Data Flow in Haystack Enterprise Platform
Explore the journey of data in Haystack Enterprise Platform, from the moment you upload your files or connect your data storage, through processing, to output.
Where Is My Data?
Let's start with what happens to the files when you upload them to Haystack Platform and where they are stored. This differs a bit depending on whether you're uploading synchronously or asynchronously. It's also different if you're connecting your own virtual private cloud (VPC), like the AWS S3 bucket. Let's look at all these scenarios.
Uploading Files
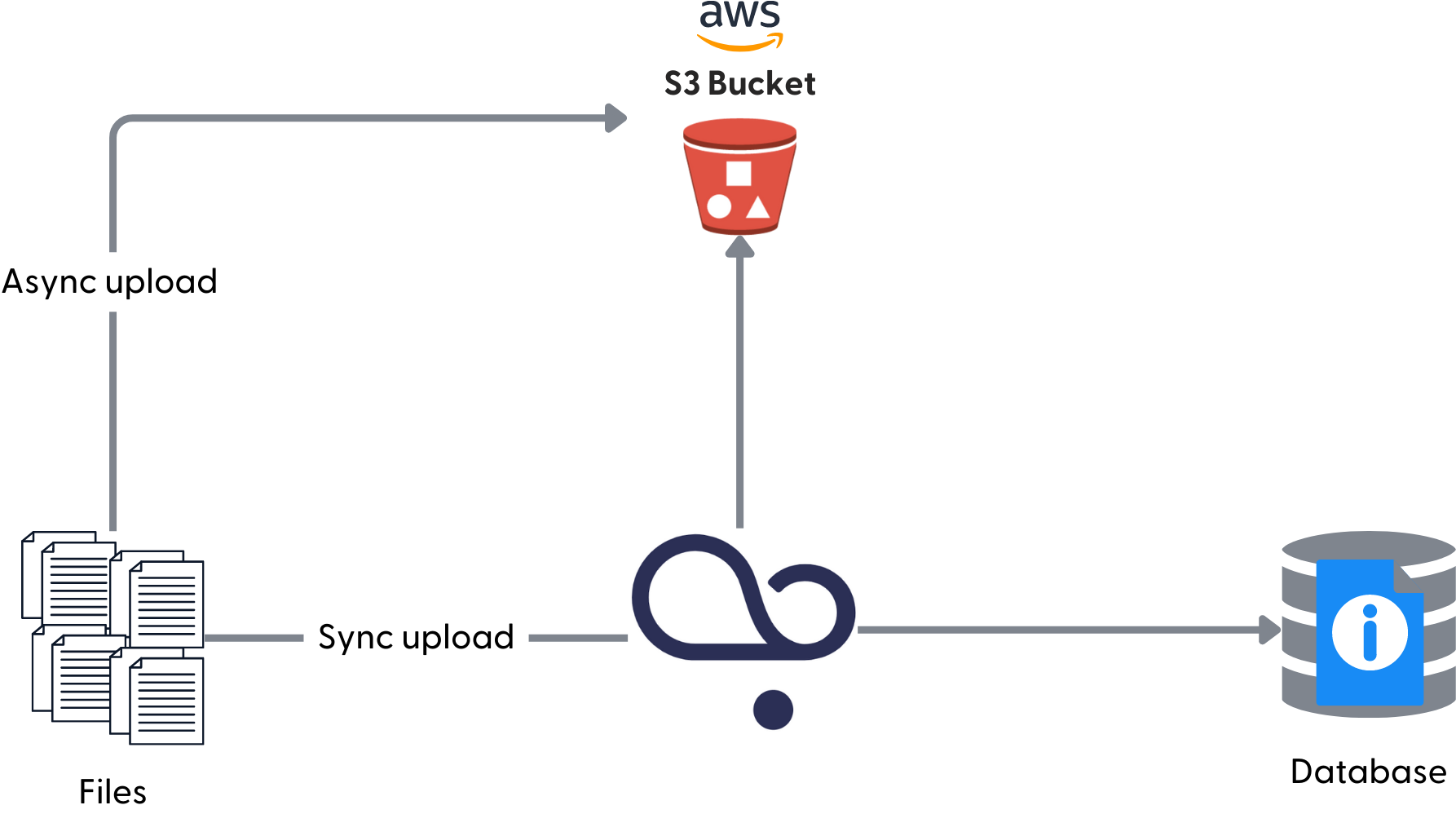
All files uploaded to Haystack Enterprise Platform are eventually stored in the Haystack Platform AWS S3 bucket. There are two methods for uploading files: synchronous and asynchronous. When you upload synchronously, there's an additional step where the files go through the Haystack Platform main API service before they're sent to S3. When you upload asynchronously, using sessions, your files go directly to the S3 bucket.
