Common Component Combinations
Let's look at examples of components that often go together to understand how they work.
PromptBuilder and Generator
Generators are components designed to interact with large language models (LLMs). Any LLM app requires a Generator component specific to the model provider used.
Generator needs a prompt as input, which is created using PromptBuilder. With PromptBuilder, you can define your prompt as a Jinja2 template. PromptBuilder processes the template, fills in the variables, and sends it to the Generator.
To connect these components, link the prompt output of PromptBuilder to the prompt input of the Generator, as shown below:
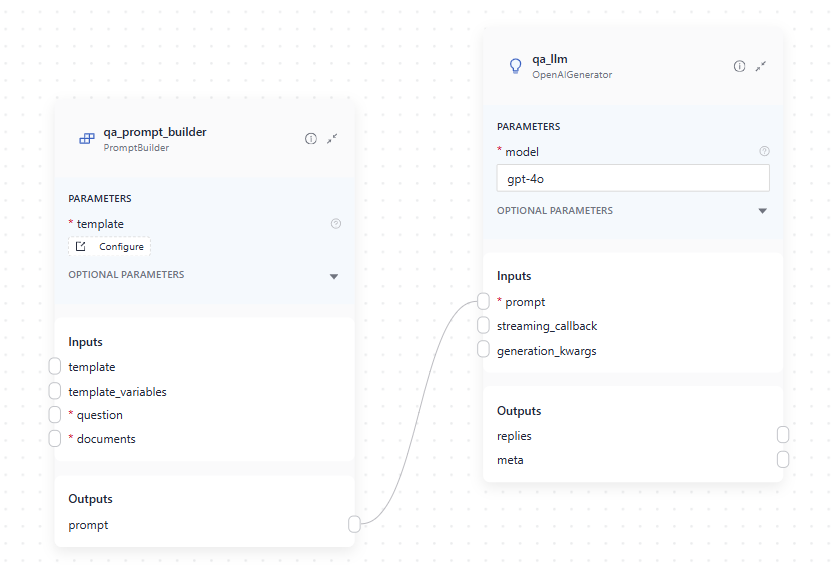
Example YAML configuration:
components:
qa_prompt_builder:
type: haystack.components.builders.prompt_builder.PromptBuilder
init_parameters:
template: |-
You are a technical expert.
You answer questions truthfully based on provided documents.
Ignore typing errors in the question.
For each document check whether it is related to the question.
Only use documents that are related to the question to answer it.
Ignore documents that are not related to the question.
If the answer exists in several documents, summarize them.
Only answer based on the documents provided. Don't make things up.
Just output the structured, informative and precise answer and nothing else.
If the documents can't answer the question, say so.
Always use references in the form [NUMBER OF DOCUMENT] when using information from a document, e.g. [3] for Document[3].
Never name the documents, only enter a number in square brackets as a reference.
The reference must only refer to the number that comes in square brackets after the document.
Otherwise, do not use brackets in your answer and reference ONLY the number of the document without mentioning the word document.
These are the documents:
{% for document in documents %}
Document[{{ loop.index }}]:
{{ document.content }}
{% endfor %}
Question: {{ question }}
Answer:
qa_llm:
type: haystack.components.generators.openai.OpenAIGenerator
init_parameters:
api_key: {"type": "env_var", "env_vars": ["OPENAI_API_KEY"], "strict": False}
model: "gpt-4o"
generation_kwargs:
max_tokens: 650
temperature: 0.0
seed: 0
connections:
- sender: qa_prompt_builder.prompt
receiver: qa_llm.prompt
ChatPromptBuilder and ChatGenerator
ChatGenerators are a type of Generators designed to work with chat LLMs in conversational scenarios. They receive the rendered prompt from a ChatPromptBuilder. The prompt for ChatGenerators is a list of ChatMessage objects, which means it follows a strict format:
- _content: # this is the beginning of the first ChatMessage
- content_type: content # this is the message content, it can be text, tool call or a tool call result. You can add variables to the content, just like in PromptBuilder.
