Writing Prompts in Haystack Enterprise Platform
In Haystack Enterprise Platform, prompts use Jinja2 syntax, which makes it possible to add variables or expressions that are replaced with real values when the template is rendered. This way, you can include dynamic content, like documents and queries, in the prompt.
Jinja Templates
Jinja2 is a templating engine that enables dynamic templates in static content by embedding placeholders, such as variables. These placeholders are filled with actual values when the template is rendered. Jinja2 also supports advanced features like loops and conditionals.
The variables you use in a prompt template correspond to outputs from preceding components in your pipeline. When the pipeline runs, each variable is replaced with the data that flows from the component you connected to that input. For example, if you connect a Retriever to an LLM component, you can add a documents variable to the LLM's prompt. At runtime, that variable is replaced with the actual documents the Retriever returned, because the Retriever outputs documents and passes them to the LLM when they are connected. The same applies to other variables: use the name of the output you want (such as question or query for the user input) and connect the corresponding component so the value is supplied at runtime.
LLM and Agent componentsLLM and Agent components have a rich editor for Jinja2 templates. This applies to both system and user prompts.
When you add or edit a prompt for the LLM component, you write regular text. To insert a variable, type @ and a list of available variables appears so you can pick one. To insert a function, type / and you see all functions you can add to the template.
If you want to type a literal @ or / character instead of opening the list, press Escape after the list appears and the character is inserted into your prompt.
To see the raw Jinja2 syntax, enable the Jinja toggle. It's disabled by default.
To learn more about Jinja2 syntax, see Jinja2 documentation.
Prompt Types
There are two main types of prompts: system prompts and user prompts. Both types support dynamic content through Jinja2 syntax.
System Prompts
System prompts define the LLM's behavior, personality, and operational guidelines. They are used to set the overall behavior, persona, and context for the model. They're applied at the start of every request. These are typically used by Agent and LLM components.
For models that use the ChatMessage format, you type system prompts as ChatMessage objects with the system role.
- content:
- text: |
You are a helpful assistant answering the user's questions.
If the answer is not in the documents, rely on the web_search tool to find information.
Do not use your own knowledge.
role: system
User Prompts
User prompts contain the actual queries or instructions from users. They are commonly used in chat-based pipelines. For models that use the ChatMessage format, user prompts are passsed as ChatMessage objects with the user role.
- content:
- text: |
What is the capital of France?
role: user
Passing a Prompt to the Model
Using the LLM or Agent Components
When using the LLM, you can pass the system and user prompts directly in the component configuration. You can also use Jinja2 syntax to insert variables into the prompt.
System Prompt
You can optionally configure a system prompt for the model to provide fixed instructions that guide its behavior, tone, or knowledge throughout the conversation.
The system prompt supports dynamic content through Jinja2 syntax and a rich Jinja2 editor that makes it easier to insert variables and function.
components:
llm:
type: haystack.components.generators.chat.llm.LLM
init_parameters:
system_prompt: "You are a helpful assistant that answers user's questions."
user_prompt: "Answer the question: {{ query }}"
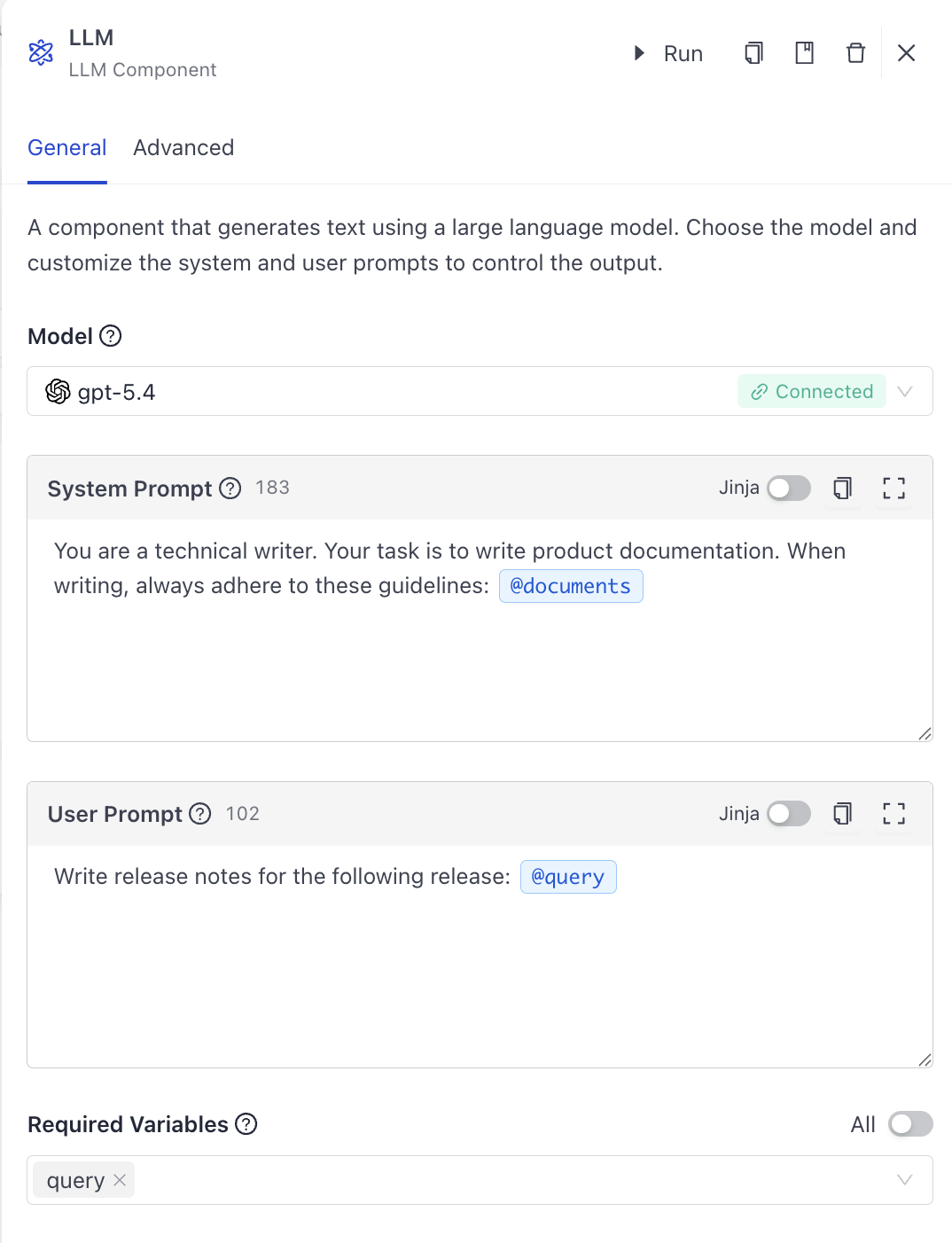
You can only insert variables that the component receives as input from preceding components in the pipeline. In the example above, the LLM can receive the query variable if the Input component's query output is connected to the LLM's messages input.
Similarly, it can receive the documents variable if the Retriever component's documents output is connected to the LLM's documents input.
Using the PromptBuilder and Generator Components
We recommend using the LLM component instead. You can use it instead of PromptBuilder and Generator components. It works with any LLM provider and replaces both components. For details, see LLM.
Click to read the instructions
With this approach, you need two components connected together: PromptBuilder and a Generator. You pass the prompt in PromptBuilder's template parameter. At search time, PromptBuilder renders the template, fills in the variables with real values, and sends the rendered prompt to the Generator.
The Generator is essentially the LLM. There's a Generator for each model provider, for example, OpenAIGenerator, CohereGenerator, and so on. When the pipeline runs, the Generator receives the prompt with all variables filled in and generates a response based on the instructions.
