Pipelines
Pipelines are powerful and highly flexible systems that form the engine for your app. They consist of components that process your data and perform various tasks on it. Each component in a pipeline passes its output to the next component.
How Do Pipelines Work?
Pipelines are composed of connected components. Each component processes a piece of your data, such as documents, and performs specific tasks before passing the output to the next component. For example, a basic RAG pipeline may include:
- A
TextEmbedderthat takes the user query and turns it into a vector. - A
Retrieverthat receives the vector from theTextEmbedderand uses it to fetch relevant documents from the document store. - An
LLMthat injects the user query and the documents from theRetrieverinto the prompt and generates the response.
Components function like modular building blocks that you can mix, match, and replace to form various pipeline configurations, such as loops, branches, or simultaneous flows. When connecting the components, it's crucial to ensure the output type of one component matches the input type of the next. Each component receives only the data it needs, which speeds up the pipeline and makes it easier to debug.
Connection Types
Pipelines in Haystack Enterprise Platform are flexible and multifunctional. While you can still create simple pipelines performing one function, like answering queries, you can also use them to build complex workflows.
Smart Connections
Components connect when their input and output types are compatible. In most cases, the types must match. However, Haystack Platform pipelines also support smart connections for certain type combinations:
-
Listtypes: You can connect multiple lists of the same type to a component that accepts a list as input. For example, you can connect multipleConvertersthat produce lists of documents to aDocumentWriterthat accepts a list of documents as input. The pipeline combines the lists into a single list and passes it to the component. -
StringtoChatMessage: Astringautomatically converts to aChatMessagewith the user role. This is useful when you pass plain text to aChatPromptBuilderorChatGenerator. -
ChatMessagetostringor alist of stringsor alist of ChatMessage: This conversion makes it possible to connect aChatGeneratorto inputs such as the query parameter of aRetriever. -
List of stringto astringorChatMessage: Pipelines support connections between list of strings and components that accept a singlestringorChatMessage. For example, anOpenAIGenerator'srepliescan connect toOpenSearchHybridRetriever'squery. -
List of ChatMessageto a singleChatMessageorstring: The pipeline supports connections between lists of ChatMessages and components that accept a singleChatMessageorstring. For example,OpenAIChatGenerator'smessagescan connect toOpenSearchHybridRetriever'squery.
This table summarizes connections between input and output types enabled by smart connections:
| Sender Output Type | Receiver Input Type | What happens |
|---|---|---|
| List of Documents (multiple senders to same input) | List of Documents | Lists are merged into one. |
| List of ChatMessage (multiple senders to same input) | List of ChatMessage | Lists are merged into one. |
| List of strings (multiple senders to same input) | List of strings | Lists are merged into one. |
| string | ChatMessage | Converted to a ChatMessage with the user role. |
| ChatMessage | string | Content is extracted as a string. |
| List of ChatMessage | string or ChatMessage | First message is used (for example, as a query). |
| List of string | string or ChatMessage | First string is used. |
This table shows component-level connections for both list merging and type conversions:
| Sender | Receiver | What Happens |
|---|---|---|
| BM25 Retriever, Embedding Retriever output: documents | Rankers (for example, TransformersSimilarityRanker) input: documents | List merge |
| Ranker or multiple retrievers output: documents | PromptBuilder, AnswerBuilderinput: documents (if configured in the template) | List merge |
| Ranker or multiple retrievers output: documents | ChatPromptBuilder input: documents | List merge |
| Multiple converters output: documents | DocumentSplitter input: documents | List merge |
Multiple converters or DocumentSplitter output: documents | DocumentWriter input: documents | List merge |
Multiple converters or DocumentSplitter output: documents | Document Embedders (for example SentenceTransformersDocumentEmbedder) input: documents | List merge |
ChatPromptBuilder output: prompt DeepsetChatHistoryParser output: messages | Agent input: messages | List merge |
| Generator, ChatGenerator output: replies | Retriever, Ranker, AnswerBuilder input: query PromptBuilder input: question | List of ChatMessages converted to string |
ChatGenerator output: replies | AnswerBuilder input: replies | Type conversion |
Agent output: last_message | SentenceTransformersTextEmbedder input: text Retriever input: query | Type conversion |
Smart connections make many "glue" components like DocumentJoiner, ListJoiner, and OutputAdapter unnecessary. To learn how to update your existing pipelines, see Simplify Your Pipelines with Smart Connections.
Connection Validation
When you connect components in a pipeline, it validates that their outputs and inputs match and, if needed, produces detailed errors. In Builder, these validation errors appear in the Issues panel at the bottom of the canvas. Click Inspect next to an issue to jump directly to the incompatible connection or misconfigured component. Click Fix with AI to open the AI assistant, which reasons through the fix and can apply it for you.