_role: role # this specifies who sends this content, available roles are: system, tool, user, assistant
This is an example of a prompt with two ChatMessages, one for the system and one for the user role. The message for the system contains instructions for the LLM, while the message for the users contains user's query. It's also used to pass the retrieved documents to the LLM:
- _content:
- text: |
You are a helpful assistant answering the user's questions based on the provided documents.
If the answer is not in the documents, rely on the web_search tool to find information.
Do not use your own knowledge.
_role: system
- _content:
- text: |
Provided documents:
{% for document in documents %}
Document [{{ loop.index }}] :
{{ document.content }}
{% endfor %}
Question: {{ query }}
_role: user
You pass the prompt in the template parameter of a ChatPromptBuilder and then connect the prompt output to the messages input of a ChatGenerator:
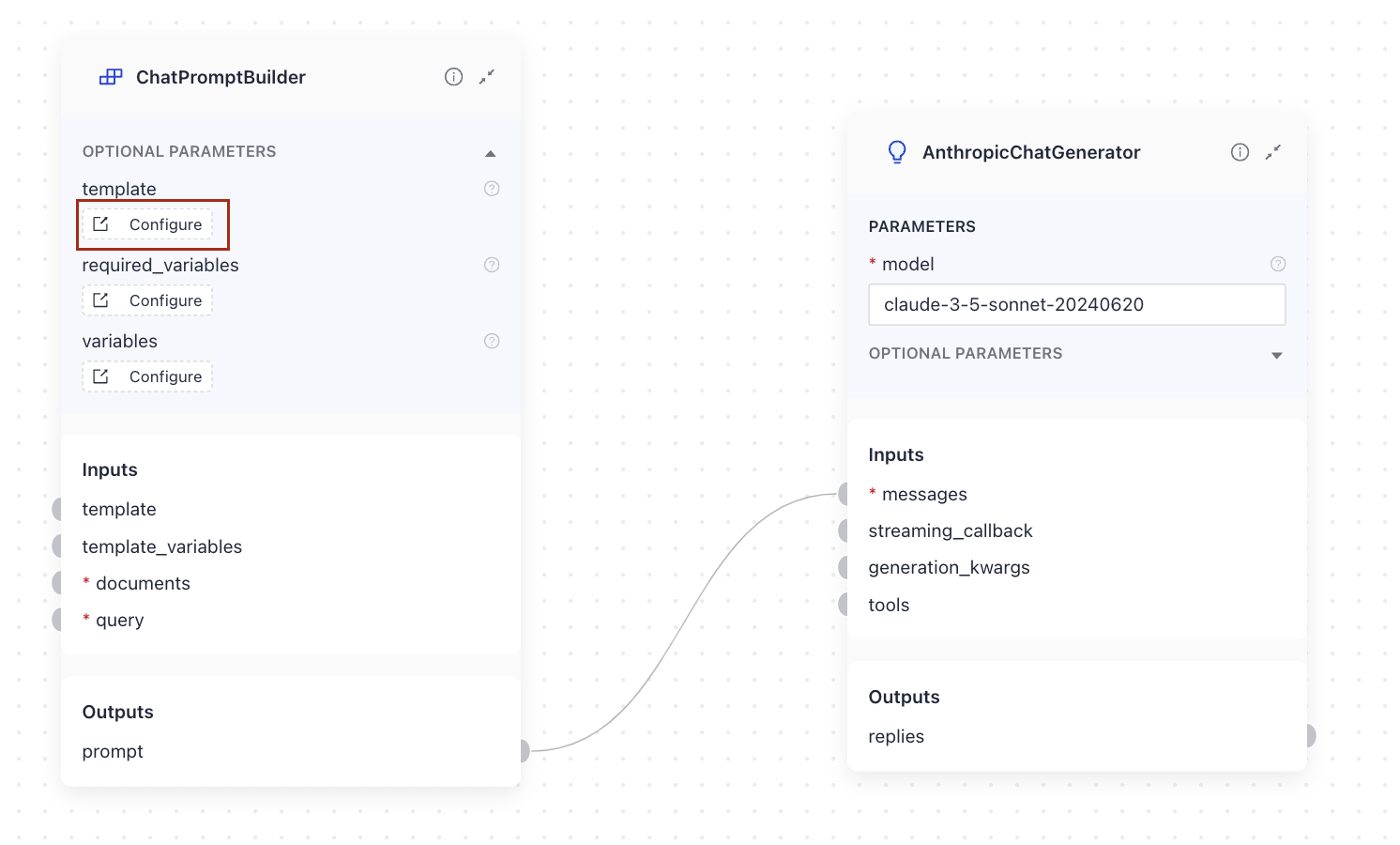
Generator and DeepsetAnswerBuilder
The Generator’s output is replies, a list of strings containing all the answers the LLM generates. However, pipelines require outputs in the form of Answer objects or its subclasses, such as GeneratedAnswer. Since the pipeline’s output is the same as the output of its last component, you need a component that converts replies into the GeneratedAnswer format. This is why Generators are always paired with a DeepsetAnswerBuilder.