This is an example of using PromptBuilder in Pipeline Builder with a basic prompt template. It contains two variables: question and documents, which will be populated with the user query and retrieved documents and then sent to the Generator:
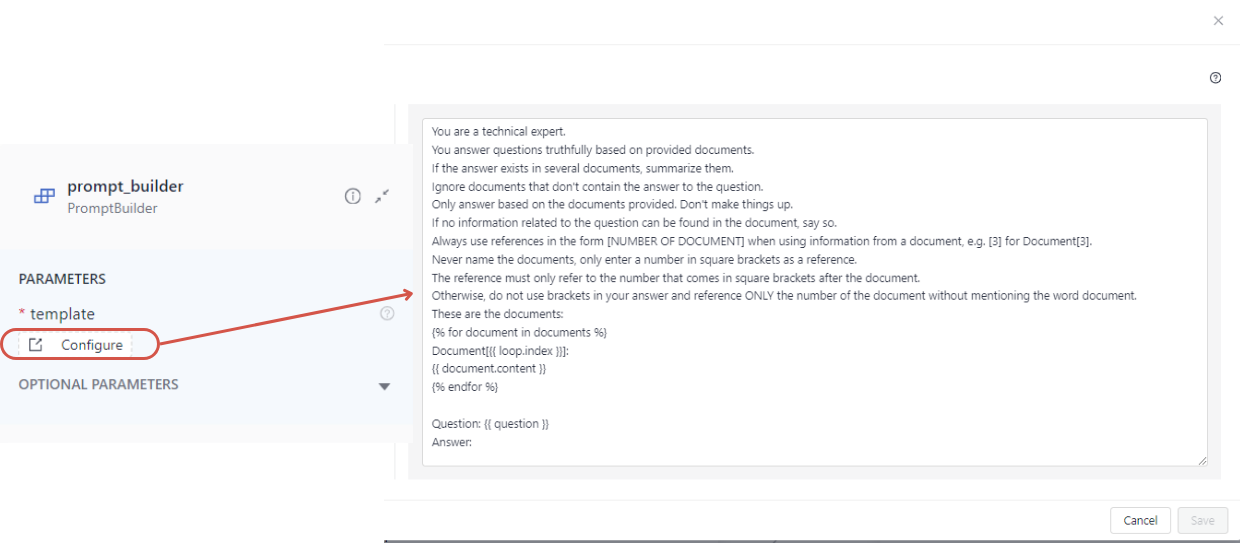
YAML Example: PromptBuilder Template
# ...
prompt_builder:
type: haystack.components.builders.prompt_builder.PromptBuilder
init_parameters:
template: |-
You are a technical expert.
You answer questions truthfully based on provided documents.
If the answer exists in several documents, summarize them.
Ignore documents that don't contain the answer to the question.
Only answer based on the documents provided. Don't make things up.
If no information related to the question can be found in the document, say so.
Always use references in the form [NUMBER OF DOCUMENT] when using information from a document, e.g. [3] for Document[3].
Never name the documents, only enter a number in square brackets as a reference.
The reference must only refer to the number that comes in square brackets after the document.
Otherwise, do not use brackets in your answer and reference ONLY the number of the document without mentioning the word document.
These are the documents:
{% for document in documents %}
Document[{{ loop.index }}]:
{{ document.content }}
{% endfor %}
Question: {{ question }}
Answer:
PromptBuilder requires the user query and the documents as inputs to fill in the prompt. In this example, it receives user query from the Input component and documents from the Ranker component (or any other component providing documents):
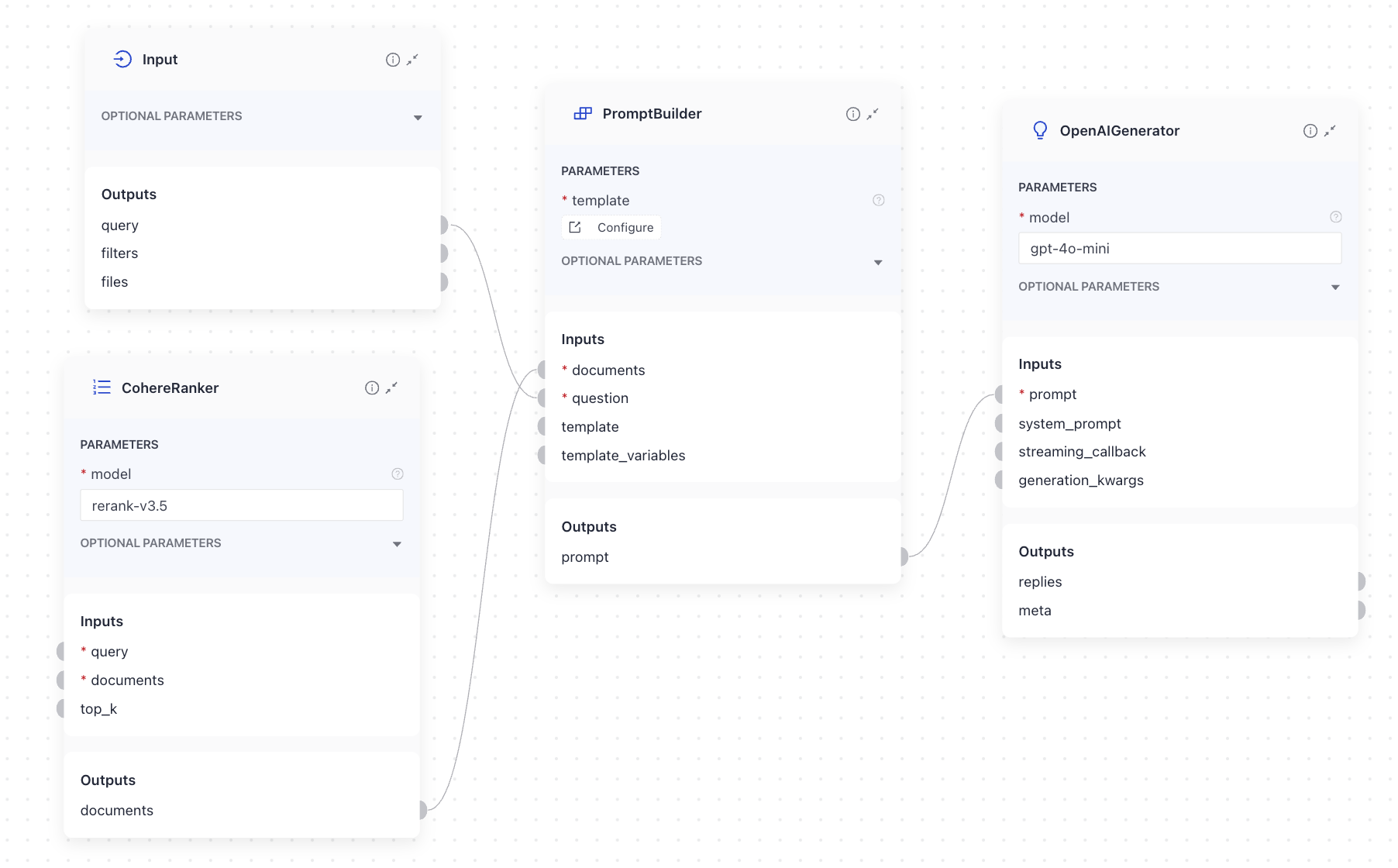
YAML Example: Pipeline Connections
connections:
# ...
- sender: ranker.documents
receiver: prompt_builder.documents
- sender: prompt_builder.prompt
receiver: llm.prompt
max_loops_allowed: 100
metadata: {}
inputs:
query:
- prompt_builder.question
For more on variables, see the Adding Variables to Prompts section below.
ChatPromptBuilder and ChatGenerator
This is a legacy approach and will be deprecated in future releases. We recommend using the LLM component instead. It works with any LLM provider and replaces both ChatPromptBuilder and ChatGenerator components. For details, see LLM.