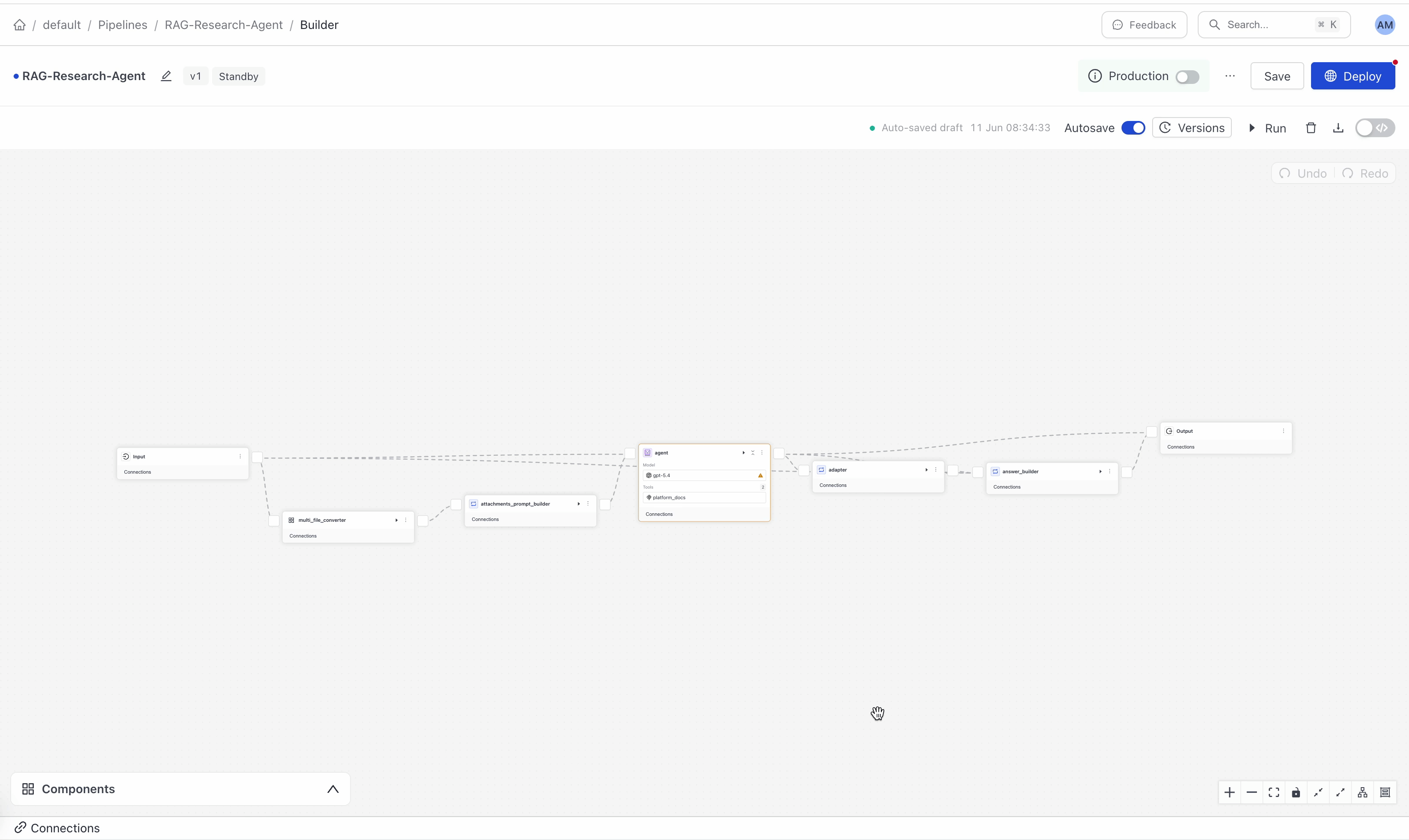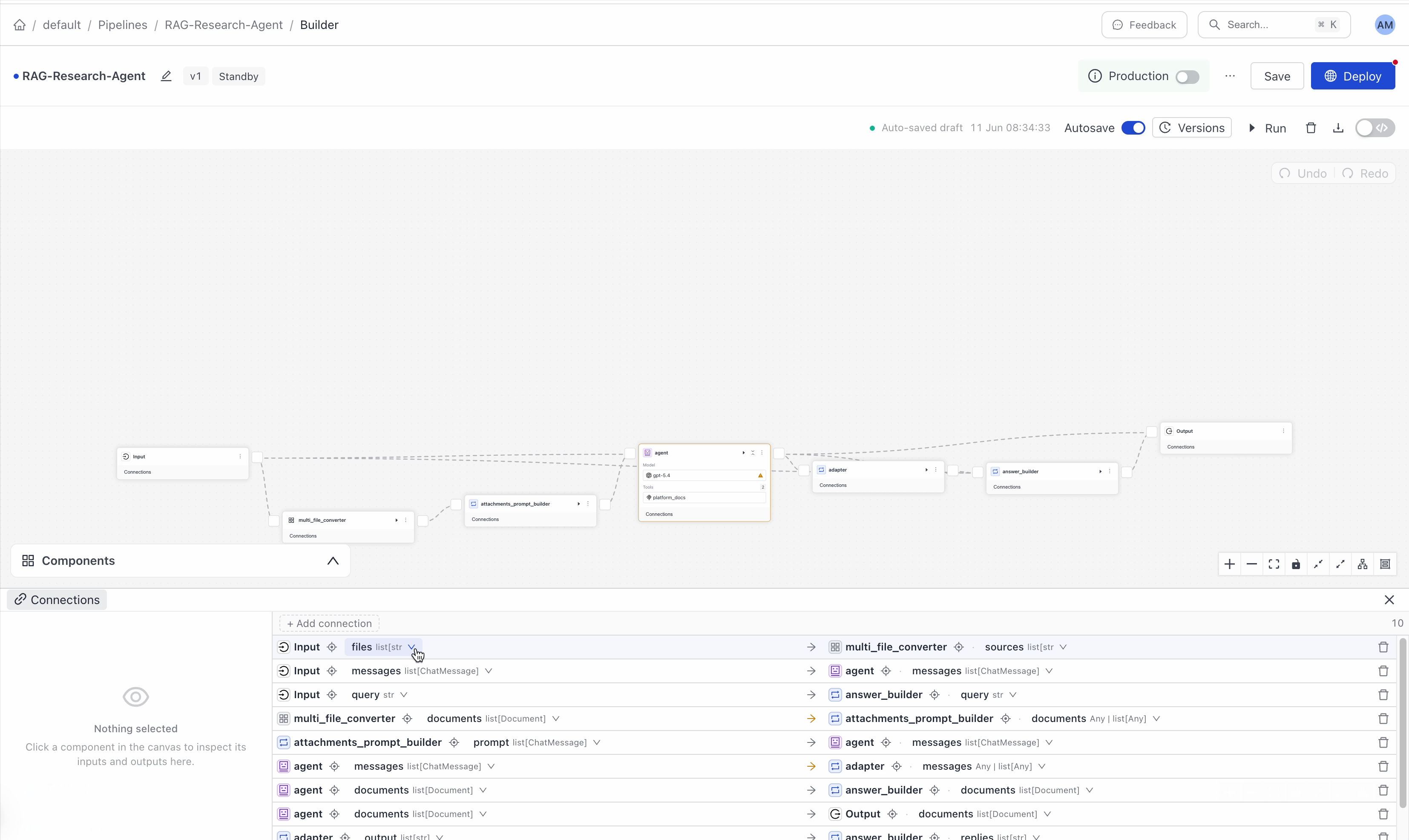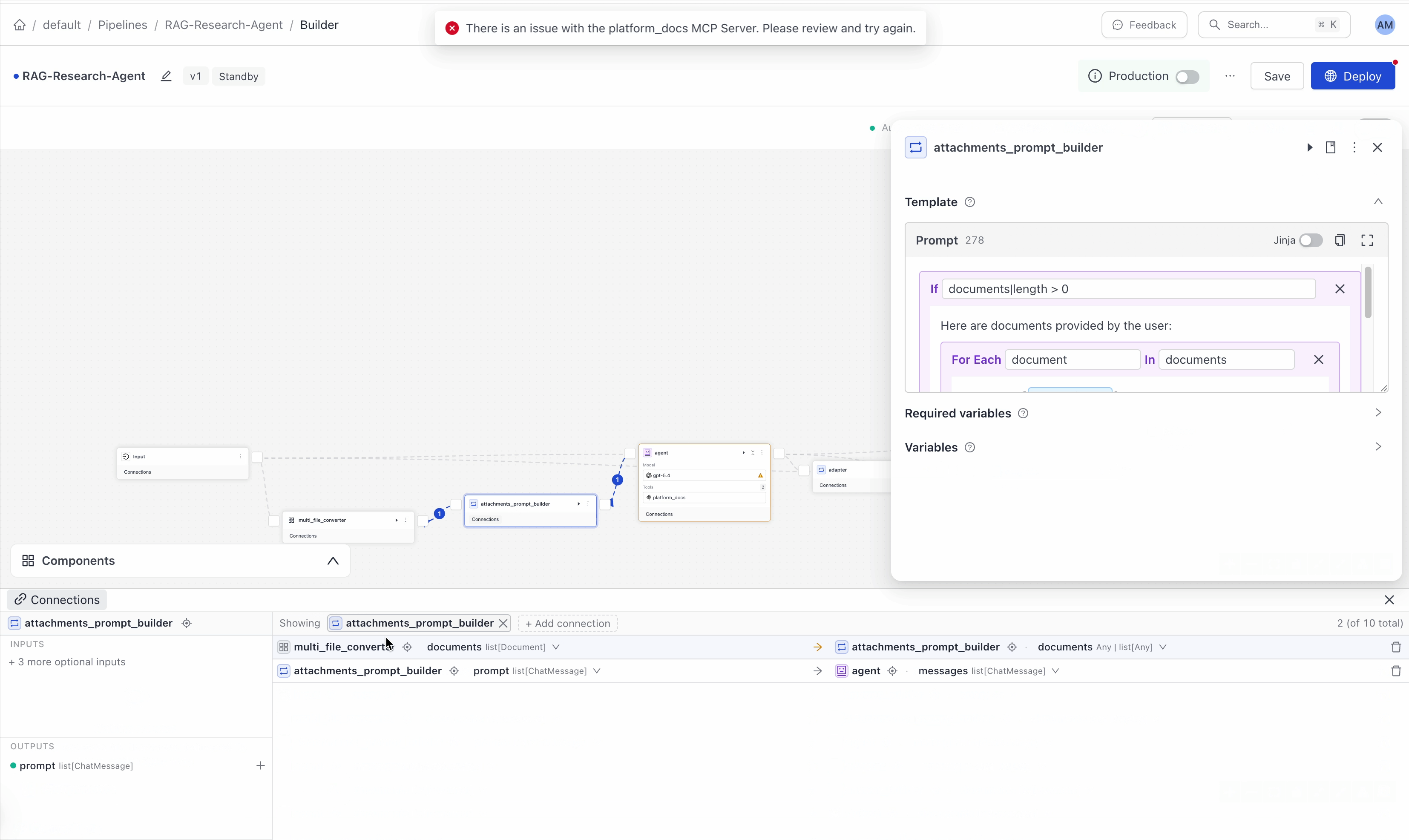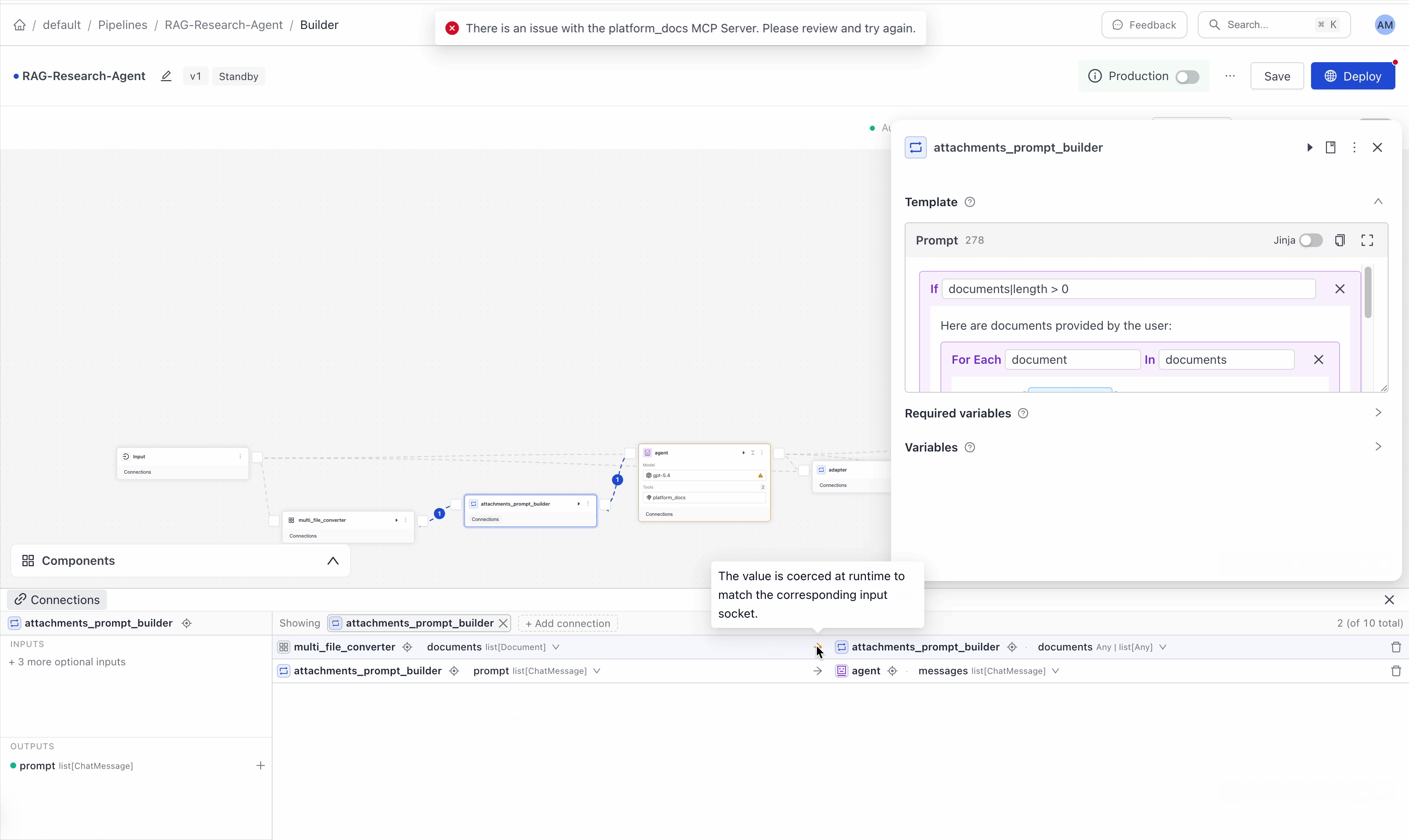
You can manage all your connections in the Connections panel at the bottom of the canvas.
Branches
Pipelines can branch to process data simultaneously. For example, each pipeline branch can have a different converter, each dedicated to a specific file type, allowing for efficient parallel processing.
Loops
In loops, components operate iteratively, with a set limit on repetitions. This is useful in scenarios such as self-correcting loops, where a validator component checks the generator's output and potentially cycles it back for correction until it meets the quality standard and can be sent further down the pipeline.
How Do Pipelines Use Your Files?
Pipelines run on the documents produced by the indexes they're connected to. An index preprocesses the files from a Haystack Platform workspace, converts them into documents, and writes them into a document store where a pipeline can access them. A single pipeline can be connected to multiple indexes. For details, see Indexes.
One file may produce multiple documents. Documents inherit metadata from files. Your indexing pipeline defines the exact steps for preprocessing the files.
