Agent
Add reasoning and external tools to your pipelines through the Agent component. An Agent can understand different types of input, decide when to take action, and use tools and memory to complete tasks. It generates context-aware responses based on its reasoning.
You can think of an Agent as a coordinator for your pipeline. It manages the flow of a conversation and determines which tools to use and when to use them. Under the hood, it relies on an LLM to plan and execute these steps.
Key Features
The Agent component:
- Works with different language models.
- Can use external tools including entire pipelines, custom functions, and MCP servers.
- Lets you define custom exit conditions to control when the
Agentstops. For example, stop after it generates a response or uses a specific tool. - Supports Jinja2 templating in both the system prompt and user prompt for dynamic, context-aware behavior at runtime.
- Maintains conversation history.
- Allows real-time streaming responses for both synchronous and asynchronous mode.
- Supports asynchronous execution.
- Stores memory in its state, including tool calls and conversation history.
- Has tracing support. Connect a tracer like Langfuse or Weights & Biases Weave to monitor the
Agent's execution in depth.
How It Works
- The Agent receives a user message.
- It sends the message to its chat model, along with the list of available tools.
- The model decides whether to respond directly or call a tool. It returns either a text response or a tool call.
- If the model returns text, the Agent returns the response along with the updated conversation.
- If the model returns a tool call:
- The Agent calls the tool and collects the result.
- If configured, the Agent stores selected tool outputs in its state. You define which outputs to store.
- The Agent adds the result to the conversation history.
- The Agent then evaluates whether to stop or continue:
- If the tool name matches an item in
exit_conditionsand the tool runs successfully, the Agent stops and returns the conversation. - If the tool returns an error, the Agent continues and sends the error message back to the LLM. - If the tool doesn't match any
exit_conditions, the Agent continues.
- If the tool name matches an item in
- When continuing, the Agent sends the updated conversation back to the model. The model can respond or call additional tools. This loop continues until one of the following conditions occurs:
- An
exit_conditionis met. - The
max_agent_stepslimit is reached.
- An
Agent Without Tools
When you use an Agent without providing tools, it behaves like the LLM component:
- It produces one response from the LLM
- It immediately exits after generating text
- It cannot perform iterative reasoning or tool calling
We recommend using the LLM component instead of the Agent component when you don't need to use tools.
Configuration
- Drag the
Agentcomponent onto the canvas from the Component Library. - Click Model on the component card to open the configuration panel.
- On the General tab:
- Choose a model from the list. Make sure Haystack Platform is connected to the model provider. For help, see Add Integrations.
Custom ModelsYou can use custom model definitions to configure the Agent's model. For details, see Add Custom Model Definitions.
- Optionally, add a system prompt to provide fixed instructions that guide the Agent's behavior, tone, or knowledge throughout the conversation. The system prompt supports dynamic content through Jinja2 syntax.
- Optionally, add a user prompt with a reusable Jinja2 template. This lets you invoke the Agent with dynamic variables without manually constructing
ChatMessageobjects. When you combinemessageswithuser_prompt, the rendered user prompt is appended to the provided messages. Userequired_variablesto specify which template variables must be provided. For detailed instructions on writing prompts and adding dynamic content to system prompts, see Writing Prompts in Haystack Enterprise Platform.
Jinja in theAgentcomponentWhen you add or edit the user prompt for the
Agentcomponent, you write regular text. To insert a variable, type@and a list of available variables appears so you can pick one. To insert a function, type/and you see all functions you can add to the template. To see the raw Jinja2 syntax, enable the Jinja toggle. It's disabled by default. - If needed, add tools to the Agent:
- Click Add tool in the Tools section.
- Choose the tool type from the list.
- Follow the instructions to configure the tool. If you need help, see Configure an Agent.
- Go to the Advanced tab to configure model-specific settings and agent-specific settings. Model-specific parameters depend on the model you chose. Agent-specific settings include:
Max agent stepsto limit the number of actions the Agent can perform. For more complicated tasks, you may need to increase this value. Note that increasing this value may increase the cost and time of the task.Exit conditionsto define when the Agent stops. The Agent runs iteratively, calling tools and feeding their outputs back to the model until one of the exit conditions is met.- To stop the Agent when it generates a text response, choose
text. - To stop the Agent after it uses a specific tool, choose the tool's name from the list.
- You can choose multiple exit conditions and the Agent stops when any of the conditions is met. For example, to stop the Agent when it generates a text response or after a specific tool is used, choose
textand the tool's name.
- To stop the Agent when it generates a text response, choose
Retry on tool failureto automatically retry the Agent if a tool call fails. This is useful if the tool call times out or temporarily fails.
For guidance on how to configure the Agent, see Building AI Agents.
For an explanation of the Agent and its tools, see also AI Agent and Agent Tools.
Connections
The Agent's input connections depend on the variables you configure in the user and system prompts. If you use the same variable in both prompts, it's shown as a single input connection. The Agent accepts an optional list of ChatMessage objects through its messages input. If you don't provide messages, you must have a user_prompt or system_prompt configured.
Output connections depend on the selected tools and which of their outputs are stored in the Agent state. Only outputs saved to the state appear as output connections.
By default, the Agent outputs a single ChatMessage through its last_message output and a list of ChatMessage objects through its messages output. The messages output is a concatenated system prompt, messages provided as input, user prompt (if provided), and the Agent's answer appended at the end.
If Agent is the component that produces the final output of your pipeline, you typically use the last_message output. If you need the full conversation history, use the messages output.
You can connect last_message to the Output component's messages input to display the final answer.
You can pass messages to the Agent directly from the Input component. Add messages as the Input's parameter and connect the Input's messages output to the Agent's messages input. The messages contain the query and the conversation history.
You can send the Agent's last_message output to the Output component to get the final answer. Configure messages as the Output's parameter and connect the Agent's last_message output to the Output's messages input. You can also send its messages output to another component.
Source Code
To check this component's source code, open agent.py in the Haystack repository.
Usage Examples
Basic Configuration
Agent:
type: haystack.components.agents.agent.Agent
init_parameters:
chat_generator:
init_parameters:
model: gpt-5.4
type: haystack.components.generators.chat.openai_responses.OpenAIResponsesChatGenerator
system_prompt: |-
{% message role="system" %}
You are a helpful assistant. Answer user's question.
{% endmessage %}
max_agent_steps: 100
raise_on_tool_invocation_failure: false
Basic Agent Configuration without Tools
This is the basic Agent configuration, with a model, system prompt, and user prompt. The user prompt includes a query that's dynamically inserted into the prompt when the Agent runs. There are no tools configured.
# haystack-pipeline
components:
Agent:
type: haystack.components.agents.agent.Agent
init_parameters:
chat_generator:
init_parameters:
model: gpt-5.4
type: haystack.components.generators.chat.openai_responses.OpenAIResponsesChatGenerator
tools:
system_prompt: |-
{% message role="system" %}
You are a helpful assistant. Answer user's question.
{% endmessage %}
user_prompt:
required_variables:
exit_conditions:
state_schema: {}
max_agent_steps: 100
streaming_callback:
raise_on_tool_invocation_failure: false
tool_invoker_kwargs:
confirmation_strategies:
Dynamic System Prompt with Jinja2
The Agent's system_prompt supports Jinja2 message template syntax, which lets you inject runtime variables and conditional logic directly into the system prompt. This is useful for adapting the Agent's behavior dynamically, for example, changing the response language, tone, or injecting time-aware instructions.
To use Jinja2 in the system prompt, wrap the prompt content in {% message role="system" %}...{% endmessage %} tags and use {{ variable_name }} for variables. List the variable names in required_variables to make them mandatory inputs.
# haystack-pipeline
components:
Agent:
type: haystack.components.agents.agent.Agent
init_parameters:
chat_generator:
init_parameters:
model: gpt-5.4
type: haystack.components.generators.chat.openai_responses.OpenAIResponsesChatGenerator
tools:
system_prompt: >-
{% message role="system" %}
You are a helpful assistant. Always respond in {{ language }}.
Today's date is {{ current_date }}.