Click to read the instructions
ChatGenerators receive the prompt from ChatPromptBuilder. You can configure the prompt using ChatPromptBuilder's template parameter. ChatGenerators require a list of ChatMessage objects as input, which means the format of the prompt must comply with the ChatMessage format:
- content:
- content_type: # replace this with the content type, supported content types are: text, tool_call, tool_call_result
# content may contain variables
role: role # supported roles are: user, system, assistant, tool`
If you set content_type to text, it accepts Jinja2 syntax and you can pass variables in your prompt. The variables then become the required input for the component.
Example ChatPromptBuilder Prompt
This is an example of a ChatPromptBuilder template. The first ChatMessage contains text and is for the system role. These are the instructions for the model that set the general tone and purpose of the conversation.
The second ChatMessage is the user query. Note that we're also passing the retrieved documents to the model in this message.
There are two variables in this prompt: query and documents, they become the required input for ChatPromptBuilder. This means it must be connected to the Input component and to a component that produces the documents.
- content:
- text: |
You are a helpful assistant answering the user's questions based on the provided documents.
If the answer is not in the documents, rely on the web_search tool to find information.
In this case you must pass the user's question as query to the web_search tool.
Do not use your own knowledge.
role: system
- content:
- text: | # this makes it possible to use Jinja2 syntax
Provided documents:
{% for document in documents %}
Document [{{ loop.index }}] :
{{ document.content }}
{% endfor %}
Question: {{ query }}
role: user
As you can see, ChatMessages can also contain variables, just like regular prompts, if the content_type is text.
For details on ChatMessage, see Haystack documentation.
ChatPromptBuilder with Jinja2 Template Syntax
You can also pass ChatMessages as Jinja2 strings using the {% message %} tag. This makes it possible to test prompts in ChatPromptBuilder through Prompt Explorer. For example, this ChatPromptBuilder contains instructions for follow up question classification and rewriting queries at the start of the pipeline. There are two chat messages, one with role "system" and another one with role "assistant". It also includes chat history.
{% message role="system" %}
You are a helpful assistant.
{% endmessage %}
{% message role="user" %}
Hello! My name is {{user_name}}.
{% endmessage %}
Adding Variables to Prompts
You can use Jinja2 syntax to insert variables into your prompts. Each variable is replaced with real values when the pipeline runs. The values come from the components that are connected upstream in your pipeline: whatever a component outputs (for example, documents from a Retriever, or query from the Input component) can be used as a variable in the prompt, as long as the components are connected so that the prompt receives the values at runtime. The prompt template is rendered with these values and then the final prompt is sent to the LLM.
For example, in this prompt, the variable {{ question }} is a placeholder for the user query:
You are a technical expert.
You answer questions truthfully based on your knowledge.
Ignore typing errors in the question.
Question: {{ question }}
Answer:
In this example, prompt needs the query. In Builder, you simply connect the Input component's query output to the prompt's question input:
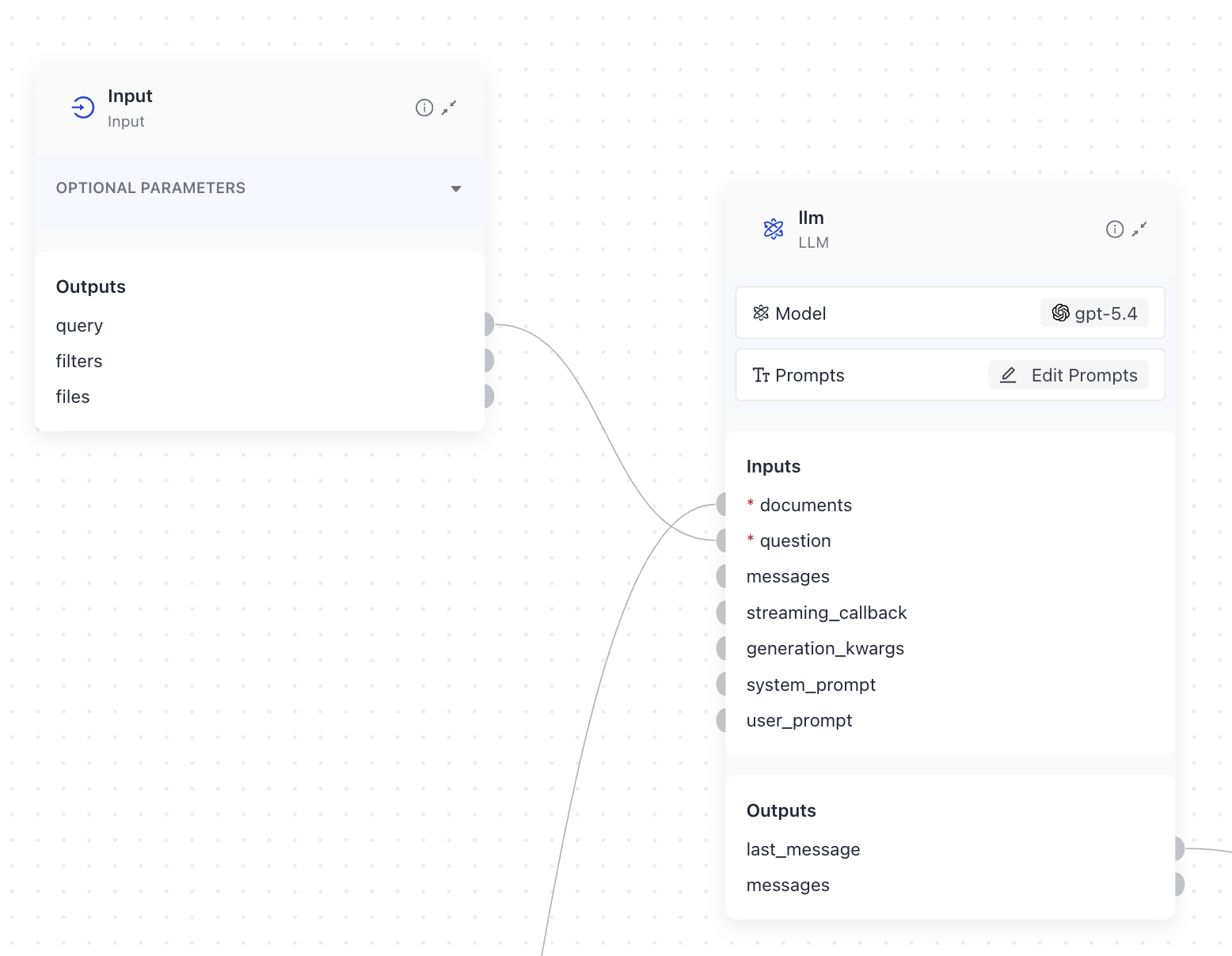
The variable name in the template must match the input name. Use the at (@) symbol to see all available variables and add them to your prompt.
At search time, {{ question }} is replaced with the actual user query:
You are a technical expert.
You answer questions truthfully based on your knowledge.
Ignore typing errors in the question.
Question: what was wynton kelly famous for?
Answer:
Required and Optional Variables
By default, all variables in the template are considered optional. If they're not provided, they're replaced with empty strings.
Required Variables
You can indicate which variables are required and must be provided when the component is executed by listing them in the Required Variables field on the component card. If you do this, then the pipeline returns an error if any of the required variables is not provided at run time.
Choose the variables from a list or choose All to make all variables in the prompt required.
Additional Variables
Use the variables parameter to define the full set of template variables that the component expects or can accept. If you don't set the variables explicitly, the component infers them by parsing the Jinja2 syntax from the template parameter.
To define variables beyond those in the default template, for example for dynamic prompt switching or prompt engineering, you can set them manually in the variables parameter. These variables then become the inputs for the component.
Variables with Attributes
When adding a variable, you can reference its attributes to include them in the prompt. For example, you might want to use attributes from the document object, such as:
idcontentmeta(metadata key)score
To reference these attributes, use the syntax: <object>.<attribute>. For attributes like meta, you can specify the key you want. For instance, to include the date_created metadata key, use: document.meta.date_created.