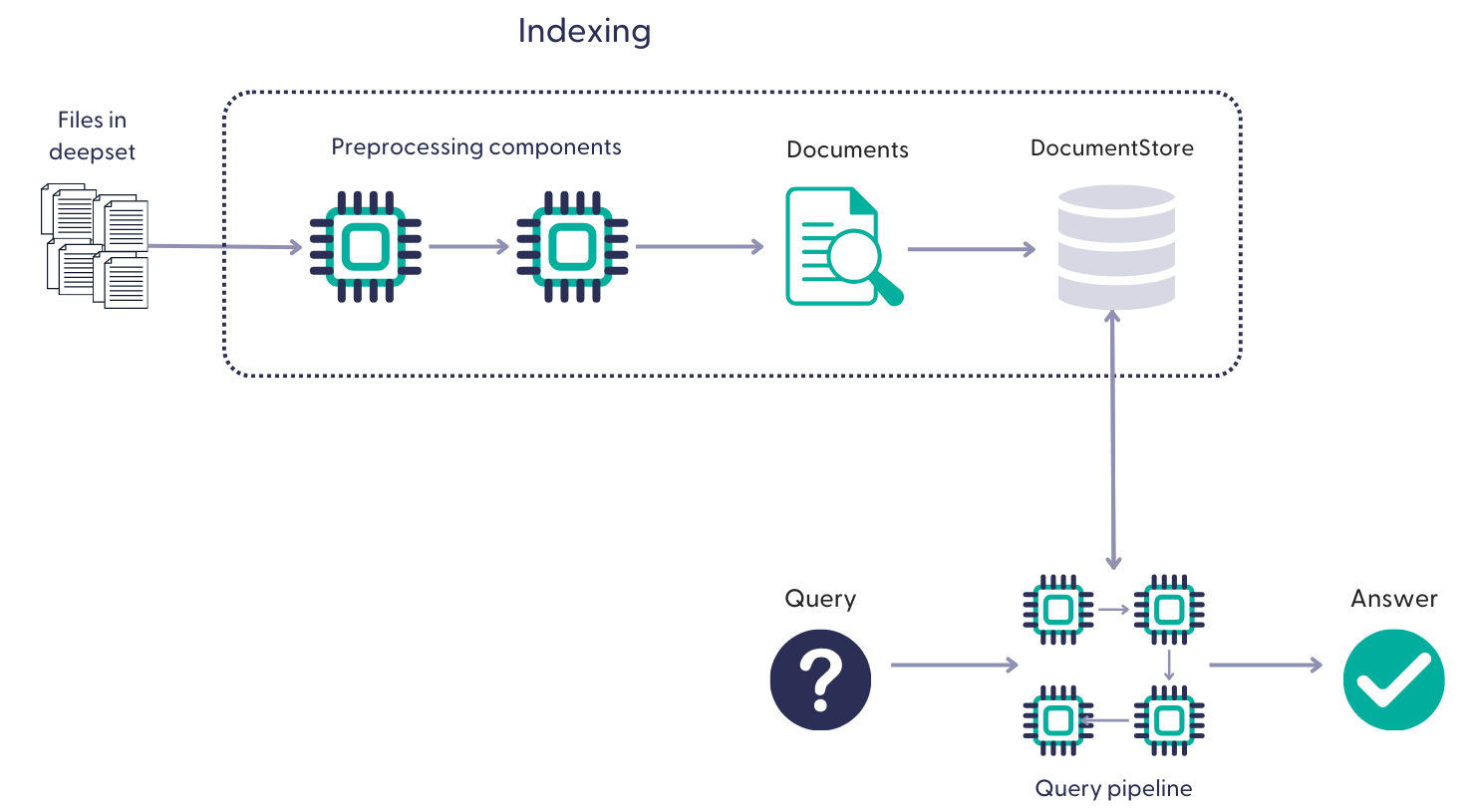
Building Pipelines
Pipelines contain recipes for how to execute a query. Pipelines can perform different tasks, such as querying, summarizing, or arriving at an answer after a series of steps involving tool calling.
This is an example of a RAG pipeline that runs on your files in Haystack Platform, receives the user query, retrieves the relevant documents, and processes them through the components to arrive at an answer:
Example of a pipeline
# haystack-pipeline
components:
retriever:
# Selects the most similar documents from the document store
type: haystack_integrations.components.retrievers.opensearch.open_search_hybrid_retriever.OpenSearchHybridRetriever
init_parameters:
document_store:
type: haystack_integrations.document_stores.opensearch.document_store.OpenSearchDocumentStore
init_parameters:
embedding_dim: 768
hosts:
index: Standard-Index-English-EU-Demo-Schengen
max_chunk_bytes: 104857600
return_embedding: false
method:
mappings:
settings:
index.knn: true
create_index: true
http_auth:
use_ssl:
verify_certs:
timeout:
top_k: 20 # The number of results to return
fuzziness: 0
embedder:
type: deepset_cloud_custom_nodes.embedders.nvidia.text_embedder.DeepsetNvidiaTextEmbedder
init_parameters:
normalize_embeddings: true
model: intfloat/e5-base-v2
ranker:
type: deepset_cloud_custom_nodes.rankers.nvidia.ranker.DeepsetNvidiaRanker
init_parameters:
model: intfloat/simlm-msmarco-reranker
top_k: 8
meta_field_grouping_ranker:
type: haystack.components.rankers.meta_field_grouping_ranker.MetaFieldGroupingRanker
init_parameters:
group_by: file_id
subgroup_by:
sort_docs_by: split_id
llm:
type: haystack.components.generators.chat.llm.LLM
init_parameters:
# You can swap this for any other model. Switch to the Builder view and choose another model from the list on the component card.
chat_generator:
type: haystack.components.generators.chat.openai_responses.OpenAIResponsesChatGenerator
init_parameters:
model: "gpt-5.4"
user_prompt: >-
{% message role="user" %}
You are a technical expert.
You answer questions truthfully based on provided documents.
Ignore typing errors in the question.
For each document check whether it is related to the question.
Only use documents that are related to the question to answer it.
Ignore documents that are not related to the question.
If the answer exists in several documents, summarize them.
Only answer based on the documents provided. Don't make things up.
Just output the structured, informative and precise answer and nothing
else.