Haystack Enterprise Platform is also connected to a SQL database. This database stores information about files, such as file name, file id, and when it was created. It does not store the contents of the files.
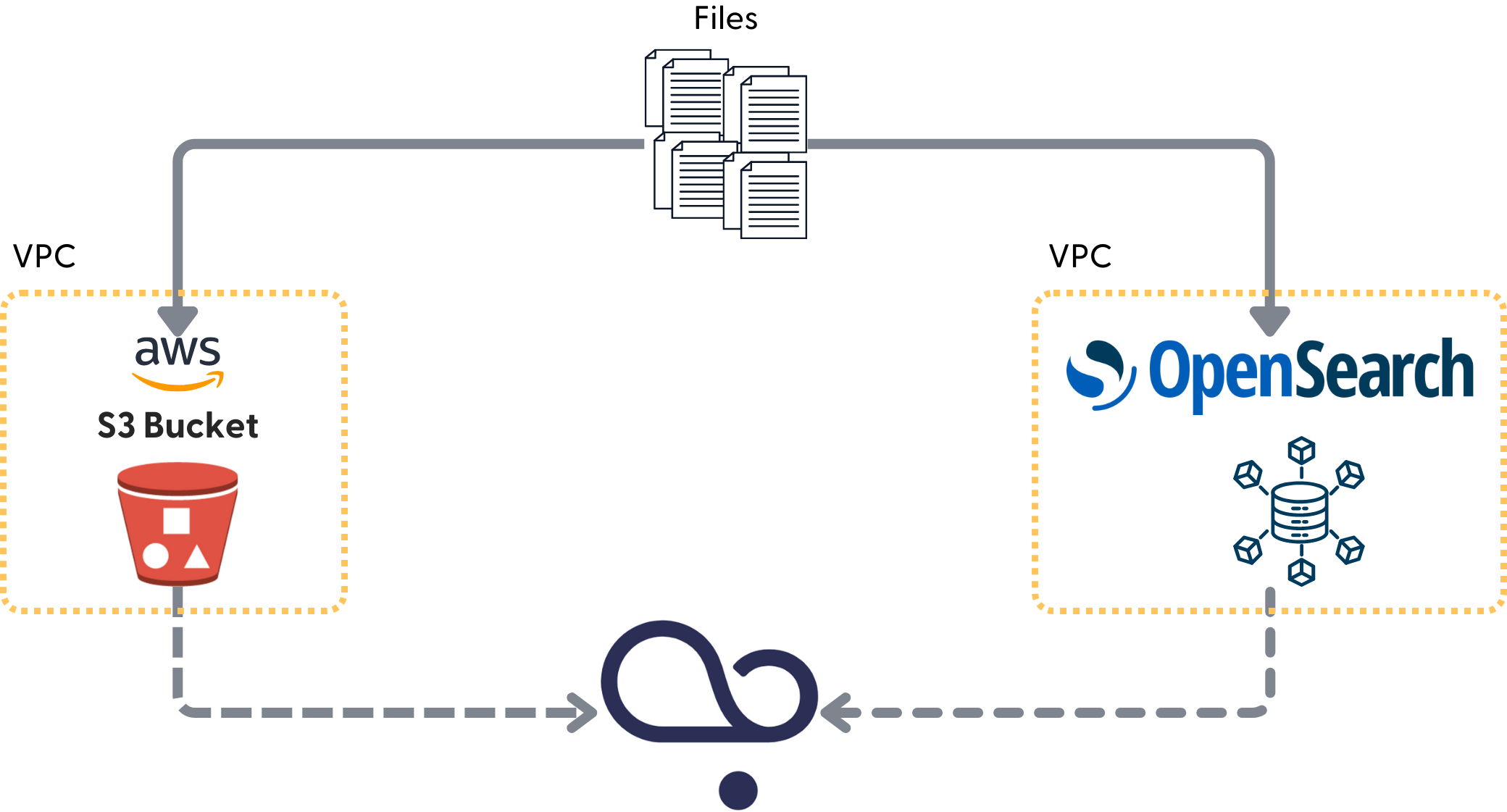
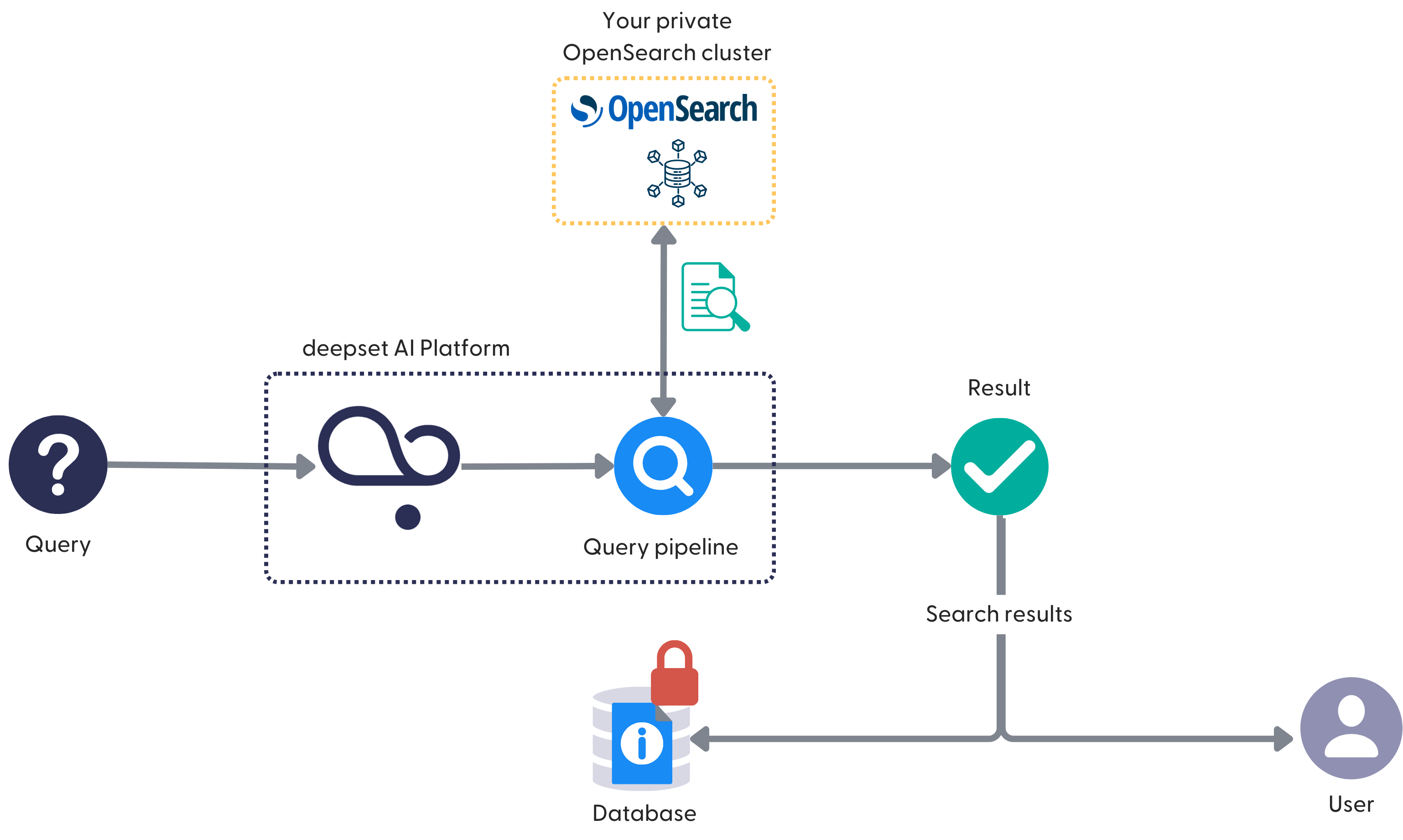
When you use your own VPC, like AWS S3 or OpenSearch, to store files, your files remain in your storage at all times. You authorize Haystack Platform to communicate with the file storage when it needs to index the files. We'll cover that in Deploying Pipelines in more detail.