{% endmessage %}
user_prompt: "{{ query }}"
required_variables:
- language
- current_date
- query
exit_conditions:
state_schema: {}
max_agent_steps: 100
streaming_callback:
raise_on_tool_invocation_failure: false
In this example, the language and current_date variables are injected into the system prompt at runtime. You can pass these as pipeline inputs or connect them to other components in the pipeline.
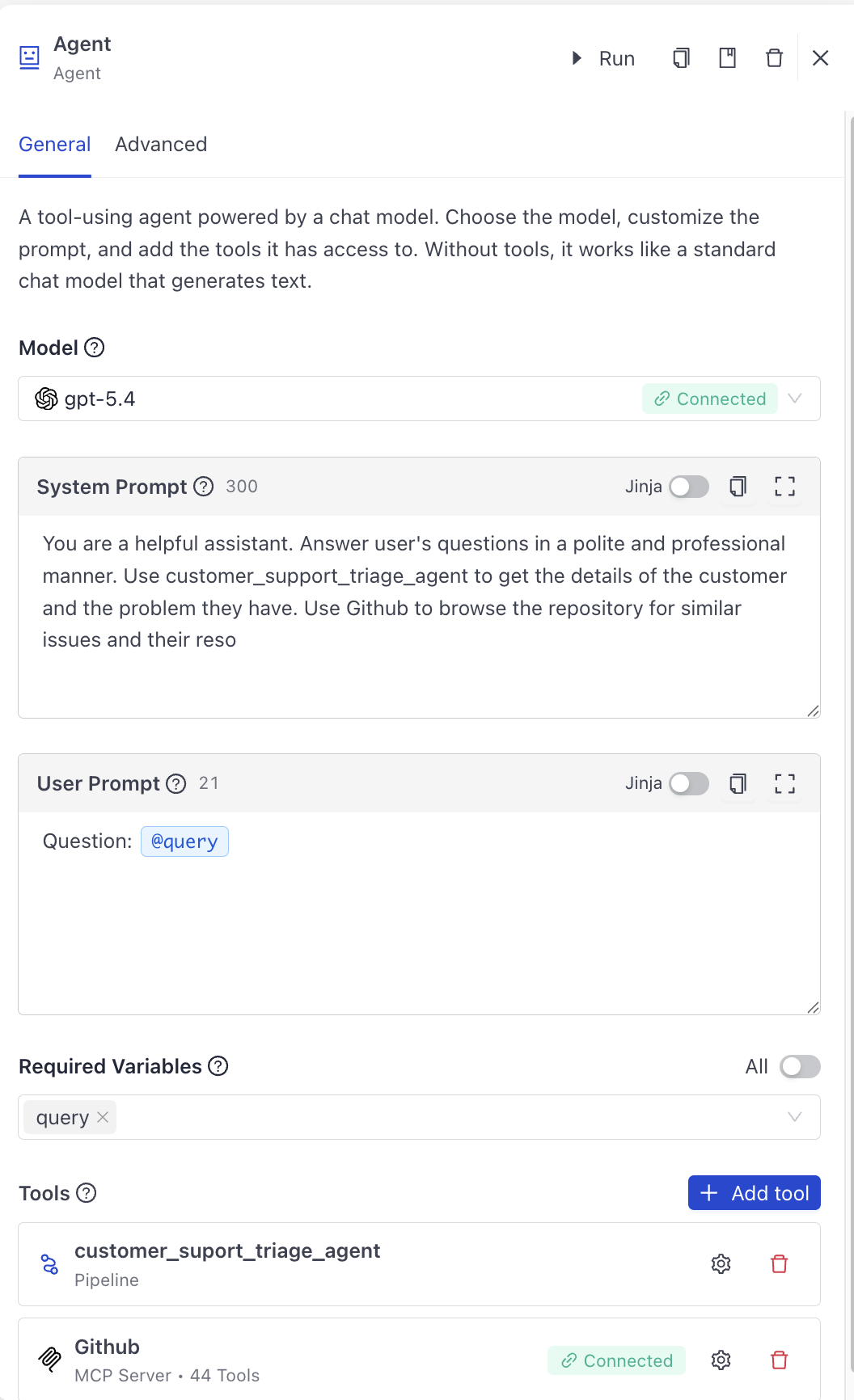
Basic Agent Configuration with Tools
This is the basic Agent configuration, with a model, system prompt, user prompt, and tools: an MCP server and a search pipeline.
# haystack-pipeline
components:
Agent:
type: haystack.components.agents.agent.Agent
init_parameters:
chat_generator:
init_parameters:
model: gpt-5.4
type: haystack.components.generators.chat.openai_responses.OpenAIResponsesChatGenerator
tools:
- type: haystack.tools.pipeline_tool.PipelineTool
data:
name: customer_suport_triage_agent
description: Use this tool to review customer tickets and get their details.
input_mapping:
query:
- ticket_fetcher.query
messages:
- agent.messages
output_mapping:
agent.messages: messages
pipeline:
components:
ticket_fetcher:
type: deepset_cloud_custom_nodes.code.code_component.Code
init_parameters:
code: >-
from datetime import datetime, timedelta
from haystack import component
@component
class Code:
"""Fetches ticket details by ID. Replace with your ticketing API or database."""
@component.output_types(
ticket_submitted_at=str,
customer_tier=str,
customer_name=str,
ticket_content=str,
)
def run(self, query: str) -> dict:
ticket_id = query.strip()
now = datetime.utcnow()
submitted = now - timedelta(hours=2)
return {
"ticket_submitted_at": submitted.strftime("%Y-%m-%d %H:%M UTC"),
"customer_tier": "Premium",
"customer_name": "Acme Corp",
"ticket_content": f"[Ticket {ticket_id}] Login fails with 502 after password reset. User needs access restored urgently.",
}
agent:
type: haystack.components.agents.agent.Agent
init_parameters:
chat_generator:
type: haystack.components.generators.chat.openai.OpenAIChatGenerator
init_parameters:
model: gpt-4o
api_key:
type: env_var
env_vars:
- OPENAI_API_KEY
strict: false
system_prompt: >-
You are a customer support triage specialist. Your job is
to:
1. Analyze incoming support tickets.
2. Classify their urgency (critical, high, medium, low).
3. Check if the ticket breaches SLA based on the submission
time and today's date.
4. Draft a professional first response to the customer.
SLA rules:
- Critical: respond within 1 hour
- High: respond within 4 hours
- Medium: respond within 24 hours
- Low: respond within 72 hours
Always be empathetic and solution-oriented.
max_agent_steps: 5
user_prompt: >-
Today's date and time: {% now 'utc'%}
Ticket submitted: {{ ticket_submitted_at }}
Customer tier: {{ customer_tier }}
Customer name: {{ customer_name }}
{{ ticket_content }}
Based on the SLA rules and the time elapsed since
submission, classify urgency and draft a response.
required_variables:
- ticket_submitted_at
- customer_tier
- customer_name
- ticket_content
connections:
- sender: ticket_fetcher.ticket_submitted_at
receiver: agent.ticket_submitted_at
- sender: ticket_fetcher.customer_tier
receiver: agent.customer_tier
- sender: ticket_fetcher.customer_name
receiver: agent.customer_name
- sender: ticket_fetcher.ticket_content
receiver: agent.ticket_content
max_runs_per_component: 100
metadata: {}
is_pipeline_async: false
inputs_from_state: {}
outputs_to_string:
messages:
source: messages
outputs_to_state: {}
parameters:
description: "A component that combines: 'ticket_fetcher': Forward all inputs to
the wrapped component's run method., 'agent': Process messages and
execute tools until an exit condition is met."
properties:
query:
description: "Provided to the 'answer_builder' component as: 'The query used in
the prompts for the Generator.'."
type: string
messages:
description: "Provided to the 'agent' component as: 'List of Haystack
ChatMessage objects to process.'."
items:
$ref: "#/$defs/ChatMessage"
type: array
required:
- query
- messages
type: object
$defs:
ChatMessage:
properties:
role:
$ref: "#/$defs/ChatRole"
description: Field 'role' of 'ChatMessage'.
content:
description: Field 'content' of 'ChatMessage'.
items:
anyOf:
- $ref: "#/$defs/TextContent"
- $ref: "#/$defs/ToolCall"
- $ref: "#/$defs/ToolCallResult"
- $ref: "#/$defs/ImageContent"
- $ref: "#/$defs/ReasoningContent"
- $ref: "#/$defs/FileContent"
type: array
name:
anyOf:
- type: string
- type: "null"
default:
description: Field 'name' of 'ChatMessage'.
meta:
additionalProperties: true
default: {}
description: Field 'meta' of 'ChatMessage'.
type: object
required:
- role
- content
type: object
ChatRole:
description: Enumeration representing the roles within a chat.
enum:
- user
- system
- assistant
- tool
type: string
FileContent:
properties:
base64_data:
description: A base64 string representing the file.
type: string
mime_type:
anyOf:
- type: string
- type: "null"
default:
description: >-
The MIME type of the file (e.g. "application/pdf").