DeepsetAnswerBuilder processes the Generator’s replies and transforms them into a list of GeneratedAnswer objects. It can also include documents in the answers, providing references to support the generated responses. This feature is particularly useful when you need answers that are backed by reliable sources.
To connect these two components, you simply link Generator’s replies output with DeepsetAnswerBuilder’s replies input. Additionally, DeepsetAnswerBuilder requires the query as an input to include it in the GeneratedAnswer. Ensure the query is properly connected to the DeepsetAnswerBuilder through the Input component to complete the configuration. DeepsetAnswerBuilder also accepts the prompt as input. If it receives the prompt, it adds it to the GeneratedAnswer's metadata. This is useful if you need a prompt as part of the API response from Haystack Platform. Here’s how to connect the components:
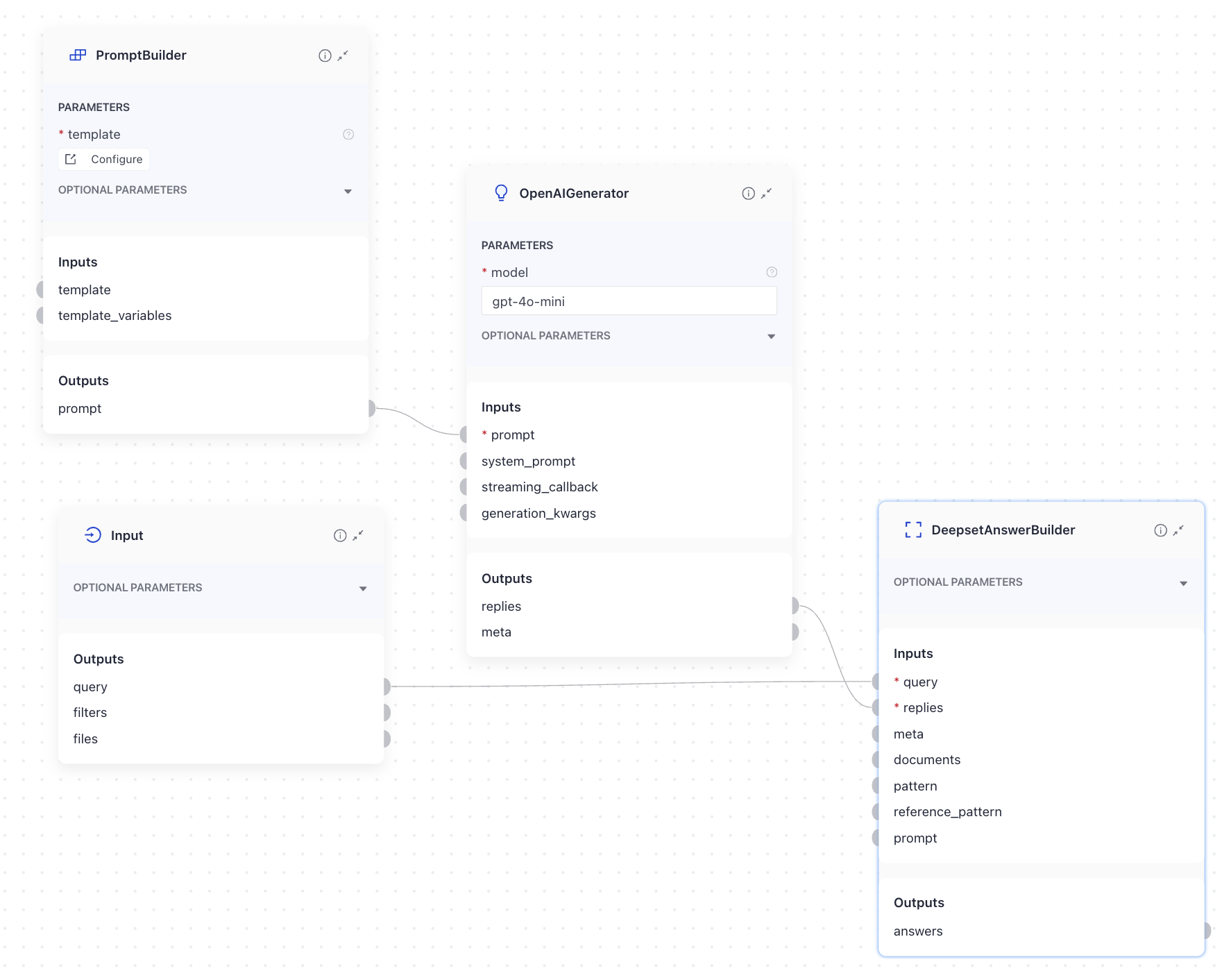
DeepsetAnswerBuilder is available in the Augmenters group in the components library.