If the documents can't answer the question, say so.
Always use references in the form [NUMBER OF DOCUMENT] when using
information from a document, e.g. [3] for Document [3] .
Never name the documents, only enter a number in square brackets as a
reference.
The reference must only refer to the number that comes in square
brackets after the document.
Otherwise, do not use brackets in your answer and reference ONLY the
number of the document without mentioning the word document.
These are the documents:
{%- if documents|length > 0 %}
{% for document in documents %}
Document [{{ loop.index }}] :
Name of Source File: {{ document.meta.file_name }}
{{ document.content }}
{% endfor %}
{%- else %}
No relevant documents found.
Respond with "Sorry, no matching documents were found, please adjust the
filters or try a different question."
{% endif %}
Question: {{ question }}
Answer:
{% endmessage %}
required_variables: "*"
system_prompt: ""
attachments_joiner:
type: haystack.components.joiners.document_joiner.DocumentJoiner
init_parameters:
join_mode: concatenate
weights:
top_k:
sort_by_score: true
multi_file_converter:
type: haystack.core.super_component.super_component.SuperComponent
init_parameters:
input_mapping:
sources:
- file_classifier.sources
is_pipeline_async: false
output_mapping:
score_adder.output: documents
pipeline:
components:
file_classifier:
type: haystack.components.routers.file_type_router.FileTypeRouter
init_parameters:
mime_types:
- text/plain
- application/pdf
- text/markdown
- text/html
- application/vnd.openxmlformats-officedocument.wordprocessingml.document
- application/vnd.openxmlformats-officedocument.presentationml.presentation
- application/vnd.openxmlformats-officedocument.spreadsheetml.sheet
- text/csv
text_converter:
type: haystack.components.converters.txt.TextFileToDocument
init_parameters:
encoding: utf-8
pdf_converter:
type: haystack.components.converters.pdfminer.PDFMinerToDocument
init_parameters:
line_overlap: 0.5
char_margin: 2
line_margin: 0.5
word_margin: 0.1
boxes_flow: 0.5
detect_vertical: true
all_texts: false
store_full_path: false
markdown_converter:
type: haystack.components.converters.txt.TextFileToDocument
init_parameters:
encoding: utf-8
html_converter:
type: haystack.components.converters.html.HTMLToDocument
init_parameters:
extraction_kwargs:
output_format: markdown
target_language:
include_tables: true
include_links: true
docx_converter:
type: haystack.components.converters.docx.DOCXToDocument
init_parameters:
link_format: markdown
pptx_converter:
type: haystack.components.converters.pptx.PPTXToDocument
init_parameters: {}
xlsx_converter:
type: haystack.components.converters.xlsx.XLSXToDocument
init_parameters: {}
csv_converter:
type: haystack.components.converters.csv.CSVToDocument
init_parameters:
encoding: utf-8
splitter:
type: haystack.components.preprocessors.document_splitter.DocumentSplitter
init_parameters:
split_by: word
split_length: 250
split_overlap: 30
respect_sentence_boundary: true
language: en
score_adder:
type: haystack.components.converters.output_adapter.OutputAdapter
init_parameters:
template: |
{%- set scored_documents = [] -%}
{%- for document in documents -%}
{%- set doc_dict = document.to_dict() -%}
{%- set _ = doc_dict.update({'score': 100.0}) -%}
{%- set scored_doc = document.from_dict(doc_dict) -%}
{%- set _ = scored_documents.append(scored_doc) -%}
{%- endfor -%}
{{ scored_documents }}
output_type: List[haystack.Document]
custom_filters:
unsafe: true
tabular_joiner:
type: haystack.components.joiners.document_joiner.DocumentJoiner
init_parameters:
join_mode: concatenate
sort_by_score: false
connections:
- sender: file_classifier.text/plain
receiver: text_converter.sources
- sender: file_classifier.application/pdf
receiver: pdf_converter.sources
- sender: file_classifier.text/markdown
receiver: markdown_converter.sources
- sender: file_classifier.text/html
receiver: html_converter.sources
- sender: file_classifier.application/vnd.openxmlformats-officedocument.wordprocessingml.document
receiver: docx_converter.sources
- sender: file_classifier.application/vnd.openxmlformats-officedocument.presentationml.presentation
receiver: pptx_converter.sources
- sender: file_classifier.application/vnd.openxmlformats-officedocument.spreadsheetml.sheet
receiver: xlsx_converter.sources
- sender: file_classifier.text/csv
receiver: csv_converter.sources
- sender: text_converter.documents
receiver: splitter.documents
- sender: pdf_converter.documents
receiver: splitter.documents
- sender: markdown_converter.documents
receiver: splitter.documents
- sender: html_converter.documents
receiver: splitter.documents
- sender: pptx_converter.documents
receiver: splitter.documents
- sender: docx_converter.documents
receiver: splitter.documents
- sender: xlsx_converter.documents
receiver: tabular_joiner.documents
- sender: csv_converter.documents
receiver: tabular_joiner.documents
- sender: splitter.documents
receiver: tabular_joiner.documents
- sender: tabular_joiner.documents
receiver: score_adder.documents
connections:
- sender: retriever.documents
receiver: ranker.documents
- sender: ranker.documents
receiver: meta_field_grouping_ranker.documents
- sender: multi_file_converter.documents
receiver: attachments_joiner.documents
- sender: meta_field_grouping_ranker.documents
receiver: attachments_joiner.documents
- sender: attachments_joiner.documents
receiver: llm.documents
inputs:
query:
- retriever.query
- ranker.query
- llm.question
filters:
- retriever.filters_bm25
- retriever.filters_embedding
files:
- multi_file_converter.sources
outputs:
documents: attachments_joiner.documents
messages: llm.messages
max_runs_per_component: 100
metadata: {}
Inputs
Pipelines always take Input as the first component. When working in Builder, click Add to open the component library and drag Input onto the canvas and then connect it to the components that should receive its outputs.