Providing this value is recommended, as most LLM providers
require it.
If not provided, the MIME type is guessed from the base64
string, which can be slow and not always reliable.
filename:
anyOf:
- type: string
- type: "null"
default:
description: Optional filename of the file. Some LLM providers use this
information.
extra:
additionalProperties: true
default: {}
description: >-
Dictionary of extra information about the file. Can be
used to store provider-specific information.
To avoid serialization issues, values should be JSON
serializable.
type: object
validation:
default: true
description: >-
If True (default), a validation process is performed:
- Check whether the base64 string is valid;
- Guess the MIME type if not provided.
Set to False to skip validation and speed up
initialization.
type: boolean
required:
- base64_data
type: object
ImageContent:
properties:
base64_image:
description: A base64 string representing the image.
type: string
mime_type:
anyOf:
- type: string
- type: "null"
default:
description: >-
The MIME type of the image (e.g. "image/png",
"image/jpeg").
Providing this value is recommended, as most LLM providers
require it.
If not provided, the MIME type is guessed from the base64
string, which can be slow and not always reliable.
detail:
anyOf:
- enum:
- auto
- high
- low
type: string
- type: "null"
default:
description: Optional detail level of the image (only supported by OpenAI). One
of "auto", "high", or "low".
meta:
additionalProperties: true
default: {}
description: Optional metadata for the image.
type: object
validation:
default: true
description: >-
If True (default), a validation process is performed:
- Check whether the base64 string is valid;
- Guess the MIME type if not provided;
- Check if the MIME type is a valid image MIME type.
Set to False to skip validation and speed up
initialization.
type: boolean
required:
- base64_image
type: object
ReasoningContent:
properties:
reasoning_text:
description: The reasoning text produced by the model.
type: string
extra:
additionalProperties: true
default: {}
description: >-
Dictionary of extra information about the reasoning
content. Use to store provider-specific
information. To avoid serialization issues, values should
be JSON serializable.
type: object
required:
- reasoning_text
type: object
TextContent:
properties:
text:
description: The text content of the message.
type: string
required:
- text
type: object
ToolCall:
properties:
tool_name:
description: The name of the Tool to call.
type: string
arguments:
additionalProperties: true
description: The arguments to call the Tool with.
type: object
id:
anyOf:
- type: string
- type: "null"
default:
description: The ID of the Tool call.
extra:
anyOf:
- additionalProperties: true
type: object
- type: "null"
default:
description: >-
Dictionary of extra information about the Tool call. Use
to store provider-specific
information. To avoid serialization issues, values should
be JSON serializable.
required:
- tool_name
- arguments
type: object
ToolCallResult:
properties:
result:
anyOf:
- type: string
- items:
anyOf:
- $ref: "#/$defs/TextContent"
- $ref: "#/$defs/ImageContent"
type: array
description: The result of the Tool invocation.
origin:
$ref: "#/$defs/ToolCall"
description: The Tool call that produced this result.
error:
description: Whether the Tool invocation resulted in an error.
type: boolean
required:
- result
- origin
- error
type: object
_meta:
name: customer_suport_triage_agent
description: Use this tool to review customer tickets and get their details.
tool_id:
- type: haystack_integrations.tools.mcp.MCPToolset
data:
server_info:
type: haystack_integrations.tools.mcp.mcp_tool.StreamableHttpServerInfo
url: https://api.githubcopilot.com/mcp/
timeout: 900
token:
type: env_var
strict: true
env_vars:
- GITHUB_MCP_TOKEN_83168973
tool_names:
- add_comment_to_pending_review
- add_issue_comment
- add_reply_to_pull_request_comment
- assign_copilot_to_issue
- create_branch
- create_or_update_file
- create_pull_request
- create_pull_request_with_copilot
- create_repository
- delete_file
- fork_repository
- get_commit
- get_copilot_job_status
- get_file_contents
- get_label
- get_latest_release
- get_me
- get_release_by_tag
- get_tag
- get_team_members
- get_teams
- issue_read
- issue_write
- list_branches
- list_commits
- list_issue_types
- list_issues
- list_pull_requests
- list_releases
- list_tags
- merge_pull_request
- pull_request_read
- pull_request_review_write
- push_files
- request_copilot_review
- run_secret_scanning
- search_code
- search_issues
- search_pull_requests
- search_repositories
- search_users
- sub_issue_write
- update_pull_request
- update_pull_request_branch
eager_connect: false
_meta:
name: Github
description:
tool_id:
system_prompt: >-
{% message role="system" %}
You are a helpful assistant. Answer user's questions in a polite and
professional manner. Use customer_support_triage_agent to get the
details of the customer and the problem they have. Use Github to browse
the repository for similar issues and their reso
{% endmessage %}
user_prompt: "Question: {{ query }}"
required_variables:
- query
exit_conditions:
state_schema: {}
max_agent_steps: 100
streaming_callback:
raise_on_tool_invocation_failure: false
tool_invoker_kwargs:
confirmation_strategies:
Agent In a Pipeline
This is an Agent with Github MCP and a local search pipeline as tools used in a pipeline:
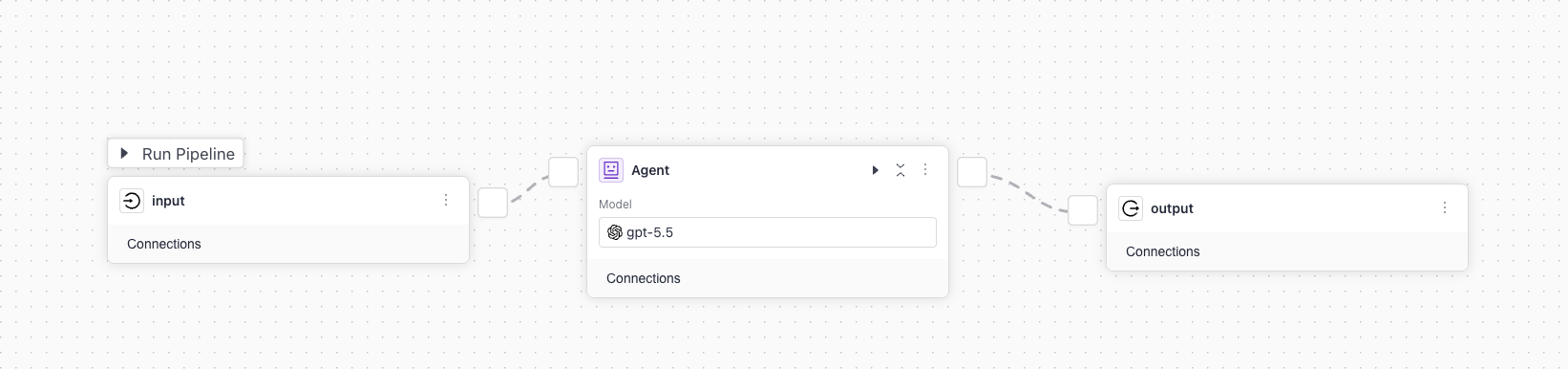
And here's the YAML configuration:
# haystack-pipeline
components:
Agent:
type: haystack.components.agents.agent.Agent
init_parameters:
chat_generator:
init_parameters:
model: gpt-5.4
type: haystack.components.generators.chat.openai_responses.OpenAIResponsesChatGenerator
tools:
- type: haystack.tools.pipeline_tool.PipelineTool
data:
name: customer_suport_triage_agent
description: Use this tool to review customer tickets and get their details.
input_mapping:
query:
- ticket_fetcher.query
messages:
- agent.messages
output_mapping:
agent.messages: messages
pipeline:
components:
ticket_fetcher:
type: deepset_cloud_custom_nodes.code.code_component.Code
init_parameters:
code: >-
from datetime import datetime, timedelta
from haystack import component
@component
class Code:
"""Fetches ticket details by ID. Replace with your ticketing API or database."""