Enabling Indexes
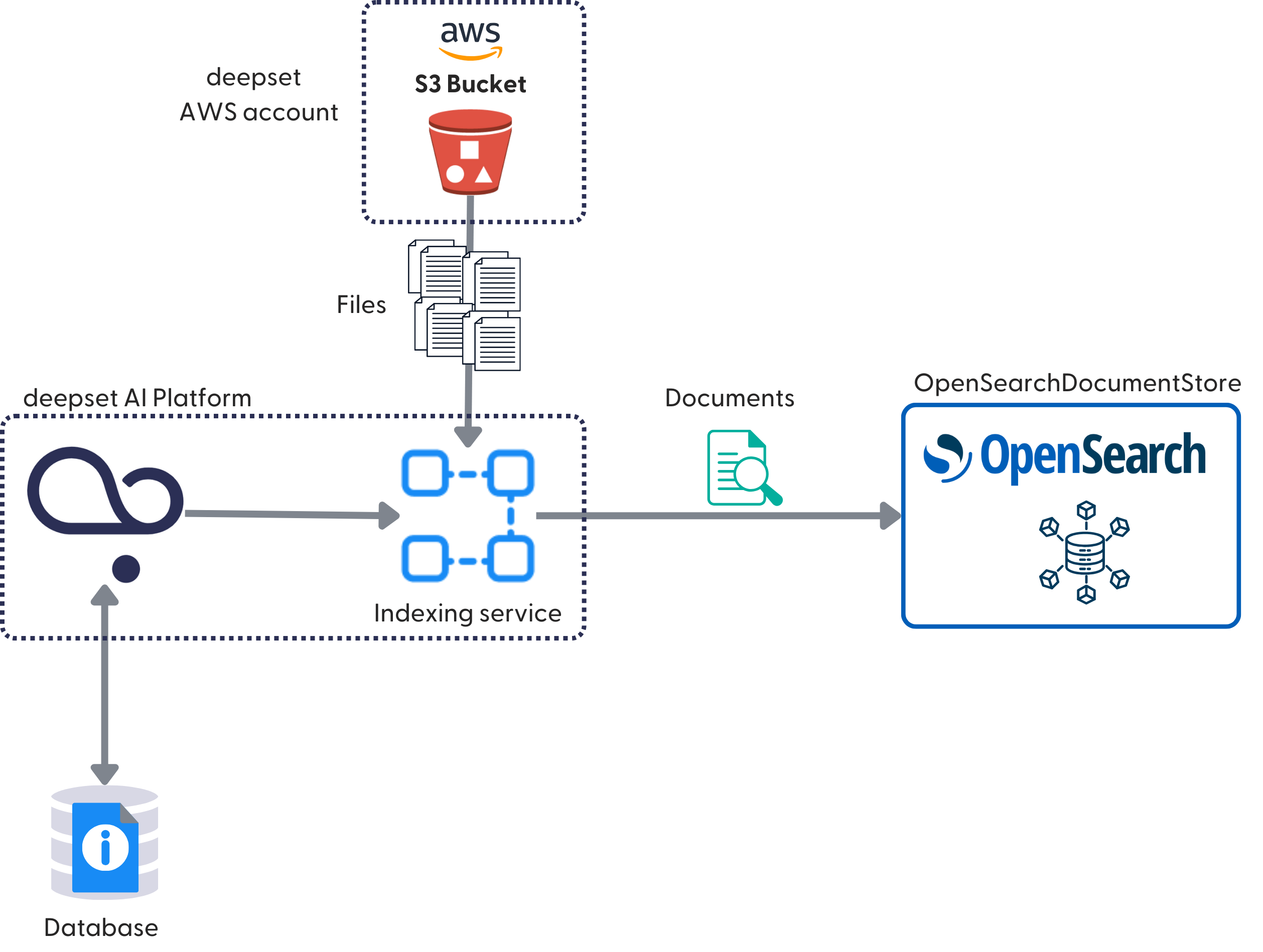
When you enable an index, it triggers indexing. Indexing means your files are preprocessed, chunked into pieces of raw text called Documents, and stored in the document store. OpenSearchDocumentStore is the default, core document store of Haystack Enterprise Platformm, but you can use any other supported database.
During indexing:
- product fetches the names of files to index from the database.
- It then communicates these file names to the index.