This Jinja2 expression adds the document's score, content, and date_created metadata key to the prompt:
You are a technical expert.
You answer questions truthfully based on provided documents.
If the answer exists in several documents, summarize them.
Ignore documents that don't contain the answer to the question.
Only answer based on the documents provided. Don't make things up.
If no information related to the question can be found in the document, say so.
Always use references in the form [NUMBER OF DOCUMENT] when using information from a document, e.g. [3] for Document[3].
Never name the documents, only enter a number in square brackets as a reference.
The reference must only refer to the number that comes in square brackets after the document.
Otherwise, do not use brackets in your answer and reference ONLY the number of the document without mentioning the word document.
Here are the documents:
{% for document in documents %}
Document[{{ loop.index }}]:
Date created: {{ document.meta.date_created }}
{{ document.content }}
{% endfor %}
Question: {{ question }}
Answer:
Rendered prompt
You are a technical expert.
You answer questions truthfully based on provided documents.
If the answer exists in several documents, summarize them.
Ignore documents that don't contain the answer to the question.
Only answer based on the documents provided. Don't make things up.
If no information related to the question can be found in the document, say so.
Always use references in the form [NUMBER OF DOCUMENT] when using information from a document, e.g. [3] for Document[3].
Never name the documents, only enter a number in square brackets as a reference.
The reference must only refer to the number that comes in square brackets after the document.
Otherwise, do not use brackets in your answer and reference ONLY the number of the document without mentioning the word document.
Here are the documents:
Document[1]:
Date created: 19-Aug-2004
deepset_platform_metadata:
group: how-tos
navigation: guides
section: working-with-llms
source: docusaurus-build
title: writing-prompts-in-deepsetq
type: how-to
---
More Than One Way To Do It
deepset_platform_metadata:
group: how-tos
navigation: guides
section: working-with-llms
source: docusaurus-build
title: writing-prompts-in-deepsetq
type: how-to
---
Okay, the Zen doesn't say that there should be Only One Way To Do It.
But it does have a prohibition against allowing "more than one way to
do it".
''''''''Response
''''''''
There is no such prohibition. The "Zen of Python" merely expresses a
*preference* for "only one *obvious* way"::
There should be one-- and preferably only one --obvious way to do
it.
The emphasis here is that there should be an obvious way to do "it".
In the case of dict update operations, there are at least two
different operations that we might wish to do:
- *Update a dict in place*: The Obvious Way is to use the ``update()``
method. If this proposal is accepted, the ``|=`` augmented
assignment operator will also work, but that is a side-effect of how
augmented assignments are defined. Which you choose is a matter of
taste.
- *Merge two existing dicts into a third, new dict*: This PEP proposes
that the Obvious Way is to use the ``|`` merge operator.
In practice, this preference for "only one way" is frequently violated
in Python. For example, every ``for`` loop could be re-written as a
``while`` loop; every ``if`` block could be written as an ``if``/
``else`` block. List, set and dict comprehensions could all be
replaced by generator expressions.
Document[2]:
Date created: 19-Aug-2004
PEP: 20
Title: The Zen of Python
Author: Tim Peters <tim.peters@gmail.com>
Status: Active
Type: Informational
Content-Type: text/x-rst
Post-History: 22-Aug-2004
Abstract
========
Long time Pythoneer Tim Peters succinctly channels the BDFL's guiding
principles for Python's design into 20 aphorisms, only 19 of which
have been written down.
The Zen of Python
=================
.. code-block:: text
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren't special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you're Dutch.
Now is better than never.
Although never is often better than *right* now.
If the implementation is hard to explain, it's a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea -- let's do more of those!
Easter Egg
==========
.. code-block:: pycon
>>> import this
References
==========
Originally posted to comp.lang.python/python-list@python.org under a
thread called `"The Way of Python"
<https://groups.google.com/d/msg/comp.lang.python/B_VxeTBClM0/L8W9KlsiriUJ>`__
Copyright
=========
This document has been placed in the public domain.
Document[3]:
Date created: 19-Aug-2004
The trio is not expected to preach/advertise for
Python. They can if they want to, but not expected.
- Not an educator of Python. The trio is not expected to be the ones teaching/writing
about Python. They can if they want to, but not expected.
- The trio is not expected to be available 24/7, 365 days a year. They are free
to decide for themselves their availability for Python.
- Not a PEP editor.
Guidelines for the formation of the trio
========================================
The success of this governance model relies on the members of the trio, and the
ability of the trio members to collaborate and work well together.
The three people need to have similar vision to Python, and each can have
different skills that complement one another.
With such a team, disagreements and conflict should be rare, but can still happen.
We will need to trust the people we select that they are able to resolve this among
themselves.
When it comes to select the members of the trio, instead of nominating various
individuals and choosing the top three, core developers will nominate trios
and vote for groups of threes who they believe can form this united trio. There
is no restriction that an individual can only be nominated in one slate.
This PEP will not name or nominate anyone into the trio.
Only once this PEP is accepted, any active core developers (who are eligible to vote)
can submit nomination of groups of three.
Document[4]:
Date created: 19-Aug-2004
Typically only exceptions that
signal an error are desired to be caught. This means that exceptions
that are used to signify that the interpreter should exit should not
be caught in the common case.
With KeyboardInterrupt and SystemExit moved to inherit from
BaseException instead of Exception, changing bare ``except`` clauses
to act as ``except Exception`` becomes a much more reasonable
default. This change also will break very little code since these
semantics are what most people want for bare ``except`` clauses.
The complete removal of bare ``except`` clauses has been argued for.
The case has been made that they violate both Only One Way To Do It
(OOWTDI) and Explicit Is Better Than Implicit (EIBTI) as listed in the
:pep:`Zen of Python <20>`. But Practicality Beats Purity (PBP), also in
the Zen of Python, trumps both of these in this case. The BDFL has
stated that bare ``except`` clauses will work this way
[#python-dev8]_.
Implementation
deepset_platform_metadata:
group: how-tos
navigation: guides
section: working-with-llms
source: docusaurus-build
title: writing-prompts-in-deepsetq
type: how-to
---
The compiler will emit the bytecode for ``except Exception`` whenever
a bare ``except`` clause is reached.
Transition Plan
===============
Because of the complexity and clutter that would be required to add
all features planned in this PEP, the transition plan is very simple.
In Python |2.x| BaseException is added. In Python 3.0, all remaining
features (required superclass, change in inheritance, bare ``except``
clauses becoming the same as ``except Exception``) will go into
affect.
Document[5]:
Date created: 19-Aug-2004
* random_bytes - returns a random byte string.
* random_number - depending on the argument, returns either a random
integer in the range(0, n), or a random float between 0.0 and 1.0.
* urlsafe_base64 - returns a random URL-safe Base64 encoded string.
* uuid - return a version 4 random Universally Unique IDentifier.
What Should Be The Name Of The Module?
======================================
There was a proposal to add a "random.safe" submodule, quoting the Zen
of Python "Namespaces are one honking great idea" koan. However, the
author of the Zen, Tim Peters, has come out against this idea [#]_, and
recommends a top-level module.
In discussion on the python-ideas mailing list so far, the name "secrets"
has received some approval, and no strong opposition.
There is already an existing third-party module with the same name [#]_,
but it appears to be unused and abandoned.
Frequently Asked Questions
==========================
* Q: Is this a real problem? Surely MT is random enough that nobody can
predict its output.
A: The consensus among security professionals is that MT is not safe
in security contexts. It is not difficult to reconstruct the internal
state of MT [#]_ [#]_ and so predict all past and future values. There
are a number of known, practical attacks on systems using MT for
randomness [#]_.
* Q: Attacks on PHP are one thing, but are there any known attacks on
Python software?
A: Yes. There have been vulnerabilities in Zope and Plone at the very
least.