@component.output_types(
ticket_submitted_at=str,
customer_tier=str,
customer_name=str,
ticket_content=str,
)
def run(self, query: str) -> dict:
ticket_id = query.strip()
now = datetime.utcnow()
submitted = now - timedelta(hours=2)
return {
"ticket_submitted_at": submitted.strftime("%Y-%m-%d %H:%M UTC"),
"customer_tier": "Premium",
"customer_name": "Acme Corp",
"ticket_content": f"[Ticket {ticket_id}] Login fails with 502 after password reset. User needs access restored urgently.",
}
agent:
type: haystack.components.agents.agent.Agent
init_parameters:
chat_generator:
type: haystack.components.generators.chat.openai.OpenAIChatGenerator
init_parameters:
model: gpt-4o
api_key:
type: env_var
env_vars:
- OPENAI_API_KEY
strict: false
system_prompt: >-
You are a customer support triage specialist. Your job is
to:
1. Analyze incoming support tickets.
2. Classify their urgency (critical, high, medium, low).
3. Check if the ticket breaches SLA based on the submission
time and today's date.
4. Draft a professional first response to the customer.
SLA rules:
- Critical: respond within 1 hour
- High: respond within 4 hours
- Medium: respond within 24 hours
- Low: respond within 72 hours
Always be empathetic and solution-oriented.
max_agent_steps: 5
user_prompt: >-
Today's date and time: {% now 'utc'%}
Ticket submitted: {{ ticket_submitted_at }}
Customer tier: {{ customer_tier }}
Customer name: {{ customer_name }}
{{ ticket_content }}
Based on the SLA rules and the time elapsed since
submission, classify urgency and draft a response.
required_variables:
- ticket_submitted_at
- customer_tier
- customer_name
- ticket_content
connections:
- sender: ticket_fetcher.ticket_submitted_at
receiver: agent.ticket_submitted_at
- sender: ticket_fetcher.customer_tier
receiver: agent.customer_tier
- sender: ticket_fetcher.customer_name
receiver: agent.customer_name
- sender: ticket_fetcher.ticket_content
receiver: agent.ticket_content
max_runs_per_component: 100
metadata: {}
is_pipeline_async: false
inputs_from_state: {}
outputs_to_string:
messages:
source: messages
outputs_to_state: {}
parameters:
description: "A component that combines: 'ticket_fetcher': Forward all inputs to
the wrapped component's run method., 'agent': Process messages and
execute tools until an exit condition is met."
properties:
query:
description: "Provided to the 'answer_builder' component as: 'The query used in
the prompts for the Generator.'."
type: string
messages:
description: "Provided to the 'agent' component as: 'List of Haystack
ChatMessage objects to process.'."
items:
$ref: "#/$defs/ChatMessage"
type: array
required:
- query
- messages
type: object
$defs:
ChatMessage:
properties:
role:
$ref: "#/$defs/ChatRole"
description: Field 'role' of 'ChatMessage'.
content:
description: Field 'content' of 'ChatMessage'.
items:
anyOf:
- $ref: "#/$defs/TextContent"
- $ref: "#/$defs/ToolCall"
- $ref: "#/$defs/ToolCallResult"
- $ref: "#/$defs/ImageContent"
- $ref: "#/$defs/ReasoningContent"
- $ref: "#/$defs/FileContent"
type: array
name:
anyOf:
- type: string
- type: "null"
default:
description: Field 'name' of 'ChatMessage'.
meta:
additionalProperties: true
default: {}
description: Field 'meta' of 'ChatMessage'.
type: object
required:
- role
- content
type: object
ChatRole:
description: Enumeration representing the roles within a chat.
enum:
- user
- system
- assistant
- tool
type: string
FileContent:
properties:
base64_data:
description: A base64 string representing the file.
type: string
mime_type:
anyOf:
- type: string
- type: "null"
default:
description: >-
The MIME type of the file (e.g. "application/pdf").
Providing this value is recommended, as most LLM providers
require it.
If not provided, the MIME type is guessed from the base64
string, which can be slow and not always reliable.
filename:
anyOf:
- type: string
- type: "null"
default:
description: Optional filename of the file. Some LLM providers use this
information.
extra:
additionalProperties: true
default: {}
description: >-
Dictionary of extra information about the file. Can be
used to store provider-specific information.
To avoid serialization issues, values should be JSON
serializable.
type: object
validation:
default: true
description: >-
If True (default), a validation process is performed:
- Check whether the base64 string is valid;
- Guess the MIME type if not provided.
Set to False to skip validation and speed up
initialization.
type: boolean
required:
- base64_data
type: object
ImageContent:
properties:
base64_image:
description: A base64 string representing the image.
type: string
mime_type:
anyOf:
- type: string
- type: "null"
default:
description: >-
The MIME type of the image (e.g. "image/png",
"image/jpeg").
Providing this value is recommended, as most LLM providers
require it.
If not provided, the MIME type is guessed from the base64
string, which can be slow and not always reliable.
detail:
anyOf:
- enum:
- auto
- high
- low
type: string
- type: "null"
default:
description: Optional detail level of the image (only supported by OpenAI). One
of "auto", "high", or "low".
meta:
additionalProperties: true
default: {}
description: Optional metadata for the image.
type: object
validation:
default: true
description: >-
If True (default), a validation process is performed:
- Check whether the base64 string is valid;
- Guess the MIME type if not provided;
- Check if the MIME type is a valid image MIME type.
Set to False to skip validation and speed up
initialization.
type: boolean
required:
- base64_image
type: object
ReasoningContent:
properties:
reasoning_text:
description: The reasoning text produced by the model.
type: string
extra:
additionalProperties: true
default: {}
description: >-
Dictionary of extra information about the reasoning
content. Use to store provider-specific
information. To avoid serialization issues, values should
be JSON serializable.
type: object
required:
- reasoning_text
type: object
TextContent:
properties:
text:
description: The text content of the message.
type: string
required:
- text
type: object
ToolCall:
properties:
tool_name:
description: The name of the Tool to call.
type: string
arguments:
additionalProperties: true
description: The arguments to call the Tool with.
type: object
id:
anyOf:
- type: string
- type: "null"
default:
description: The ID of the Tool call.
extra:
anyOf:
- additionalProperties: true
type: object
- type: "null"
default:
description: >-
Dictionary of extra information about the Tool call. Use
to store provider-specific
information. To avoid serialization issues, values should
be JSON serializable.
required:
- tool_name
- arguments
type: object
ToolCallResult:
properties:
result:
anyOf:
- type: string
- items:
anyOf:
- $ref: "#/$defs/TextContent"
- $ref: "#/$defs/ImageContent"
type: array
description: The result of the Tool invocation.
origin:
$ref: "#/$defs/ToolCall"
description: The Tool call that produced this result.
error:
description: Whether the Tool invocation resulted in an error.
type: boolean
required:
- result
- origin
- error
type: object
_meta:
name: customer_suport_triage_agent
description: Use this tool to review customer tickets and get their details.