- The index fetches the actual files from the data storage and starts indexing. During indexing, the files are temporarily stored in the Haystack Platform indexing service.
- The index preprocesses the files and sends the resulting documents to the document store. After that, the files are deleted from the temporary location.
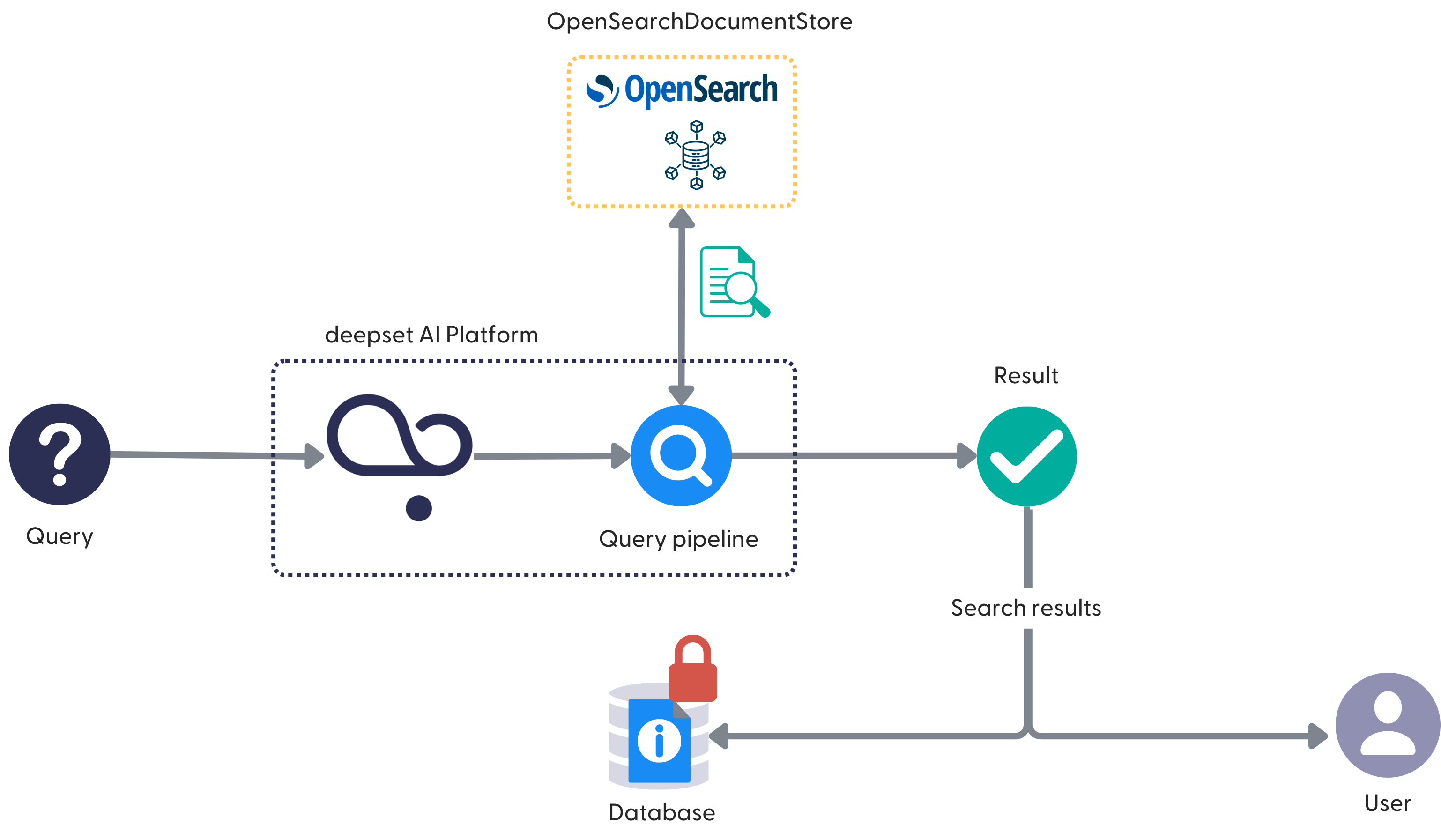
This graphic shows the flow using the example of OpenSearchDocumentStore:
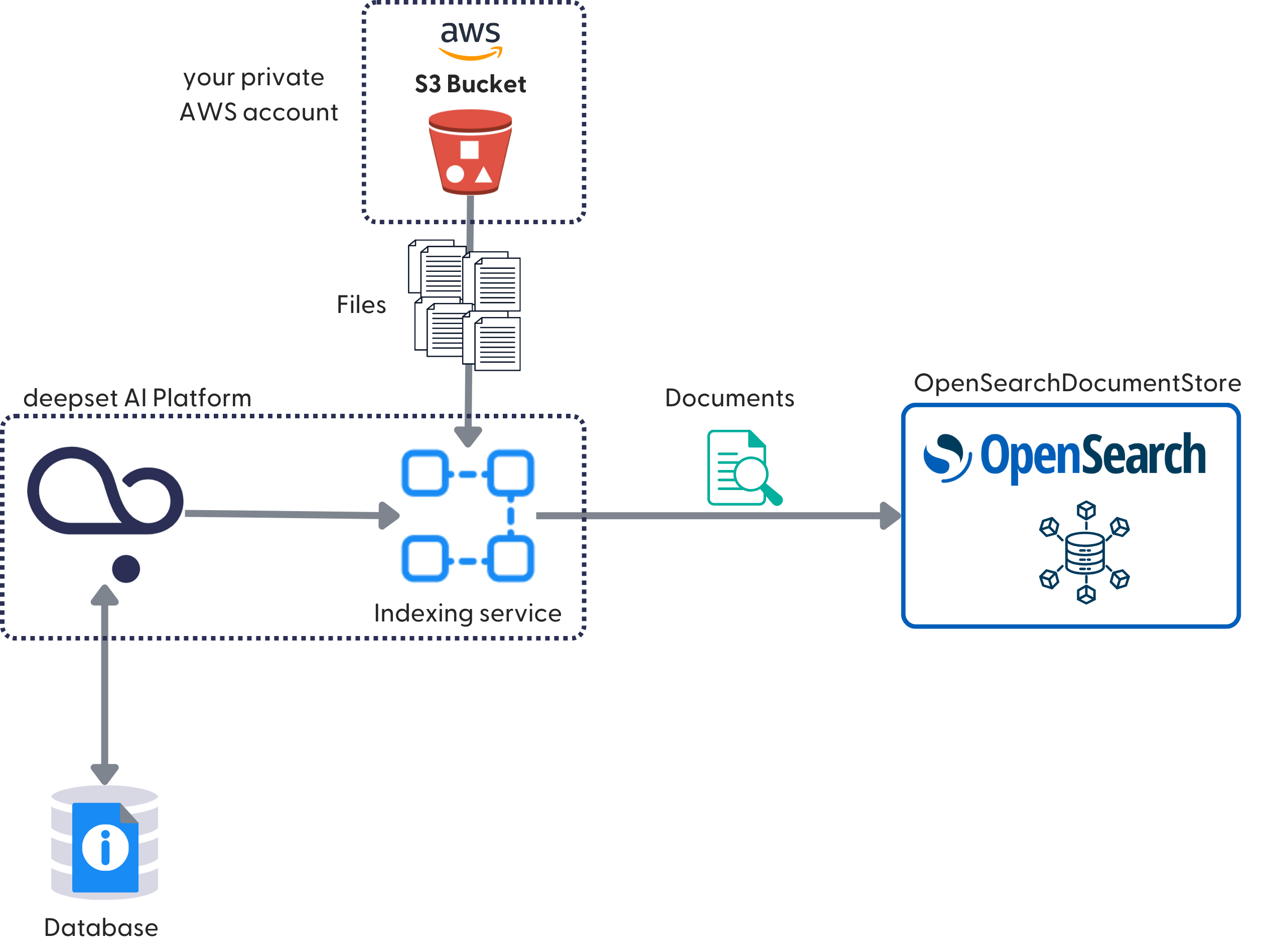
The process is the same regardless of whether you store your files in Haystack Platform or in a private AWS S3 bucket. If you want your data to stay in your