Document[6]:
Date created: 19-Aug-2004
If a
developer knows that her package will never be a portion of a
namespace package, then there is a performance advantage to it being a
regular package (with an ``__init__.py``). Creation and loading of a
regular package can take place immediately when it is located along
the path. With namespace packages, all entries in the path must be
scanned before the package is created.
Note that an ImportWarning will no longer be raised for a directory
lacking an ``__init__.py`` file. Such a directory will now be
imported as a namespace package, whereas in prior Python versions an
ImportWarning would be raised.
Alyssa (Nick) Coghlan presented a list of her objections to this proposal [4]_.
They are:
1. Implicit package directories go against the Zen of Python.
2. Implicit package directories pose awkward backwards compatibility
challenges.
3. Implicit package directories introduce ambiguity into file system
layouts.
4. Implicit package directories will permanently entrench current
newbie-hostile behavior in ``__main__``.
Alyssa later gave a detailed response to her own objections [5]_, which
is summarized here:
1. The practicality of this PEP wins over other proposals and the
status quo.
2. Minor backward compatibility issues are okay, as long as they are
properly documented.
3. This will be https://www.iana.org/assignments/media-types/application/vnd.openxmlformats-officedocument.wordprocessingml.documented in :pep:`395`.
4. This will also be https://www.iana.org/assignments/media-types/application/vnd.openxmlformats-officedocument.wordprocessingml.documented in :pep:`395`.
The inclusion of namespace packages in the standard library was
motivated by Martin v. Löwis, who wanted the ``encodings`` package to
become a namespace package [6]_.
Document[7]:
Date created:
* A nearly-identical syntax is already established for f-strings.
* Programmers will, as ever, adjust over time.
The feature is confusing
deepset_platform_metadata:
group: how-tos
navigation: guides
section: working-with-llms
source: docusaurus-build
title: writing-prompts-in-deepsetq
type: how-to
---
We argue that:
* Introducing new features typically has this impact temporarily.
* The syntax is very similar to the established ``f'{x=}'`` syntax.
* The feature and syntax are familiar from other popular modern languages.
* The expansion of ``x=`` to ``x=x`` is in fact a trivial feature and inherently
significantly less complex than ``*arg`` and ``**kwarg`` expansion.
* This particular syntactic form has been independently proposed on numerous
occasions, indicating that it is the most obvious [1]_ [2]_ [6]_.
The feature is not explicit
deepset_platform_metadata:
group: how-tos
navigation: guides
section: working-with-llms
source: docusaurus-build
title: writing-prompts-in-deepsetq
type: how-to
---
We recognize that, in an obvious sense, the argument value is 'implicit' in this
proposed syntax. However, we do not think that this is what the Zen of Python is
aiming to discourage.
In the sense that we take the Zen to be referring to, keyword arguments (for
example) are more explicit than positional arguments where the argument name is
omitted and impossible to tell from the local context. Conversely, the syntactic
sugar for integers ``x += 1`` is not more implicit than ``x = x + 1`` in this
sense, even though the variable is omitted from the right hand side, because it
is immediately obvious from the local context what it is.
Document[8]:
Date created: 19-Aug-2004
- Provide vision and leadership for Python, the programming language and the community.
- Understand their own limitation, and seek advice whenever necessary.
- Provide mentorship to the next generation of leaders.
- Be a Python core developer
- Be a voting member of The PSF (one of Contributing / Manager / Fellow / Supporter). [2]_
- Understand that Python is not just a language but also a community. They need
to be aware of issues in Python not just the technical aspects, but also
other issues in the community.
- Facilitate the formation of specialized working groups within Core Python.
See "formation of specialized working groups" section below.
- Set good example of behavior, culture, and tone to Python community.
Just as Python looks at and learn from other communities for inspiration, other
communities will look at Python and learn from us.
Authority of the trio
=====================
To be clear, in case any dispute arises: the trio has the final
authority to pronounce on PEPs (except for the governance PEP), to
decide whether a particular decision requires a PEP, and to resolve
technical disputes in general. The trio's authority does not include
changing the governance itself, or other non-technical disputes that
may arise; these should be handled through the process described in
:pep:`8001`.
What are NOT considered as the role responsibilities of the trio
================================================================
The following are not the expected out of the trio, however they can do these if they wish.
Question: what are the three zens of python?
Answer:
For a complete list of document's attributes, see Haystack documentation.
Adding Dates to Prompts
You can use the Jinja2 time extension to insert dates in your prompts.
Adding the Current Date
You can use the {% now %} tag to render the current date and time in your prompts. The syntax is: {% now [timezone] %}. Type / in the prompt editor and choose Now (Current Time) to insert the tag. You can then choose the timezone and format of the date.
For example: The current time is: {% now 'CEST' %}. This renders as: The current time is 2025-05-06 17:03:12.
Storing the Date as a Variable
Use the following syntax to set a variable name for the date: The current time is {% now 'Europe/Berlin' as current_time %}. current_time becomes the name of the variable for the current time.
When using rich editor, simply type the variable name in the As field:

Formatting the Date
You can configure how the date is rendered in your prompts using strftime. When using rich editor, type the expected format in the format field. When using Jinja2 syntax:
- Declare the current date as a variable.
- Use
strftimewith this variable.
For example, in this prompt template, we want the date to show in the following format: YYY-MM-DD HH:MM:
- content:
- text: |-
{% now 'Europe/Berlin' as current_time %}
Session started at {{ current_time.strftime('%Y-%m-%d %H:%M') }}
role: system
- content:
- text: Can you show me all events from {{ current_time }}?
role: user
Here's a cheat sheet of useful format codes you can use with strftime:
| Code | Meaning | Example |
|---|---|---|
| %Y | Year (4 digits) | 2025 |
| %y | Year (2 digits) | 25 |
| %m | Month (01–12) | 05 |
| %B | Full month name | May |
| %b | Abbreviated month name | May |
| %d | Day of the month | 06 |
| %A | Full weekday name | Tuesday |
| %a | Abbreviated weekday | Tue |
| %H | Hour (24-hour clock) | 16 |
| %I | Hour (12-hour clock) | 04 |
| %p | AM/PM | PM |
| %M | Minute | 47 |
| %S | Second | 09 |
| %z | UTC offset | +0200 |
| %Z | Timezone abbreviation | CEST |
Examples
Documents in Prompts
Make sure the component with the prompt template receives documents as input from the component that precedes it.
In RAG systems, you want the LLM to generate answers based on specific documents. You can pass these documents to the LLM by adding them as a variable in the prompt template. There are a couple of ways to do this. The simplest way is simply adding a {{ documents }} variable to your prompt, as in this example:
You are a technical expert.
You answer questions truthfully based on provided documents.
If the answer exists in several documents, summarize them.
Ignore documents that don't contain the answer to the question.
Only answer based on the documents provided. Don't make things up.
If no information related to the question can be found in the document, say so.
Always use references in the form [NUMBER OF DOCUMENT] when using information from a document, e.g. [3] for Document[3].
Never name the documents, only enter a number in square brackets as a reference.
The reference must only refer to the number that comes in square brackets after the document.
Otherwise, do not use brackets in your answer and reference ONLY the number of the document without mentioning the word document.
These are the documents:
{{ documents }}
Question: {{ question }}
Answer:
This results in documents being passed to the LLM as one long string, often making it difficult to ground its answer in them.
Rendered prompt
You are a technical expert.
You answer questions truthfully based on provided documents.
If the answer exists in several documents, summarize them.
Ignore documents that don't contain the answer to the question.
Only answer based on the documents provided. Don't make things up.
If no information related to the question can be found in the document, say so.
Always use references in the form [NUMBER OF DOCUMENT] when using information from a document, e.g. [3] for Document[3].
Never name the documents, only enter a number in square brackets as a reference.
The reference must only refer to the number that comes in square brackets after the document.
Otherwise, do not use brackets in your answer and reference ONLY the number of the document without mentioning the word document.
