: haystack.components.joiners.document_joiner.DocumentJoiner
init_parameters:
join_mode: concatenate
sort_by_score: false
splitter:
type: haystack.components.preprocessors.document_splitter.DocumentSplitter
init_parameters:
split_by: word
split_length: 250
split_overlap: 30
respect_sentence_boundary: true
language: en
writer:
type: haystack.components.writers.document_writer.DocumentWriter
init_parameters:
document_store:
type: haystack_integrations.document_stores.opensearch.document_store.OpenSearchDocumentStore
init_parameters:
hosts:
index: ''
max_chunk_bytes: 104857600
embedding_dim: 768
return_embedding: false
method:
mappings:
settings:
create_index: true
http_auth:
use_ssl:
verify_certs:
timeout:
policy: OVERWRITE
AmazonBedrockDocumentEmbedder:
type: haystack_integrations.components.embedders.amazon_bedrock.document_embedder.AmazonBedrockDocumentEmbedder
init_parameters:
model: amazon.titan-embed-text-v1
aws_access_key_id:
type: env_var
env_vars:
- AWS_ACCESS_KEY_ID
strict: false
aws_secret_access_key:
type: env_var
env_vars:
- AWS_SECRET_ACCESS_KEY
strict: false
aws_session_token:
type: env_var
env_vars:
- AWS_SESSION_TOKEN
strict: false
aws_region_name:
type: env_var
env_vars:
- AWS_DEFAULT_REGION
strict: false
aws_profile_name:
type: env_var
env_vars:
- AWS_PROFILE
strict: false
batch_size: 32
progress_bar: true
meta_fields_to_embed:
- title: travelling_in_africa
- type: guide
embedding_separator: \n
boto3_config:
connections: # Defines how the components are connected
- sender: file_classifier.text/plain
receiver: text_converter.sources
- sender: file_classifier.application/pdf
receiver: pdf_converter.sources
- sender: file_classifier.text/markdown
receiver: markdown_converter.sources
- sender: file_classifier.text/html
receiver: html_converter.sources
- sender: file_classifier.application/vnd.openxmlformats-officedocument.wordprocessingml.document
receiver: docx_converter.sources
- sender: file_classifier.application/vnd.openxmlformats-officedocument.presentationml.presentation
receiver: pptx_converter.sources
- sender: file_classifier.application/vnd.openxmlformats-officedocument.spreadsheetml.sheet
receiver: xlsx_converter.sources
- sender: file_classifier.text/csv
receiver: csv_converter.sources
- sender: text_converter.documents
receiver: joiner.documents
- sender: pdf_converter.documents
receiver: joiner.documents
- sender: markdown_converter.documents
receiver: joiner.documents
- sender: html_converter.documents
receiver: joiner.documents
- sender: docx_converter.documents
receiver: joiner.documents
- sender: pptx_converter.documents
receiver: joiner.documents
- sender: joiner.documents
receiver: splitter.documents
- sender: splitter.documents
receiver: joiner_xlsx.documents
- sender: xlsx_converter.documents
receiver: joiner_xlsx.documents
- sender: csv_converter.documents
receiver: joiner_xlsx.documents
- sender: joiner_xlsx.documents
receiver: AmazonBedrockDocumentEmbedder.documents
- sender: AmazonBedrockDocumentEmbedder.documents
receiver: writer.documents
inputs: # Define the inputs for your pipeline
files: # This component will receive the files to index as input
- file_classifier.sources
max_runs_per_component: 100
metadata: {}
Parameters
Inputs
| Parameter | Type | Description |
|---|---|---|
documents | List[Document] | The documents to embed. |
Outputs
| Parameter | Type | Description |
|---|---|---|
documents | List[Document] | The documents with the embedding field populated with the calculated embedding. |
Init Parameters
These are the parameters you can configure in Pipeline Builder:
| Parameter | Type | Default | Description |
|---|---|---|---|
| model | Literal['amazon.titan-embed-text-v1', 'cohere.embed-english-v3', 'cohere.embed-multilingual-v3', 'amazon.titan-embed-text-v2:0'] | The embedding model to use. Choose the model from the list on the component card. | |
| aws_access_key_id | Optional[Secret] | Secret.from_env_var('AWS_ACCESS_KEY_ID', strict=False) | AWS access key ID. Connect Haystack Platform to Amazon Bedrock on the Integrations page. |
| aws_secret_access_key | Optional[Secret] | Secret.from_env_var('AWS_SECRET_ACCESS_KEY', strict=False) | AWS secret access key. Connect Haystack Platform to Amazon Bedrock on the Integrations page. |
| aws_session_token | Optional[Secret] | Secret.from_env_var('AWS_SESSION_TOKEN', strict=False) | AWS session token. Connect Haystack Platform to Amazon Bedrock on the Integrations page. |
| aws_region_name | Optional[Secret] | Secret.from_env_var('AWS_DEFAULT_REGION', strict=False) | AWS region name. Connect Haystack Platform to Amazon Bedrock on the Integrations page. |
| aws_profile_name | Optional[Secret] | Secret.from_env_var('AWS_PROFILE', strict=False) | AWS profile name. Connect Haystack Platform to Amazon Bedrock on the Integrations page. |
| batch_size | int | 32 | Number of documents to embed at once. Only Cohere models support batch inference. This parameter is ignored for Amazon Titan models. |
| progress_bar | bool | True | Shows a progress bar or not. We recommend disabling it in production deployments to keep the logs clean. |
| meta_fields_to_embed | Optional[List[str]] | None | List of metadata fields to embed along with the document text. |
| embedding_separator | str | \n | Separator used to concatenate the metadata fields to the document text. |
| boto3_config | Optional[Dict[str, Any]] | None | The configuration for the boto3 client. |
| kwargs | Any | Additional parameters to pass for model inference. For example, input_type and truncate for Cohere models. |
Run Method Parameters
These are the parameters you can configure for the component's run() method. This means you can pass these parameters at query time through the API, in Playground, or when running a job. For details, see Modify Pipeline Parameters at Query Time.
| Parameter | Type | Description |
|---|---|---|
documents | List[Document] | The documents to embed. |
Related Information
Was this page helpful?