tool_id:
- type: haystack_integrations.tools.mcp.MCPToolset
data:
server_info:
type: haystack_integrations.tools.mcp.mcp_tool.StreamableHttpServerInfo
url: https://api.githubcopilot.com/mcp/
timeout: 900
token:
type: env_var
strict: true
env_vars:
- GITHUB_MCP_TOKEN_83168973
tool_names:
- add_comment_to_pending_review
- add_issue_comment
- add_reply_to_pull_request_comment
- assign_copilot_to_issue
- create_branch
- create_or_update_file
- create_pull_request
- create_pull_request_with_copilot
- create_repository
- delete_file
- fork_repository
- get_commit
- get_copilot_job_status
- get_file_contents
- get_label
- get_latest_release
- get_me
- get_release_by_tag
- get_tag
- get_team_members
- get_teams
- issue_read
- issue_write
- list_branches
- list_commits
- list_issue_types
- list_issues
- list_pull_requests
- list_releases
- list_tags
- merge_pull_request
- pull_request_read
- pull_request_review_write
- push_files
- request_copilot_review
- run_secret_scanning
- search_code
- search_issues
- search_pull_requests
- search_repositories
- search_users
- sub_issue_write
- update_pull_request
- update_pull_request_branch
eager_connect: false
_meta:
name: Github
description:
tool_id:
system_prompt: >-
{% message role="system" %}
You are a helpful assistant. Answer user's questions in a polite and
professional manner. Use customer_support_triage_agent to get the
details of the customer and the problem they have. Use Github to browse
the repository for similar issues and their reso
{% endmessage %}
user_prompt: "Question: {{ query }}"
required_variables:
- query
exit_conditions:
state_schema: {}
max_agent_steps: 100
streaming_callback:
raise_on_tool_invocation_failure: false
tool_invoker_kwargs:
confirmation_strategies:
connections: []
max_runs_per_component: 100
metadata: {}
inputs:
messages:
- Agent.messages
query:
- Agent.query
outputs:
messages: Agent.messages
Pipeline as a Tool
This is an agent that uses internal_search (a RAG pipeline) as a tool:
# haystack-pipeline
components:
Agent:
type: haystack.components.agents.agent.Agent
init_parameters:
chat_generator:
init_parameters:
model: gpt-5.2
type: haystack.components.generators.chat.openai_responses.OpenAIResponsesChatGenerator
tools:
- type: haystack.tools.pipeline_tool.PipelineTool
data:
name: internal_search
description: Use internal_search to search the company database and find
information about the company and its processes.
input_mapping:
query:
- retriever.query
- ranker.query
- LLM.question
filters:
- retriever.filters_bm25
- retriever.filters_embedding
files:
- multi_file_converter.sources
output_mapping:
attachments_joiner.documents: documents
LLM.messages: messages
pipeline:
components:
retriever:
type: haystack_integrations.components.retrievers.opensearch.open_search_hybrid_retriever.OpenSearchHybridRetriever
init_parameters:
document_store:
type: haystack_integrations.document_stores.opensearch.document_store.OpenSearchDocumentStore
init_parameters:
hosts:
index: Standard-Index-English
max_chunk_bytes: 104857600
embedding_dim: 768
return_embedding: false
method:
mappings:
settings:
create_index: true
http_auth:
use_ssl:
verify_certs:
timeout:
top_k: 20
fuzziness: 0
embedder:
type: deepset_cloud_custom_nodes.embedders.nvidia.text_embedder.DeepsetNvidiaTextEmbedder
init_parameters:
normalize_embeddings: true
model: intfloat/e5-base-v2
ranker:
type: deepset_cloud_custom_nodes.rankers.nvidia.ranker.DeepsetNvidiaRanker
init_parameters:
model: intfloat/simlm-msmarco-reranker
top_k: 8
meta_field_grouping_ranker:
type: haystack.components.rankers.meta_field_grouping_ranker.MetaFieldGroupingRanker
init_parameters:
group_by: file_id
subgroup_by:
sort_docs_by: split_id
attachments_joiner:
type: haystack.components.joiners.document_joiner.DocumentJoiner
init_parameters:
join_mode: concatenate
weights:
top_k:
sort_by_score: true
multi_file_converter:
type: haystack.core.super_component.super_component.SuperComponent
init_parameters:
input_mapping:
sources:
- file_classifier.sources
is_pipeline_async: false
output_mapping:
score_adder.output: documents
pipeline:
components:
file_classifier:
type: haystack.components.routers.file_type_router.FileTypeRouter
init_parameters:
mime_types:
- text/plain
- application/pdf
- text/markdown
- text/html
- application/vnd.openxmlformats-officedocument.wordprocessingml.document
- application/vnd.openxmlformats-officedocument.presentationml.presentation
- application/vnd.openxmlformats-officedocument.spreadsheetml.sheet
- text/csv
text_converter:
type: haystack.components.converters.txt.TextFileToDocument
init_parameters:
encoding: utf-8
pdf_converter:
type: haystack.components.converters.pdfminer.PDFMinerToDocument
init_parameters:
line_overlap: 0.5
char_margin: 2
line_margin: 0.5
word_margin: 0.1
boxes_flow: 0.5
detect_vertical: true
all_texts: false
store_full_path: false
markdown_converter:
type: haystack.components.converters.txt.TextFileToDocument
init_parameters:
encoding: utf-8
html_converter:
type: haystack.components.converters.html.HTMLToDocument
init_parameters:
extraction_kwargs:
output_format: markdown
target_language:
include_tables: true
include_links: true
docx_converter:
type: haystack.components.converters.docx.DOCXToDocument
init_parameters:
link_format: markdown
pptx_converter:
type: haystack.components.converters.pptx.PPTXToDocument
init_parameters: {}
xlsx_converter:
type: haystack.components.converters.xlsx.XLSXToDocument
init_parameters: {}
csv_converter:
type: haystack.components.converters.csv.CSVToDocument
init_parameters:
encoding: utf-8
splitter:
type: haystack.components.preprocessors.document_splitter.DocumentSplitter
init_parameters:
split_by: word
split_length: 250
split_overlap: 30
respect_sentence_boundary: true
language: en
score_adder:
type: haystack.components.converters.output_adapter.OutputAdapter
init_parameters:
template: >-
{%- set scored_documents = [] -%}
{%- for document in documents -%}
{%- set doc_dict = document.to_dict() -%}
{%- set _ = doc_dict.update({'score': 100.0}) -%}
{%- set scored_doc = document.from_dict(doc_dict) -%}
{%- set _ = scored_documents.append(scored_doc) -%}
{%- endfor -%}
{{ scored_documents }}
output_type: List[haystack.Document]
custom_filters:
unsafe: true
text_joiner:
type: haystack.components.joiners.document_joiner.DocumentJoiner
init_parameters:
join_mode: concatenate
sort_by_score: false
tabular_joiner:
type: haystack.components.joiners.document_joiner.DocumentJoiner
init_parameters:
join_mode: concatenate
sort_by_score: false
connections:
- sender: file_classifier.text/plain
receiver: text_converter.sources
- sender: file_classifier.application/pdf
receiver: pdf_converter.sources
- sender: file_classifier.text/markdown
receiver: markdown_converter.sources
- sender: file_classifier.text/html
receiver: html_converter.sources
- sender: file_classifier.application/vnd.openxmlformats-officedocument.wordprocessingml.document
receiver: docx_converter.sources
- sender: file_classifier.application/vnd.openxmlformats-officedocument.presentationml.presentation
receiver: pptx_converter.sources
- sender: file_classifier.application/vnd.openxmlformats-officedocument.spreadsheetml.sheet
receiver: xlsx_converter.sources
- sender: file_classifier.text/csv
receiver: csv_converter.sources
- sender: text_joiner.documents
receiver: splitter.documents
- sender: text_converter.documents
receiver: text_joiner.documents
- sender: pdf_converter.documents
receiver: text_joiner.documents
- sender: markdown_converter.documents
receiver: text_joiner.documents
- sender: html_converter.documents
receiver: text_joiner.documents
- sender: pptx_converter.documents
receiver: text_joiner.documents
- sender: docx_converter.documents
receiver: text_joiner.documents
- sender: xlsx_converter.documents
receiver: tabular_joiner.documents
- sender: csv_converter.documents
receiver: tabular_joiner.documents
- sender: splitter.documents
receiver: tabular_joiner.documents
- sender: tabular_joiner.documents
receiver: score_adder.documents
LLM:
type: haystack.components.generators.chat.llm.LLM
init_parameters:
chat_generator:
init_parameters:
model: gpt-5.4
type: haystack.components.generators.chat.openai_responses.OpenAIResponsesChatGenerator
system_prompt: ""
user_prompt: >-
{% message role="user" %}
You are a technical expert.
You answer questions truthfully based on provided documents.
If the answer exists in several documents, summarize them.
Ignore documents that don't contain the answer to the
question.
Only answer based on the documents provided. Don't make
things up.
If no information related to the question can be found in
the document, say so.