These are the documents:
[Document(id=e307dd3c6f765aed116ad81d064dc8188d410481927309cd42b44ed8e22bb25e, content: '--------------------------
More Than One Way To Do It
deepset_platform_metadata:
group: how-tos
navigation: guides
section: working-with-llms
source: docusaurus-build
title: writing-prompts-in-deepsetq
type: how-to
---
Okay, the Zen does...', meta: {'_split_overlap': [{'range': [1073, 1363], 'doc_id': '92d2764f063333fee7cf76d86254acb2752934ea07d2364c2b6eb209bb5cc739'}, {'range': [0, 223], 'doc_id': 'b44519a3df1ca77a0515c579ec00ad297dee50be90cb3eb3736e3716e80490c0'}], 'split_idx_start': 9309, 'file_name': 'pep-0584.txt', '_file_created_at': '2024-10-18T09:03:45.832385+00:00', 'split_id': 8, '_file_size': 30734, 'page_number': 1, 'file_id': '679bbf37-4cb9-4583-9f02-51289283bcd4', 'source_id': '982a93602209b5c2df80f37d9018d5a958aaf85e5f22a48e22d0f3970368d619'}, score: 0.158935546875), Document(id=a279b61737eef5529a0b27b2b97de0d4925c6509e8f00b1f37682a056371e50b, content: 'PEP: 20
Title: The Zen of Python
Author: Tim Peters <tim.peters@gmail.com>
Status: Active
Type: Info...', meta: {'_split_overlap': [], 'split_idx_start': 0, 'file_name': 'pep-0020.txt', '_file_created_at': '2024-10-18T09:04:17.099685+00:00', 'split_id': 0, '_file_size': 1673, 'page_number': 1, 'file_id': '66633e10-67b1-4210-ab81-f22b162da69f', 'source_id': 'd4398d899e10248f3615dfc523283ebdd06cc9d4ba7349bc2dfc0dabc7310e9f'}, score: 0.132568359375), Document(id=92d2764f063333fee7cf76d86254acb2752934ea07d2364c2b6eb209bb5cc739, content: 'If one expects to be merging a large number of dicts where performance
is an issue, it may be better...', meta: {'_split_overlap': [{'range': [1172, 1531], 'doc_id': 'c6070df4a665dea988466251522ab286451f86e8d67e821484365fbe860dc522'}, {'range': [0, 290], 'doc_id': 'e307dd3c6f765aed116ad81d064dc8188d410481927309cd42b44ed8e22bb25e'}], 'split_idx_start': 8236, 'file_name': 'pep-0584.txt', '_file_created_at': '2024-10-18T09:03:45.832385+00:00', 'split_id': 7, '_file_size': 30734, 'page_number': 1, 'file_id': '679bbf37-4cb9-4583-9f02-51289283bcd4', 'source_id': '982a93602209b5c2df80f37d9018d5a958aaf85e5f22a48e22d0f3970368d619'}, score: 0.04217529296875), Document(id=de665889f31c7e28b722106a5fa445dea020cb5b1deadb5ff87a200dccbca64b, content: '* A nearly-identical syntax is already established for f-strings.
* Programmers will, as ever, adjus...', meta: {'_split_overlap': [{'range': [1300, 1547], 'doc_id': 'cbda35aa73c0e994987f1df6aa33996b3e6bfee5d37fe00b43c74a3389dcb78d'}, {'range': [0, 243], 'doc_id': '855465dc4e9941a1b50d267d7f23d61378288a60c87769ea2fe3a4e01d42fdb8'}], 'split_idx_start': 16006, 'file_name': 'pep-0736.txt', '_file_created_at': '2024-10-18T09:03:32.851485+00:00', 'split_id': 10, '_file_size': 25013, 'page_number': 1, 'file_id': 'a5a73fe5-14e4-43e0-8839-104d658a268d', 'source_id': '6acf4d46895d82a5b5f39ef3a4b8bb7b602ad6751d97fc5ea7ae5bb80a7ef869'}, score: 0.033599853515625), Document(id=dcbacf054847b57d03e5a03d8220d99451fa8ae0e7fbcc9c181d6c9a6daf6103, content: 'Type declarators after names that are only read, not assigned to, are not strictly
necessary but enf...', meta: {'_split_overlap': [{'range': [1335, 1565], 'doc_id': '8462f7bf34aa29a6abd2b0967902c5f8ff40845458c887616d9b271acf898cb3'}, {'range': [0, 375], 'doc_id': '8ca6c53419aaf4828c9c399dea7c87ef77b78ad770be79cdc7b1de7915f2ad7a'}], 'split_idx_start': 2713, 'file_name': 'pep-3117.txt', '_file_created_at': '2024-10-18T09:03:32.119394+00:00', 'split_id': 2, '_file_size': 8570, 'page_number': 1, 'file_id': '28215f42-588c-4a05-bb30-d38a979e54b9', 'source_id': '0098114fc233fd584f7b3dce6f20b38f8fee5671534fcadf52609771eb1872d9'}, score: 0.029205322265625), Document(id=266460ca840d425453afcbcb214b775de933f816972f4294c2992f911743ea3a, content: '* random_bytes - returns a random byte string.
* random_number - depending on the argument, retur...', meta: {'_split_overlap': [{'range': [1633, 1826], 'doc_id': 'cb505fb7b551acc17bc30be7e4698eca6ce01f2724326b7b8a38cfc1eaabba27'}, {'range': [0, 173], 'doc_id': '6754d08c1a7fb48d16d754bc556a76f6b049c977640b0bb130d723348134d74c'}], 'split_idx_start': 10795, 'file_name': 'pep-0506.txt', '_file_created_at': '2024-10-18T09:03:53.308697+00:00', 'split_id': 8, '_file_size': 18395, 'page_number': 1, 'file_id': '13775073-db35-4864-b7fc-a1d71202be3a', 'source_id': '375ba446b3fc8643ef846664ea0f644caba318a6d0fb7113475c3dbf7357e906'}, score: 0.028594970703125), Document(id=8462f7bf34aa29a6abd2b0967902c5f8ff40845458c887616d9b271acf898cb3, content: 'Therefore, this PEP combines the move to type declarations with another bold
move that will once aga...', meta: {'_split_overlap': [{'range': [1378, 1629], 'doc_id': '1f47efdb3224a877cf94bcbee759cf79b96f83768dc99bbc301b2a2f9cbd1417'}, {'range': [0, 230], 'doc_id': 'dcbacf054847b57d03e5a03d8220d99451fa8ae0e7fbcc9c181d6c9a6daf6103'}], 'split_idx_start': 1378, 'file_name': 'pep-3117.txt', '_file_created_at': '2024-10-18T09:03:32.119394+00:00', 'split_id': 1, '_file_size': 8570, 'page_number': 1, 'file_id': '28215f42-588c-4a05-bb30-d38a979e54b9', 'source_id': '0098114fc233fd584f7b3dce6f20b38f8fee5671534fcadf52609771eb1872d9'}, score: 0.0258636474609375), Document(id=0358e0dc28ffad1c66d8b51e8b52c87670bb10d3379df9ca215c94f00dcbf881, content: 'Typically only exceptions that
signal an error are desired to be caught. This means that exceptions...', meta: {'_split_overlap': [{'range': [1441, 1642], 'doc_id': '2b91fca3faf02123a3d14f6aa206cfec9848a40577a72561e43b9d45a42947da'}, {'range': [0, 384], 'doc_id': 'd8038333a8193db3f52139147c1dd0fc38b13099a86a14ff05c9ca28c7641cc8'}], 'split_idx_start': 9260, 'file_name': 'pep-0348.txt', '_file_created_at': '2024-10-18T09:04:05.356969+00:00', 'split_id': 7, '_file_size': 19534, 'page_number': 1, 'file_id': '96d69bd9-9727-4ad0-a06e-ddafb8d96c0d', 'source_id': 'e6bf6cb76eed041b0d80c64c9bf0898d7017757b0933dbed1e1a54a05f079a83'}, score: 0.010650634765625)]
Changing How the Documents Are Presented
You can also use a Jinja loop to add documents to your prompts. The following loop structures documents in a numbered way:
These are the documents:
{% for document in documents %}
Document[{{ loop.index }}]:
{{ document.content }}
{% endfor %}
Question: {{ question }}
Answer:
This loop results in documents being rendered like this:
Document[1]:
<content of first document>
Document[2]:
<content of second document>
Such a format makes it easier for the LLM to understand document boundaries by creating a clear, predictable structure. It's also useful if you want the LLM to generate references in its answers. It can then reference the document by its number.