When working in YAML editor, you must explicitly specify the inputs and the components that receive them:
inputs: # Define the inputs for your pipeline
query: # These components will receive the query as input
- "bm25_retriever.query"
- "query_embedder.text"
- "ranker.query"
filters: # These components will receive a potential query filter as input
- "bm25_retriever.filters"
- "embedding_retriever.filters"
Filters are documents' metadata keys by default. This means that if your documents have the following metadata: {"category": "news"}, when searching in Playground, users can narrow down the search to the documents matching this category. You can also pass filters at search time with the Search endpoint. For more information about filters, see Working with Metadata.
Outputs
The output of pipelines matches the output of the last component. However, it must be one of the following data classes:
- List of
Documentobjects (usually document search pipelines) - List of
Answerobjects, including the following subclasses:- List of
ExtractedAnswerobjects (usually extractive question answering pipelines) - List of
GeneratedAnswerobjects (pipelines that use Generator components)
- List of
- List of
ChatMessageobjects (usually pipelines that use large language models to generate answers)
The output can be a list of documents, a list of answers, a list of chat messages, or all of them. Ensure the last component in your pipeline produces at least one of these outputs.
In Builder, to finalize the pipeline with the correct output, drag the Output component onto the canvas and connect it to the components that produce the outputs you want to include.
When working in the YAML editor, you must explicitly specify the outputs and the components that provide them:
outputs: # Defines the output of your pipeline
documents: "ranker.documents" # The output of the pipeline is the retrieved documents
messages: "llm.messages" # The output of the pipeline is the generated answers
Pipeline Service Levels
To save costs and meet your infrastructure and service requirements, your pipelines are assigned service levels. There are three service levels available:
- Draft: This is a service level automatically assigned to new and undeployed pipelines, so that you can easily distinguish them from the deployed ones.
- Development: Pipelines at this level are designed for testing and running experiments. They have no replicas by default, and their time to standby is short, so they can save resources whenever these pipelines aren't used. When you deploy a draft pipeline, it becomes a development pipeline.
- Production: This level is recommended for business-critical scenarios where you need the pipeline to be scalable and reliable. Pipelines at this level include one replica by default and a longer time-to-standby period than other service levels. With heavy traffic, the number of replicas grows up to 10.
This table gives an overview of the default settings that come with each service level:
| Service level | Description | Idle Timeout | Scaling (replicas) | How to enable |
|---|---|---|---|---|
| Production | Designed for critical business scenarios that require reliable and scalable pipelines. | 24 hours | 1 at all times, scales up to 10 if traffic is heavy | - In Haystack Enterprise Platform, on the Pipelines page - Through the Update Pipeline REST API endpoint |
| Development | Designed for testing and experimenting purposes. | 20 minutes | 0 | - By switching off the Production service level for a deployed production pipeline in Haystack Enterprise Platform - Through the Update Pipeline REST API endpoint- By deploying a draft pipeline |
| Draft | Indicates an undeployed pipeline. | n/a | 0 | - By undeploying a production or development pipeline - All new pipelines are automatically classified as drafts |
Idle timeout is the time after which an unused pipeline enters a standby mode to save resources. Inactive pipelines don't use up the pipeline hours included in your plan. You can customize the idle timeout for each pipeline in the pipeline's Settings tab or through the Update Pipeline REST API endpoint. The maximum idle timeout is 30 days.
To use a pipeline on standby, activate it either on the Pipelines page or by initiating a search using that pipeline.
Replicas are the number of duplicate versions of a pipeline that are available. In case there is a spike in demand, Haystack Platform seamlessly switches to a functioning replica to maintain uninterrupted service. You can configure the minimum and maximum number of replicas in the pipeline's Settings tab or through the Update Pipeline REST API endpoint. The maximum number of replicas is 10.
You can change the service level of your pipeline at any time. For details, see Change the Pipeline's Service Level.
Managing Pipelines
All the pipelines created in a workspace are listed on the Pipelines page, where you can view and manage them. Click a pipeline to open it and navigate to the different sections.
Build
When you click a pipeline name, you land in Builder. You can use Builder to build and test your pipeline. For details, see Creating a pipeline.
Playground
This is where you can test your pipeline. You can type a query and see the results. You can also upload files and test your pipeline with them. For details, see Testing your pipeline.
Analytics
Analytics is where you can check all the information about your pipeline, including pipeline logs, traces, and search history. You can check the following information about the pipeline:
- Pipeline overview, including query volume, feedback distribution, and response times.
- Traces
- History
- Logs
Overview
The overview shows the a KPI dashboard with key performance metrics in an easy-to-read format:
- Total queries: Total number of queries your pipeline processed. This metric helps you understand usage patterns and traffic volume.
- Documents: Total number of documents indexed for this pipeline.
- Feedback coverage: Percentage of queries that received user feedback. Higher feedback coverage gives you better insights into pipeline performance. If this shows "N/A", it means no feedback was given yet.