ChatGenerators and AnswerBuilders
With smart connections, the pipeline now converts between ChatMessage and String automatically. You can skip the OutputAdapter in most cases. For details, see Simplify Your Pipelines with Smart Connections.
ChatGenerators can't connect directly to DeepsetAnswerBuilder as their input and output types don't match. You can use OutputAdapter in between to convert the ChatGenerator's output (list of ChatMessage objects) into a list of strings that DeepsetAnswerBuilder accepts:
OutputAdapter:
type: haystack.components.converters.output_adapter.OutputAdapter
init_parameters:
template: '{{ replies[0] }}'
output_type: typing.List[str]
custom_filters:
unsafe: false
This how you build the connections in Pipeline Builder:
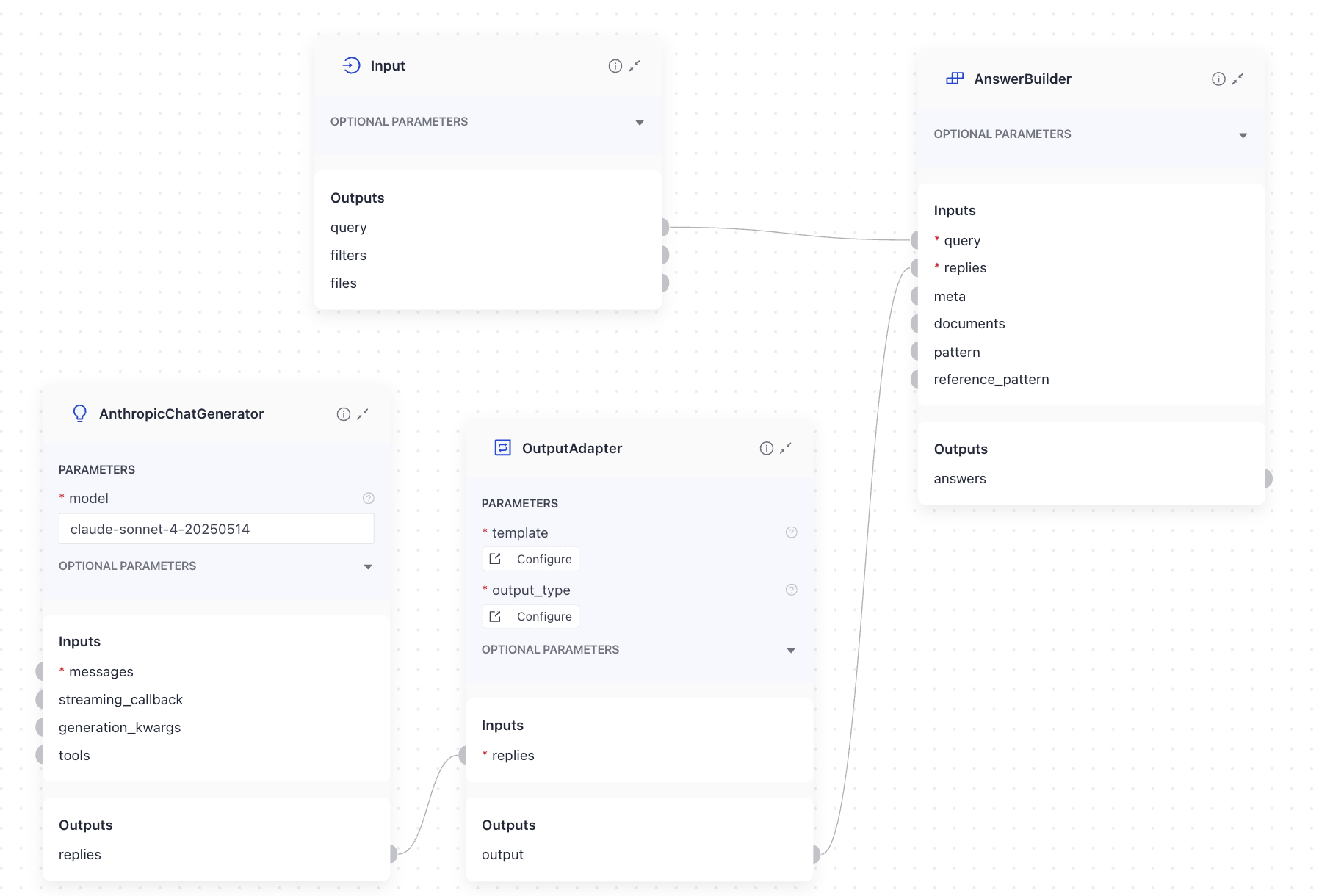
Another option is to simply use AnswerBuilder after a ChatGenerator. Their inputs and outputs are compatible.