Rendered prompt example
You are a technical expert.
You answer questions truthfully based on provided documents.
If the answer exists in several documents, summarize them.
Ignore documents that don't contain the answer to the question.
Only answer based on the documents provided. Don't make things up.
If no information related to the question can be found in the document, say so.
Always use references in the form [NUMBER OF DOCUMENT] when using information from a document, e.g. [3] for Document[3].
Never name the documents, only enter a number in square brackets as a reference.
The reference must only refer to the number that comes in square brackets after the document.
Otherwise, do not use brackets in your answer and reference ONLY the number of the document without mentioning the word document.
These are the documents:
Document[1]:
deepset_platform_metadata:
group: how-tos
navigation: guides
section: working-with-llms
source: docusaurus-build
title: writing-prompts-in-deepsetq
type: how-to
---
More Than One Way To Do It
deepset_platform_metadata:
group: how-tos
navigation: guides
section: working-with-llms
source: docusaurus-build
title: writing-prompts-in-deepsetq
type: how-to
---
Okay, the Zen doesn't say that there should be Only One Way To Do It.
But it does have a prohibition against allowing "more than one way to
do it".
''''''''Response
''''''''
There is no such prohibition. The "Zen of Python" merely expresses a
*preference* for "only one *obvious* way"::
There should be one-- and preferably only one --obvious way to do
it.
The emphasis here is that there should be an obvious way to do "it".
In the case of dict update operations, there are at least two
different operations that we might wish to do:
- *Update a dict in place*: The Obvious Way is to use the ``update()``
method. If this proposal is accepted, the ``|=`` augmented
assignment operator will also work, but that is a side-effect of how
augmented assignments are defined. Which you choose is a matter of
taste.
- *Merge two existing dicts into a third, new dict*: This PEP proposes
that the Obvious Way is to use the ``|`` merge operator.
In practice, this preference for "only one way" is frequently violated
in Python. For example, every ``for`` loop could be re-written as a
``while`` loop; every ``if`` block could be written as an ``if``/
``else`` block. List, set and dict comprehensions could all be
replaced by generator expressions.
Document[2]:
PEP: 20
Title: The Zen of Python
Author: Tim Peters <tim.peters@gmail.com>
Status: Active
Type: Informational
Content-Type: text/x-rst
Created: 19-Aug-2004
Post-History: 22-Aug-2004
Abstract
========
Long time Pythoneer Tim Peters succinctly channels the BDFL's guiding
principles for Python's design into 20 aphorisms, only 19 of which
have been written down.
The Zen of Python
=================
.. code-block:: text
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren't special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you're Dutch.
Now is better than never.
Although never is often better than *right* now.
If the implementation is hard to explain, it's a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea -- let's do more of those!
Easter Egg
==========
.. code-block:: pycon
>>> import this
References
==========
Originally posted to comp.lang.python/python-list@python.org under a
thread called `"The Way of Python"
<https://groups.google.com/d/msg/comp.lang.python/B_VxeTBClM0/L8W9KlsiriUJ>`__
Copyright
=========
This document has been placed in the public domain.
Document[3]:
If one expects to be merging a large number of dicts where performance
is an issue, it may be better to use an explicit loop and in-place
merging::
new = {}
for d in many_dicts:
new |= d
deepset_platform_metadata:
group: how-tos
navigation: guides
section: working-with-llms
source: docusaurus-build
title: writing-prompts-in-deepsetq
type: how-to
---
Dict Union Is Lossy
deepset_platform_metadata:
group: how-tos
navigation: guides
section: working-with-llms
source: docusaurus-build
title: writing-prompts-in-deepsetq
type: how-to
---
Dict union can lose data (values may disappear); no other form of
union is lossy.
''''''''Response
''''''''
It isn't clear why the first part of this argument is a problem.
``dict.update()`` may throw away values, but not keys; that is
expected behavior, and will remain expected behavior regardless of
whether it is spelled as ``update()`` or ``|``.
Other types of union are also lossy, in the sense of not being
reversible; you cannot get back the two operands given only the union.
``a | b == 365``... what are ``a`` and ``b``?
deepset_platform_metadata:
group: how-tos
navigation: guides
section: working-with-llms
source: docusaurus-build
title: writing-prompts-in-deepsetq
type: how-to
---
Only One Way To Do It
deepset_platform_metadata:
group: how-tos
navigation: guides
section: working-with-llms
source: docusaurus-build
title: writing-prompts-in-deepsetq
type: how-to
---
Dict union will violate the Only One Way koan from the Zen.
''''''''Response
''''''''
There is no such koan. "Only One Way" is a calumny about Python
originating long ago from the Perl community.
deepset_platform_metadata:
group: how-tos
navigation: guides
section: working-with-llms
source: docusaurus-build
title: writing-prompts-in-deepsetq
type: how-to
---
More Than One Way To Do It
deepset_platform_metadata:
group: how-tos
navigation: guides
section: working-with-llms
source: docusaurus-build
title: writing-prompts-in-deepsetq
type: how-to
---
Okay, the Zen doesn't say that there should be Only One Way To Do It.
But it does have a prohibition against allowing "more than one way to
do it".
''''''''Response
''''''''
There is no such prohibition.
Document[4]:
* A nearly-identical syntax is already established for f-strings.
* Programmers will, as ever, adjust over time.
The feature is confusing
deepset_platform_metadata:
group: how-tos
navigation: guides
section: working-with-llms
source: docusaurus-build
title: writing-prompts-in-deepsetq
type: how-to
---
We argue that:
* Introducing new features typically has this impact temporarily.
* The syntax is very similar to the established ``f'{x=}'`` syntax.
* The feature and syntax are familiar from other popular modern languages.
* The expansion of ``x=`` to ``x=x`` is in fact a trivial feature and inherently
significantly less complex than ``*arg`` and ``**kwarg`` expansion.
* This particular syntactic form has been independently proposed on numerous
occasions, indicating that it is the most obvious [1]_ [2]_ [6]_.
The feature is not explicit
deepset_platform_metadata:
group: how-tos
navigation: guides
section: working-with-llms
source: docusaurus-build
title: writing-prompts-in-deepsetq
type: how-to
---
We recognize that, in an obvious sense, the argument value is 'implicit' in this
proposed syntax. However, we do not think that this is what the Zen of Python is
aiming to discourage.
In the sense that we take the Zen to be referring to, keyword arguments (for
example) are more explicit than positional arguments where the argument name is
omitted and impossible to tell from the local context. Conversely, the syntactic
sugar for integers ``x += 1`` is not more implicit than ``x = x + 1`` in this
sense, even though the variable is omitted from the right hand side, because it
is immediately obvious from the local context what it is.
Document[5]:
Type declarators after names that are only read, not assigned to, are not strictly
necessary but enforced anyway (see the Python Zen: "Explicit is better than
implicit.").