Always use references in the form [NUMBER OF DOCUMENT] when
using information from a document, e.g. [3] for Document [3]
.
Never name the documents, only enter a number in square
brackets as a reference.
The reference must only refer to the number that comes in
square brackets after the document.
Otherwise, do not use brackets in your answer and reference
ONLY the number of the document without mentioning the word
document.
These are the documents:
{%- if documents|length > 0 %}
{%- for document in documents %}
Document [{{ loop.index }}] :
Name of Source File: {{ document.meta.file_name }}
{{ document.content }}
{% endfor -%}
{%- else %}
No relevant documents found.
Respond with "Sorry, no matching documents were found,
please adjust the filters or try a different question."
{% endif %}
Question: {{ question }}
Answer:
{% endmessage %}
required_variables: "*"
streaming_callback:
connections:
- sender: retriever.documents
receiver: ranker.documents
- sender: ranker.documents
receiver: meta_field_grouping_ranker.documents
- sender: multi_file_converter.documents
receiver: attachments_joiner.documents
- sender: meta_field_grouping_ranker.documents
receiver: attachments_joiner.documents
- sender: attachments_joiner.documents
receiver: LLM.documents
max_runs_per_component: 100
metadata: {}
is_pipeline_async: false
inputs_from_state: {}
outputs_to_string:
documents:
source: documents
messages:
source: messages
outputs_to_state:
documents:
source: documents
parameters:
$defs:
ByteStream:
properties:
data:
description: The binary data stored in Bytestream.
format: binary
type: string
meta:
additionalProperties: true
default: {}
description: Additional metadata to be stored with the ByteStream.
type: object
mime_type:
anyOf:
- type: string
- type: 'null'
default:
description: The mime type of the binary data.
required:
- data
type: object
description: "A component that combines: 'retriever': Runs the wrapped pipeline
with the provided inputs., 'ranker': Returns a list of documents
ranked by their similarity to the given query., 'LLM': Process
messages and generate a response from the language model.,
'multi_file_converter': Runs the wrapped pipeline with the
provided inputs."
properties:
query:
description: "Provided to the 'ranker' component as: 'The input query to compare
the documents to.', and Provided to the 'answer_builder'
component as: 'The query used in the prompts for the
Generator.'."
type: string
filters:
description: Input 'filters' for the component.
anyOf:
- additionalProperties: true
type: object
- type: "null"
files:
description: Input 'files' for the component.
items:
anyOf:
- type: string
- format: path
type: string
- $ref: '#/$defs/ByteStream'
type: array
required:
- query
- files
type: object
_meta:
name: internal_search
description: Use internal_search to search the company database and find
information about the company and its processes.
tool_id:
system_prompt: "You are a deep research assistant.
You create comprehensive research reports to answer the user's
questions.
You use the 'internal_search' tool to answer any questions about the
company and its processes.
You perform multiple searches until you have the information you need to
answer the question.
Make sure you research different aspects of the question.
Use markdown to format your response.
When answering, cite your sources using markdown links.
It is important that you cite accurately."
exit_conditions:
state_schema:
documents:
type: list[haystack.dataclasses.document.Document]
_meta:
used_by:
internal_search: output
max_agent_steps: 100
streaming_callback:
raise_on_tool_invocation_failure: false
tool_invoker_kwargs:
connections: []
max_runs_per_component: 100
metadata: {}
inputs:
messages:
- Agent.messages
outputs:
documents: Agent.documents
Adding Sources to Agent Results
To show the sources or documents the Agent used to generate its answer, configure the Agent to output those documents. To do this, open the configuration of the tool that outputs the documents and choose to output them to State.
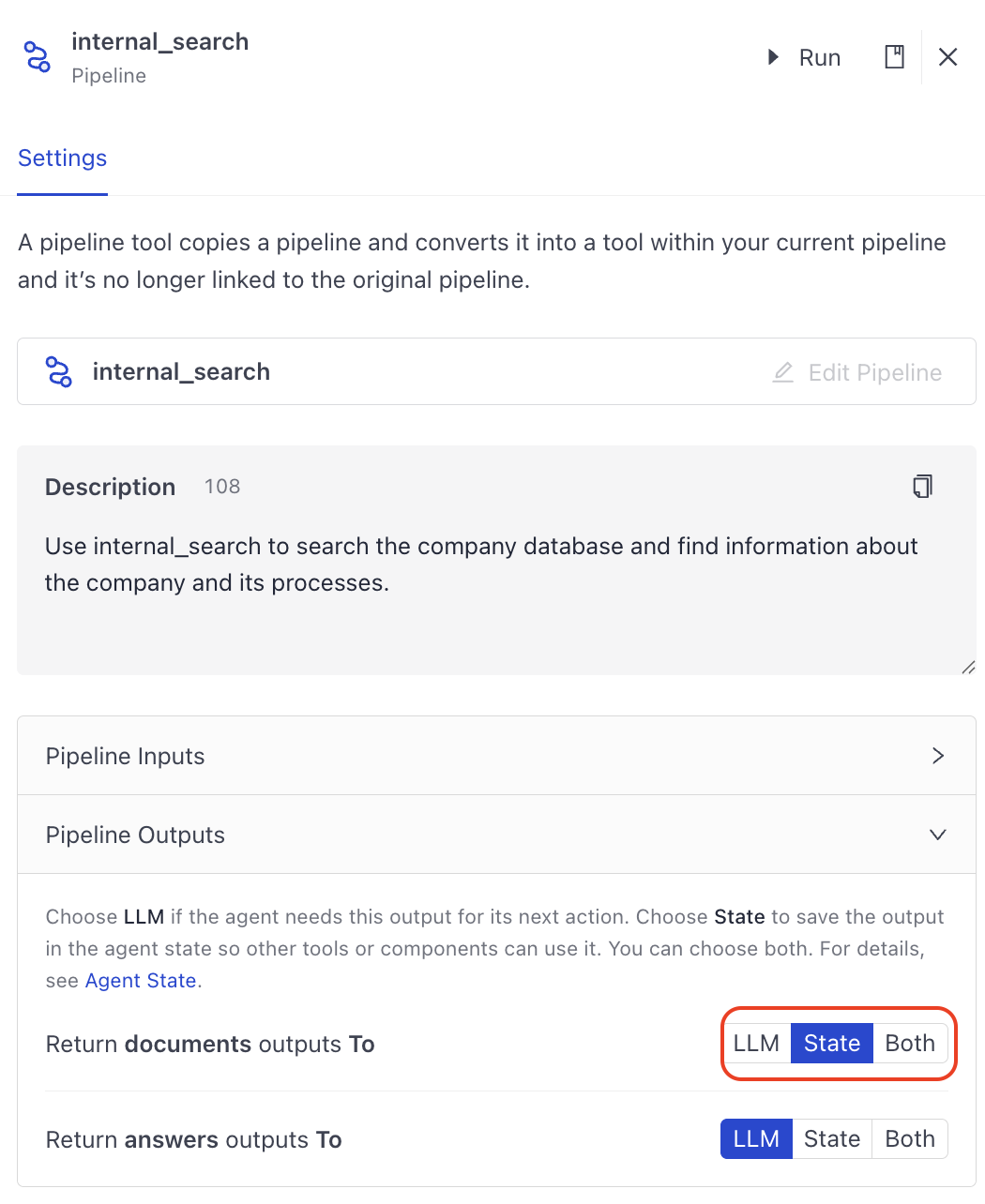
The Agent then outputs the documents through its output connection called documents. You can connect Agent's documents output to the Output component's documents input.