![ChatGenerator and Input connected directly to AnswerBuilder]](/assets/images/chatgenerator_answerbuilder-c4cad5905a262b1e65d8e2c68921eb7f.png)
The main difference between AnswerBuilder and DeepsetAnswerBuilder is that the latter is better at handling complicated references and can extract content from XML tags.
Embedders
Embedders are a group of components that turn text or documents into vectors (embeddings) using models trained to do that. Embedders are specific to the model provider, with at least two embedders available for each:
- Document Embedder
- Text Embedder
Document Embedders are used in indexing pipelines to embed documents before they’re written into the document store. In most cases, this means a DocumentEmbedder is connected to the DocumentWriter:
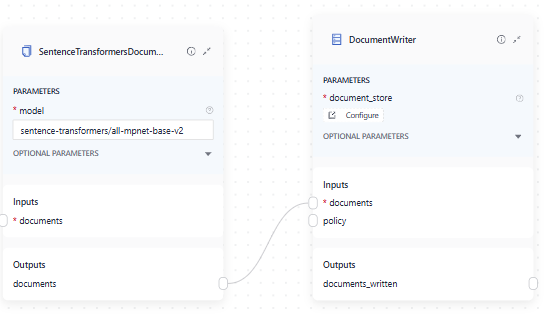
The connection is simple - you link DocumentEmbedder’s documents output with DocumentWriter’s documents input.
Text Embedders are used in query pipelines to embed the query text and pass it on to the next component, typically a Retriever.