- Average response time: Average time it took to generate a response. Monitor this metric to identify performance issues or improvements after configuration changes.
- Minimum inference time: The fastest response time recorded across all queries. This helps you understand your pipeline's best case performance.
- Maximum inference time: The slowest response time recorded across all queries. Use this metric to identify potential performance bottlenecks or outliers.
- Query volume: Number of queries your pipeline processed over the last 7 days.
- Feedback distribution: Distribution of feedback received for the pipeline's responses.
- Query Activity Heatmap: Shows when your pipeline is most active by displaying query volume across hours and days. This helps you understand usage patterns, identify peak activity period, or plan maintenance windows.
From the overview section, you can click Playground to quickly test the pipeline.
Traces
Traces are collected for queries run on or after 25 June 2026. Before that date, traces are not available. To collect traces for pipelines deployed before that date, undeploy the pipeline and deploy it again.
A trace represents the full journey of a single request as it moves through the pipeline, captured automatically with no setup required. Use traces to review your pipeline runs and debug performance issues or unexpected behavior in multi-step pipelines. Each row in the trace table represents a single pipeline run, with its input, status, source (Playground, Builder, API, or a shared prototype), latency, and total tokens used.
You can filter the traces to easily find failed runs, runs that took too long, or runs that were run at a specific time, and search by trace ID or input text. You can also navigate from a trace to the search history for that run by clicking More Actions > View in Search History next to a trace.
Clicking a trace opens its details, where you can check the status of the run, where it was run, components that failed, duration, and more. When a run fails, the trace flags the root-cause component and shows whether it's a configuration error or an external provider or infrastructure issue. You can view spans within a trace and related logs. Click a span to select it and view its details, or click Run in Builder to reproduce that component's exact input and debug it. You can also compare two traces side by side to see how a pipeline change affected latency, token usage, and the answer itself.
A span is one step within a trace. It represents a single unit of work, like "call the retriever" or "generate the answer". Each span has its own start and end time, and attributes, like input and output, token counts, or errors. Spans can be nested. A parent span (the overall request) might contain child spans for each sub-step, so you end up with a tree-like structure showing what happened at each step and how the steps relate to each other.
Search History
The Search History tab shows the queries run with this pipeline and their results, including all the details. You can customize the Search History table columns to show the information you need or apply filters to narrow down the results. Any filters you apply are automatically synced with the URL, so you can easily share the filtered view with others by just sharing the URL.
You can also export the entire search history as a CSV file for a specific time period. This is useful for analyzing the performance of your pipeline over time.
Use AI-powered Feedback Insights to analyze feedback patterns and generate executive summaries to help you understand performance trends and identify areas for improvement. Expand the Feedback Insights panel to see the insights. You can start with one of the suggested prompts or enter your own query. Based on the prompt, AI analyzes your pipeline activity and generates a summary.
Smart Filters show the analysis of the last 100 queries to surface any anomalies or patterns that might require attention. Use them to check if your pipeline is following patterns worth investigating.
To inspect a specific query, click More Actions > Details in the query row. This opens a detailed view of the query, including the query text, the answer, the feedback, the timestamp, and the metadata. You can also see the conversation history for the query.
You can group queries by hashtags and add notes to individual queries to help you keep track of important information. Both notes and hashtags are searchable. You can view and manage them if you enable the Notes and Hashtags columns in the Search History table. To do this:
- On the Pipeline Details page, click Search History.
- Click Manage table preferences.
- Choose to display the Note and Hashtags columns. You can then add notes and hashtags to your queries using these columns in the table.
Logs
Use the logs to troubleshoot issues with your pipeline. You can filter the logs by message and pipeline type or date added. You can also search for keywords in log messages.
Settings
The Settings tab is where you can check your pipeline ID and configure its settings, such as MCP tools, GPU acceleration, pipeline scaling, and idle timeout.
MCP Tool
Use this section to expose your pipeline as an MCP tool to AI coding assistants like Cursor, Claude Code, and GitHub Copilot. For details, see Use Your Pipelines as MCP Tools.
GPU Settings
Pipelines use CPU by default. Turn on GPU support on the Settings tab when your pipeline includes components that run better on a GPU, such as embedders, generators, or custom components that use AI models.
When GPU support is on, the pipeline checks whether a component needs a GPU and assigns one automatically. GPUs are only used when required and are not reserved for the entire pipeline run.
If GPU support is off and your pipeline includes components that rely on a GPU, those components run on the CPU instead. This can slow down processing and may cause timeouts, especially for larger or more complex pipelines.
For detailed instructions, see Enable GPU Acceleration.
Pipeline Scaling
To increase availability, set the number of replicas allocated to a pipeline. Haystack Platform automatically scales replicas up or down based on traffic, and depending on the maximum and minimum number of replicas you set.
For production pipelines, set at least two replicas. This setup helps keep your pipeline available if one replica fails.
Adding more replicas can increase your costs.
Idle Timeout
Set the idle timeout to define how long a pipeline can remain inactive before it enters standby mode. When a pipeline becomes idle, Haystack Platform scales its replicas down to zero.
Idle pipelines do not consume the pipeline hours included in your plan. For example, if you set the idle timeout to 12 hours, the pipeline enters standby mode after 12 hours of inactivity.
This setting is useful for saving costs when you don't need your pipeline to be always available.
Feedback Tags
Add tags that users can select when giving feedback on the pipeline's responses. This helps you group feedback and analyze it. For details, see Collect Feedback.
Related Information
Was this page helpful?