# haystack-pipeline
components:
Agent:
type: haystack.components.agents.agent.Agent
init_parameters:
chat_generator:
init_parameters:
model: gpt-5.2
type: haystack.components.generators.chat.openai_responses.OpenAIResponsesChatGenerator
tools:
- type: haystack.tools.pipeline_tool.PipelineTool
data:
name: internal_search
description: Use internal_search to search the company database and find
information about the company and its processes.
input_mapping:
query:
- retriever.query
- ranker.query
- LLM.question
filters:
- retriever.filters_bm25
- retriever.filters_embedding
files:
- multi_file_converter.sources
output_mapping:
attachments_joiner.documents: documents
LLM.messages: messages
pipeline:
components:
retriever:
type: haystack_integrations.components.retrievers.opensearch.open_search_hybrid_retriever.OpenSearchHybridRetriever
init_parameters:
document_store:
type: haystack_integrations.document_stores.opensearch.document_store.OpenSearchDocumentStore
init_parameters:
hosts:
index: Standard-Index-English
max_chunk_bytes: 104857600
embedding_dim: 768
return_embedding: false
method:
mappings:
settings:
create_index: true
http_auth:
use_ssl:
verify_certs:
timeout:
top_k: 20
fuzziness: 0
embedder:
type: deepset_cloud_custom_nodes.embedders.nvidia.text_embedder.DeepsetNvidiaTextEmbedder
init_parameters:
normalize_embeddings: true
model: intfloat/e5-base-v2
ranker:
type: deepset_cloud_custom_nodes.rankers.nvidia.ranker.DeepsetNvidiaRanker
init_parameters:
model: intfloat/simlm-msmarco-reranker
top_k: 8
meta_field_grouping_ranker:
type: haystack.components.rankers.meta_field_grouping_ranker.MetaFieldGroupingRanker
init_parameters:
group_by: file_id
subgroup_by:
sort_docs_by: split_id
attachments_joiner:
type: haystack.components.joiners.document_joiner.DocumentJoiner
init_parameters:
join_mode: concatenate
weights:
top_k:
sort_by_score: true
multi_file_converter:
type: haystack.core.super_component.super_component.SuperComponent
init_parameters:
input_mapping:
sources:
- file_classifier.sources
is_pipeline_async: false
output_mapping:
score_adder.output: documents
pipeline:
components:
file_classifier:
type: haystack.components.routers.file_type_router.FileTypeRouter
init_parameters:
mime_types:
- text/plain
- application/pdf
- text/markdown
- text/html
- application/vnd.openxmlformats-officedocument.wordprocessingml.document
- application/vnd.openxmlformats-officedocument.presentationml.presentation
- application/vnd.openxmlformats-officedocument.spreadsheetml.sheet
- text/csv
text_converter:
type: haystack.components.converters.txt.TextFileToDocument
init_parameters:
encoding: utf-8
pdf_converter:
type: haystack.components.converters.pdfminer.PDFMinerToDocument
init_parameters:
line_overlap: 0.5
char_margin: 2
line_margin: 0.5
word_margin: 0.1
boxes_flow: 0.5
detect_vertical: true
all_texts: false
store_full_path: false
markdown_converter:
type: haystack.components.converters.txt.TextFileToDocument
init_parameters:
encoding: utf-8
html_converter:
type: haystack.components.converters.html.HTMLToDocument
init_parameters:
extraction_kwargs:
output_format: markdown
target_language:
include_tables: true
include_links: true
docx_converter:
type: haystack.components.converters.docx.DOCXToDocument
init_parameters:
link_format: markdown
pptx_converter:
type: haystack.components.converters.pptx.PPTXToDocument
init_parameters: {}
xlsx_converter:
type: haystack.components.converters.xlsx.XLSXToDocument
init_parameters: {}
csv_converter:
type: haystack.components.converters.csv.CSVToDocument
init_parameters:
encoding: utf-8
splitter:
type: haystack.components.preprocessors.document_splitter.DocumentSplitter
init_parameters:
split_by: word
split_length: 250
split_overlap: 30
respect_sentence_boundary: true
language: en
score_adder:
type: haystack.components.converters.output_adapter.OutputAdapter
init_parameters:
template: >-
{%- set scored_documents = [] -%}
{%- for document in documents -%}
{%- set doc_dict = document.to_dict() -%}
{%- set _ = doc_dict.update({'score': 100.0}) -%}
{%- set scored_doc = document.from_dict(doc_dict) -%}
{%- set _ = scored_documents.append(scored_doc) -%}
{%- endfor -%}
{{ scored_documents }}
output_type: List[haystack.Document]
custom_filters:
unsafe: true
text_joiner:
type: haystack.components.joiners.document_joiner.DocumentJoiner
init_parameters:
join_mode: concatenate
sort_by_score: false
tabular_joiner:
type: haystack.components.joiners.document_joiner.DocumentJoiner
init_parameters:
join_mode: concatenate
sort_by_score: false
connections:
- sender: file_classifier.text/plain
receiver: text_converter.sources
- sender: file_classifier.application/pdf
receiver: pdf_converter.sources
- sender: file_classifier.text/markdown
receiver: markdown_converter.sources
- sender: file_classifier.text/html
receiver: html_converter.sources
- sender: file_classifier.application/vnd.openxmlformats-officedocument.wordprocessingml.document
receiver: docx_converter.sources
- sender: file_classifier.application/vnd.openxmlformats-officedocument.presentationml.presentation
receiver: pptx_converter.sources
- sender: file_classifier.application/vnd.openxmlformats-officedocument.spreadsheetml.sheet
receiver: xlsx_converter.sources
- sender: file_classifier.text/csv
receiver: csv_converter.sources
- sender: text_joiner.documents
receiver: splitter.documents
- sender: text_converter.documents
receiver: text_joiner.documents
- sender: pdf_converter.documents
receiver: text_joiner.documents
- sender: markdown_converter.documents
receiver: text_joiner.documents
- sender: html_converter.documents
receiver: text_joiner.documents
- sender: pptx_converter.documents
receiver: text_joiner.documents
- sender: docx_converter.documents
receiver: text_joiner.documents
- sender: xlsx_converter.documents
receiver: tabular_joiner.documents
- sender: csv_converter.documents
receiver: tabular_joiner.documents
- sender: splitter.documents
receiver: tabular_joiner.documents
- sender: tabular_joiner.documents
receiver: score_adder.documents
LLM:
type: haystack.components.generators.chat.llm.LLM
init_parameters:
chat_generator:
init_parameters:
model: gpt-5.4
type: haystack.components.generators.chat.openai_responses.OpenAIResponsesChatGenerator
system_prompt: ""
user_prompt: >-
{% message role="user" %}
You are a technical expert.
You answer questions truthfully based on provided documents.
If the answer exists in several documents, summarize them.
Ignore documents that don't contain the answer to the
question.
Only answer based on the documents provided. Don't make
things up.
If no information related to the question can be found in
the document, say so.
Always use references in the form [NUMBER OF DOCUMENT] when
using information from a document, e.g. [3] for Document [3]
.
Never name the documents, only enter a number in square
brackets as a reference.
The reference must only refer to the number that comes in
square brackets after the document.
Otherwise, do not use brackets in your answer and reference
ONLY the number of the document without mentioning the word
document.
These are the documents:
{%- if documents|length > 0 %}
{%- for document in documents %}
Document [{{ loop.index }}] :
Name of Source File: {{ document.meta.file_name }}
{{ document.content }}
{% endfor -%}
{%- else %}
No relevant documents found.
Respond with "Sorry, no matching documents were found,
please adjust the filters or try a different question."
{% endif %}
Question: {{ question }}
Answer:
{% endmessage %}
required_variables: "*"
streaming_callback:
connections:
- sender: retriever.documents
receiver: ranker.documents
- sender: ranker.documents
receiver: meta_field_grouping_ranker.documents
- sender: multi_file_converter.documents
receiver: attachments_joiner.documents
- sender: meta_field_grouping_ranker.documents
receiver: attachments_joiner.documents
- sender: attachments_joiner.documents
receiver: LLM.documents
max_runs_per_component: 100
metadata: {}
is_pipeline_async: false
inputs_from_state: {}
outputs_to_string:
messages:
source: messages
outputs_to_state:
documents:
source: documents
parameters:
$defs:
ByteStream:
properties:
data:
description: The binary data stored in Bytestream.
format: binary
type: string
meta:
additionalProperties: true
default: {}
description: Additional metadata to be stored with the ByteStream.
type: object
mime_type:
anyOf:
- type: string
- type: 'null'
default:
description: The mime type of the binary data.
required:
- data
type: object
description: "A component that combines: 'retriever': Runs the wrapped pipeline
with the provided inputs., 'ranker': Returns a list of documents
ranked by their similarity to the given query., 'LLM': Process
messages and generate a response from the language model.,
'multi_file_converter': Runs the wrapped pipeline with the
provided inputs."
properties:
query:
description: "Provided to the 'ranker' component as: 'The input query to compare
the documents to.', and Provided to the 'answer_builder'
component as: 'The query used in the prompts for the
Generator.'."
type: string
filters:
description: Input 'filters' for the component.
anyOf:
- additionalProperties: true
type: object
- type: "null"
files:
description: Input 'files' for the component.
items:
anyOf:
- type: string
- format: path
type: string
- $ref: '#/$defs/ByteStream'
type: array
required:
- query
- files
type: object
_meta:
name: internal_search
description: Use internal_search to search the company database and find
information about the company and its processes.
tool_id:
system_prompt: >-
{% message role="system" %}
You are a deep research assistant.