accounts, we recommend connecting a private AWS S3 bucket and a private OpenSearch cluster. Otherwise, the documents, which are chunked files, are still stored in OpenSearch.
Searching
Let's examine what happens at search time. Your query goes to the query pipeline, which (more specifically, the Retriever node) connects with the OpenSearchDocumentStore and fetches the documents that match the query.
If you use your private OpenSearch cluster, you authorize Haystack Platform to connect to it at query time. The query pipeline then reaches out to your OpenSearch cluster to fetch the documents from there.
These documents are stored in a temporary memory, not saved anywhere. If it's a question answering pipeline, the Retriever passes the documents on to the Reader or Generator, which comes up with the final answer based on them.
The results of the query are stored in the Haystack Platform SQL database. The database is protected, and only a selected number of Haystack Platform employees can access it.
Using Hosted Models
You can use models hosted by OpenAI, Hugging Face, Cohere, Azure OpenAI, SageMaker, or Amazon Bedrock in your query pipelines. For a full list, see Using Hosted Models and External Services.
A hosted model is especially useful for large language models requiring substantial infrastructure.
To use a hosted model, you first connect to the model provider using your credentials. The encrypted credentials are securely stored in the database. When you make a query, Haystack Platform sends an HTTP request to the model provider, including your credentials in the request header. If the authorization is successful, the model generates the response and sends it back to Haystack Enterprise Platform.