The mapping between types and declarators is not static. It can be completely
customized by the programmer, but for convenience there are some predefined
mappings for some built-in types:
========================= ===================================================
Type Declarator
========================= ===================================================
``object`` � (REPLACEMENT CHARACTER)
``int`` ℕ (DOUBLE-STRUCK CAPITAL N)
``float`` ℮ (ESTIMATED SYMBOL)
``bool`` ✓ (CHECK MARK)
``complex`` ℂ (DOUBLE-STRUCK CAPITAL C)
``str`` ✎ (LOWER RIGHT PENCIL)
``unicode`` ✒ (BLACK NIB)
``tuple`` ⒯ (PARENTHESIZED LATIN SMALL LETTER T)
``list`` ♨ (HOT SPRINGS)
``dict`` ⧟ (DOUBLE-ENDED MULTIMAP)
``set`` ∅ (EMPTY SET) (*Note:* this is also for full sets)
``frozenset`` ☃ (SNOWMAN)
``datetime`` ⌚ (WATCH)
``function`` ƛ (LATIN SMALL LETTER LAMBDA WITH STROKE)
``generator`` ⚛ (ATOM SYMBOL)
``Exception`` ⌁ (ELECTRIC ARROW)
========================= ===================================================
The declarator for the ``None`` type is a zero-width space.
These characters should be obvious and easy to remember and type for every
programmer.
Unicode replacement units
=========================
Since even in our modern, globalized world there are still some old-fashioned
rebels who can't or don't want to use Unicode in their source code, and since
Python is a forgiving language, a fallback is provided for those:
Instead of the single Unicode character, they can type ``name${UNICODE NAME OF
THE DECLARATOR}$``.
Document[6]:
* random_bytes - returns a random byte string.
* random_number - depending on the argument, returns either a random
integer in the range(0, n), or a random float between 0.0 and 1.0.
* urlsafe_base64 - returns a random URL-safe Base64 encoded string.
* uuid - return a version 4 random Universally Unique IDentifier.
What Should Be The Name Of The Module?
======================================
There was a proposal to add a "random.safe" submodule, quoting the Zen
of Python "Namespaces are one honking great idea" koan. However, the
author of the Zen, Tim Peters, has come out against this idea [#]_, and
recommends a top-level module.
In discussion on the python-ideas mailing list so far, the name "secrets"
has received some approval, and no strong opposition.
There is already an existing third-party module with the same name [#]_,
but it appears to be unused and abandoned.
Frequently Asked Questions
==========================
* Q: Is this a real problem? Surely MT is random enough that nobody can
predict its output.
A: The consensus among security professionals is that MT is not safe
in security contexts. It is not difficult to reconstruct the internal
state of MT [#]_ [#]_ and so predict all past and future values. There
are a number of known, practical attacks on systems using MT for
randomness [#]_.
* Q: Attacks on PHP are one thing, but are there any known attacks on
Python software?
A: Yes. There have been vulnerabilities in Zope and Plone at the very
least.
Document[7]:
Therefore, this PEP combines the move to type declarations with another bold
move that will once again prove that Python is not only future-proof but
future-embracing: the introduction of Unicode characters as an integral
constituent of source code.
Unicode makes it possible to express much more with much less characters, which
is in accordance with the :pep:`Zen <20>` ("Readability counts."). Additionally, it
eliminates the need for a separate type declaration statement, and last but not
least, it makes Python measure up to Perl 6, which already uses Unicode for its
operators. [#]_
Specification
=============
When the type declaration mode is in operation, the grammar is changed so that
each ``NAME`` must consist of two parts: a name and a type declarator, which is
exactly one Unicode character.
The declarator uniquely specifies the type of the name, and if it occurs on the
left hand side of an expression, this type is enforced: an ``InquisitionError``
exception is raised if the returned type doesn't match the declared type. [#]_
Also, function call result types have to be specified. If the result of the call
does not have the declared type, an ``InquisitionError`` is raised. Caution: the
declarator for the result should not be confused with the declarator for the
function object (see the example below).
Type declarators after names that are only read, not assigned to, are not strictly
necessary but enforced anyway (see the Python Zen: "Explicit is better than
implicit.").
The mapping between types and declarators is not static.
Document[8]:
Typically only exceptions that
signal an error are desired to be caught. This means that exceptions
that are used to signify that the interpreter should exit should not
be caught in the common case.
With KeyboardInterrupt and SystemExit moved to inherit from
BaseException instead of Exception, changing bare ``except`` clauses
to act as ``except Exception`` becomes a much more reasonable
default. This change also will break very little code since these
semantics are what most people want for bare ``except`` clauses.
The complete removal of bare ``except`` clauses has been argued for.
The case has been made that they violate both Only One Way To Do It
(OOWTDI) and Explicit Is Better Than Implicit (EIBTI) as listed in the
:pep:`Zen of Python <20>`. But Practicality Beats Purity (PBP), also in
the Zen of Python, trumps both of these in this case. The BDFL has
stated that bare ``except`` clauses will work this way
[#python-dev8]_.
Implementation
deepset_platform_metadata:
group: how-tos
navigation: guides
section: working-with-llms
source: docusaurus-build
title: writing-prompts-in-deepsetq
type: how-to
---
The compiler will emit the bytecode for ``except Exception`` whenever
a bare ``except`` clause is reached.
Transition Plan
===============
Because of the complexity and clutter that would be required to add
all features planned in this PEP, the transition plan is very simple.
In Python |2.x| BaseException is added. In Python 3.0, all remaining
features (required superclass, change in inheritance, bare ``except``
clauses becoming the same as ``except Exception``) will go into
affect.
Question: what are the python zens?
Answer:
Adding Documents with Their Metadata
You can also enhance the documents passed to the LLM with their metadata by using this syntax: document.meta.<field_name>. This example adds the date of publication and genre of each document in the prompt:
Here are the articles:
{% for document in documents %}
Document[{{ loop.index }}]:
Date of Publication: {{ document.meta.date }}
Genre: {{ document.meta.genre }}
{{ document.content }}
{% endfor %}
Question: {{ question }}
Answer:
In the rendered prompt, the documents would be displayed as follows:
Here are the articles:
Document[1]:
Date of Publication: 12.03.2024}
Genre: News
This is a news article.
Document[2]:
Date of Publication: 23.09.2024}
Genre: Interview
This is an interview.
Question: What happened in Austria yesterday?
Answer:
Examples in Prompts
You can add examples to your prompt. This technique, called few-shot prompting, teaches the LLM how to perform the task by example. This prompt contains examples of questions and answers:
You are a helpful assistant that answers questions.
Answer the questions as shown in the examples.
Here are some question-answer examples:
{% set ns = namespace(example="") -%}
{% for e in examples -%}
{% set ns.example = ns.example + "\nQuery: " + e.query + "\nResponse: "+ e.response + "\n" -%}
{% endfor -%}
{{ ns.example }}
Now please answer the user query.
Query: {{query}}
Answer:
In this case, PromptBuilder would need examples and query as input to render the prompt.
The rendered prompt would contain some query-response pairs:
You are a helpful assistant that answers questions
Answer the questions as shown in the examples.
Here are some question-answer examples:
Query: What is the capital of France?
Response: The capital of France is Paris.
Query: How tall is Mount Everest?
Response: Mount Everest is approximately 29,029 feet (8,848 meters) tall.
Now please answer the user query.
Query: What is the speed of light?
Answer:
Variables in Prompts
Setting Required Variables
This ChatPromptBuilder's prompt contains the target_language and text variables. Then, using the required_variables setting, it declares them as required. This means that if either of them is not provided at runtime, the component raises an error.
ChatPromptBuilder template:
- content:
text: "Translate to {{ target_language }}: {{ text }}"
role: user
ChatPromptBuilder required_variables parameter setting to indicate both variables are required:
- target_language
- text
Declaring All Variables
The following prompts declare all variables as valid inputs and set location and day_count as required.
This is the system prompt:
You are a helpful assistant speaking {{ language }}
This is the user prompt:
"What’s the weather in {{ location }} for the next {{ day_count }} days?"
Then, in Required Variables, you indicate which of the variables must be provided:
- location
- day_count
Was this page helpful?