You create comprehensive research reports to answer the user's
questions.
You use the 'internal_search' tool to answer any questions about the
company and its processes.
You perform multiple searches until you have the information you need to
answer the question.
Make sure you research different aspects of the question.
Use markdown to format your response.
When answering, cite your sources using markdown links.
It is important that you cite accurately.
{% endmessage %}
exit_conditions:
state_schema:
documents:
type: list[haystack.dataclasses.document.Document]
_meta:
used_by:
internal_search: output
max_agent_steps: 100
streaming_callback:
raise_on_tool_invocation_failure: false
tool_invoker_kwargs:
connections: []
max_runs_per_component: 100
metadata: {}
inputs:
messages:
- Agent.messages
outputs:
documents: Agent.documents
messages: Agent.messages
Parameters
Inputs
| Parameter | Type | Default | Description |
|---|---|---|---|
| messages | Optional[List[ChatMessage]] | None | List of Haystack ChatMessage objects to process. Optional if the Agent has a user_prompt or system_prompt configured. If a list of dictionaries is provided, each dictionary is converted into a ChatMessage object. |
| streaming_callback | Optional[StreamingCallbackT] | None | A callback function to invoke when a response is streamed from the LLM. You can configure the same callback function for emitting tool results when the agent calls a tool. |
| system_prompt | Optional[str] | None | System prompt for this specific run. Supports Jinja2 message template syntax for dynamic content. If provided, it overrides the default system prompt configured during initialization. This allows you to dynamically adjust the Agent's behavior for different queries. |
| tools | Optional[Union[List[Tool], Toolset, List[str]]] | None | Optional list of Tool objects, a Toolset, or list of tool names to use for this run. When passing tool names, tools are selected from the Agent's originally configured tools. This allows you to dynamically select which tools the Agent uses at query time. |
| kwargs | Any | Additional inputs forwarded to the Agent's state. The keys must match the schema defined in the Agent's state_schema. |
Outputs
| Output | Type | Description |
|---|---|---|
| messages | List[ChatMessage] | Complete conversation history including all messages from the Agent run: user messages, LLM responses, tool calls, and tool results. |
| last_message | ChatMessage | The final message from the Agent run, typically containing the LLM's final response. This is useful when you only need the final result. |
| Additional state outputs | Varies | Any fields defined in state_schema are also returned as outputs (for example, documents, repository). |
Unlike a ChatGenerator, which returns only the final message, the Agent returns all messages generated during the process. This includes the messages provided as input.|
Init Parameters
These are the parameters you can configure in Pipeline Builder:
| Parameter | Type | Default | Description |
|---|---|---|---|
| chat_generator | ChatGenerator | The chat generator that the agent will use. You configure the generator by passing its init parameters and type to the Agent. Check the Usage Example section for details. The chat generator must support tools. Each chat generator exposes a SUPPORTED_MODELS class variable that lists the models it supports. | |
| tools | Optional[Union[List[Tool], Toolset]] | None | External tools or toolsets the Agent can use. You can provide individual Tool objects as a list, or organize related tools into a Toolset. |
| system_prompt | Optional[str] | None | System prompt to guide the Agent's behavior. Supports Jinja2 message template syntax with {% message role='system' %}...{% endmessage %} for dynamic content injection at runtime. When using Jinja2 syntax, you can pass variables through required_variables. This can be overridden at runtime by passing a system_prompt parameter to the run method. |
| user_prompt | Optional[str] | None | A reusable Jinja2-templated user prompt. If provided, this is rendered with the given variables and appended to the messages provided at runtime. This lets you invoke the Agent with dynamic inputs without manually constructing ChatMessage objects. Can be overridden at runtime. |
| required_variables | Optional[Union[List[str], Literal["*"]]] | None | List of variables that must be provided as input to the user_prompt or system_prompt. If a required variable is not provided, an exception is raised. Set to "*" to require all variables found in the prompts. |
| exit_conditions | Optional[List[str]] | ["text"] | Defines when the agent stops processing messages. Pass "text" to stop the Agent when it generates a message without tool calls. Pass the name of a tool to stop the Agent after it successfully runs this tool. Multiple exit conditions can be specified, and the Agent stops when any one is met. |
| state_schema | Optional[Dict[str, Any]] | None | Optional schema for managing the runtime state used by tools. It defines extra information—such as documents or context—that tools can read from or write to during execution. You can use this schema to pass parameters that tools can both produce and consume during a call. This means that when a pipeline runs, tools can read from the Agent's state (for example, the current set of retrieved documents) and write into or update this state as they run. |
| max_agent_steps | int | 100 | Maximum number of steps (LLM calls) the Agent runs before stopping. Defaults to 100. If the Agent reaches this limit, it stops execution and returns all messages and state accumulated up to that point. A warning is logged when this limit is reached. Increase this value for complex tasks that require many tool calls. |
| streaming_callback | Optional[StreamingCallbackT] | None | Function invoked for streaming responses. To enable streaming, set streaming_callback to deepset_cloud_custom_nodes.callbacks.streaming.streaming_callback. To learn more about streaming, see Enable Streaming. |
| raise_on_tool_invocation_failure | bool | False | Whether to raise an error when a tool call fails. If set to False, the exception is turned into a chat message and passed to the LLM. |
| tool_invoker_kwargs | Optional[Dict[str, Any]] | None | Additional keyword arguments to pass when invoking a tool. |
Run Method Parameters
These are the parameters you can configure for the component's run() method. This means you can pass these parameters at query time through the API, in Playground, or when running a job. For details, see Modify Pipeline Parameters at Query Time.
| Parameter | Type | Default | Description |
|---|---|---|---|
| messages | Optional[List[ChatMessage]] | None | List of Haystack ChatMessage objects to process. Optional if the Agent has a user_prompt or system_prompt configured. If a list of dictionaries is provided, each dictionary is converted to a ChatMessage object. |
| streaming_callback | Optional[StreamingCallbackT] | None | A function to handle streamed responses. You can configure the same callback function to emit tool results when a tool is called. |
| system_prompt | Optional[str] | None | System prompt for this specific run. Supports Jinja2 message template syntax for dynamic content. If provided, it overrides the default system prompt configured during initialization. This allows you to dynamically adjust the Agent's behavior for different queries. |
| user_prompt | Optional[str] | None | User prompt for this specific run. If provided, it overrides the default user_prompt configured during initialization. The rendered prompt is appended to the provided messages. |
| generation_kwargs | Optional[Dict[str, Any]] | None | Additional keyword arguments for the LLM. These parameters override the parameters passed during component initialization, allowing fine-grained control over chat generation at runtime. |
| tools | Optional[Union[List[Tool], Toolset, List[str]]] | None | Optional list of Tool objects, a Toolset, or list of tool names to use for this run. When passing tool names, tools are selected from the Agent's originally configured tools. This allows you to dynamically select which tools the Agent uses at query time. |
| break_point | Optional[AgentBreakpoint] | None | An AgentBreakpoint, can be a Breakpoint for the "chat_generator" or a ToolBreakpoint for "tool_invoker". Used for debugging and monitoring agent execution. |
| snapshot | Optional[AgentSnapshot] | None | A dictionary containing a snapshot of a previously saved agent execution. The snapshot contains the relevant information to restart the Agent execution from where it left off. |
| kwargs | Any | Additional parameters to pass to the Agent's state_schema. The keys must match the schema defined in the Agent's state_schema. |
Related Information
Was this page helpful?