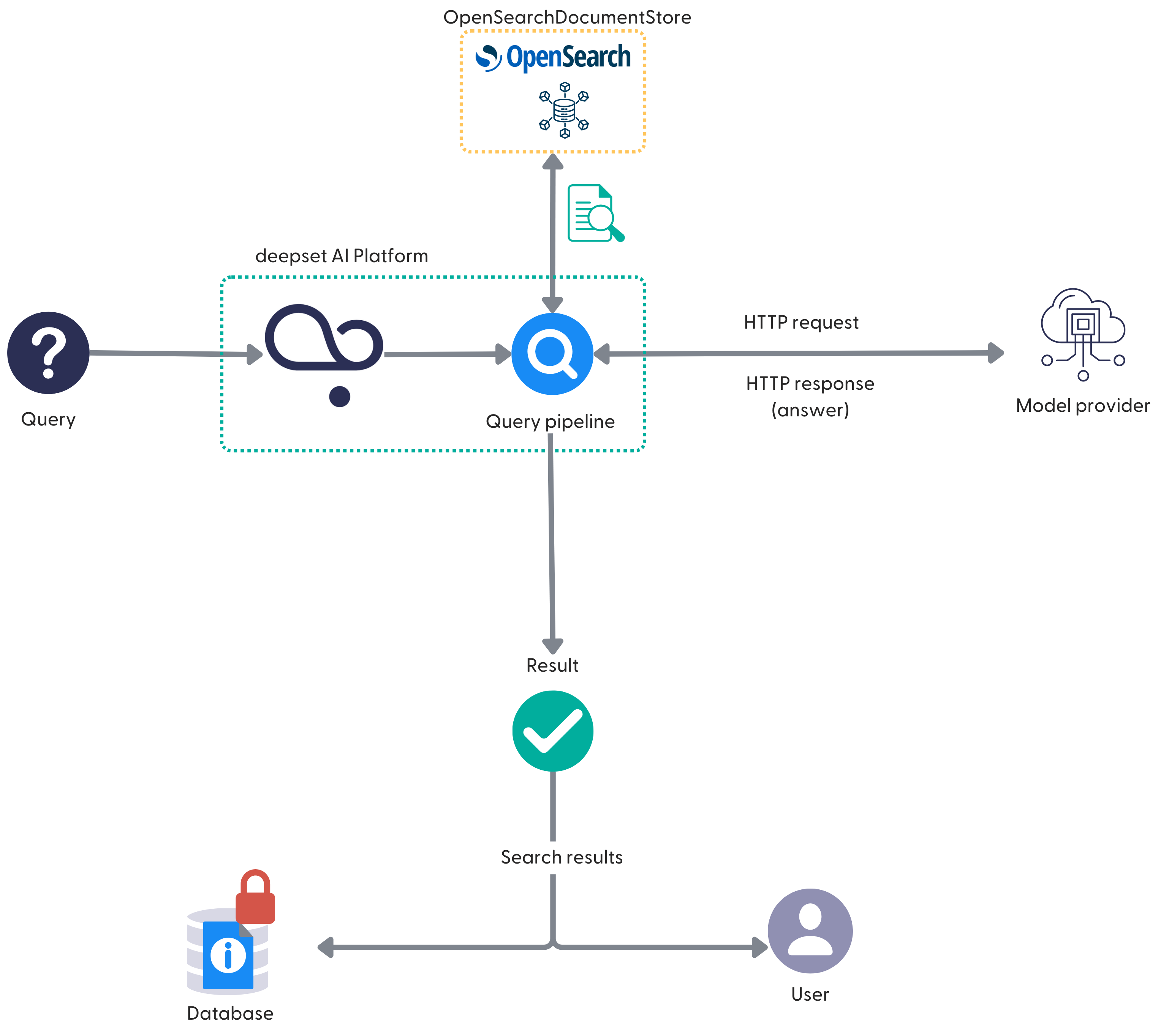
When using a hosted model, remember that your pipeline's stability depends on the model provider. If you disconnect Haystack Platform from a model provider, all pipelines using models hosted by this provider stop working.
Was this page helpful?