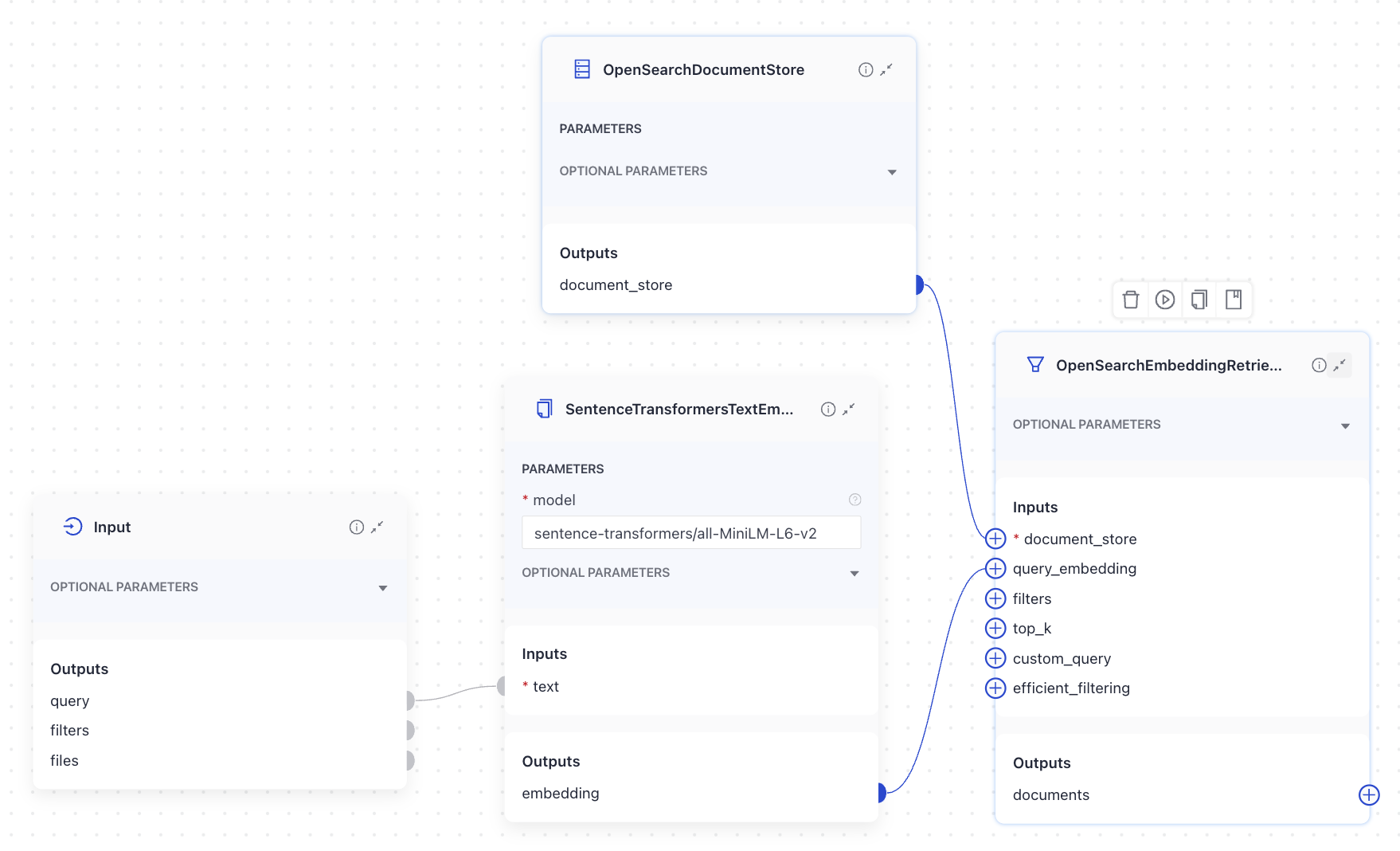
The Input component’s text output is connected to the TextEmbedder’s text input. The TextEmbedder then generates embeddings, and its embedding output is linked to the query_embedding input of the Retriever.
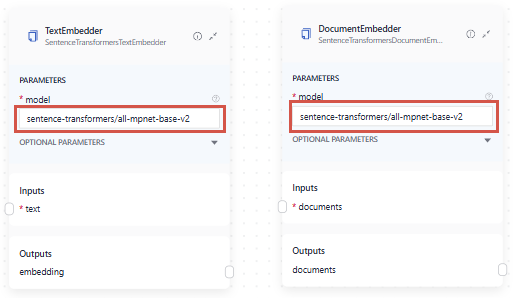
Keep in mind that the DocumentEmbedder in your indexing pipeline and the TextEmbedder in your query pipeline must use the same model. This ensures the embeddings are compatible for accurate retrieval.
Was this page helpful?