HallucinationDetector
HallucinationDetector solves the problem of models making up answers by highlighting the answers that don't exist in the context.
Changes on their way
We're still actively working on this feature to make it better. This page describes its current, first implementation. We'll be updating it soon to make it smoother.
HallucinationDetector is designed for retrieval-augmented generative question answering systems, where the model generates answers based on your documents. To avoid hallucinations, HallucinationDetector uses a model to indicate the answers that are grounded in the documents and the ones that are not.
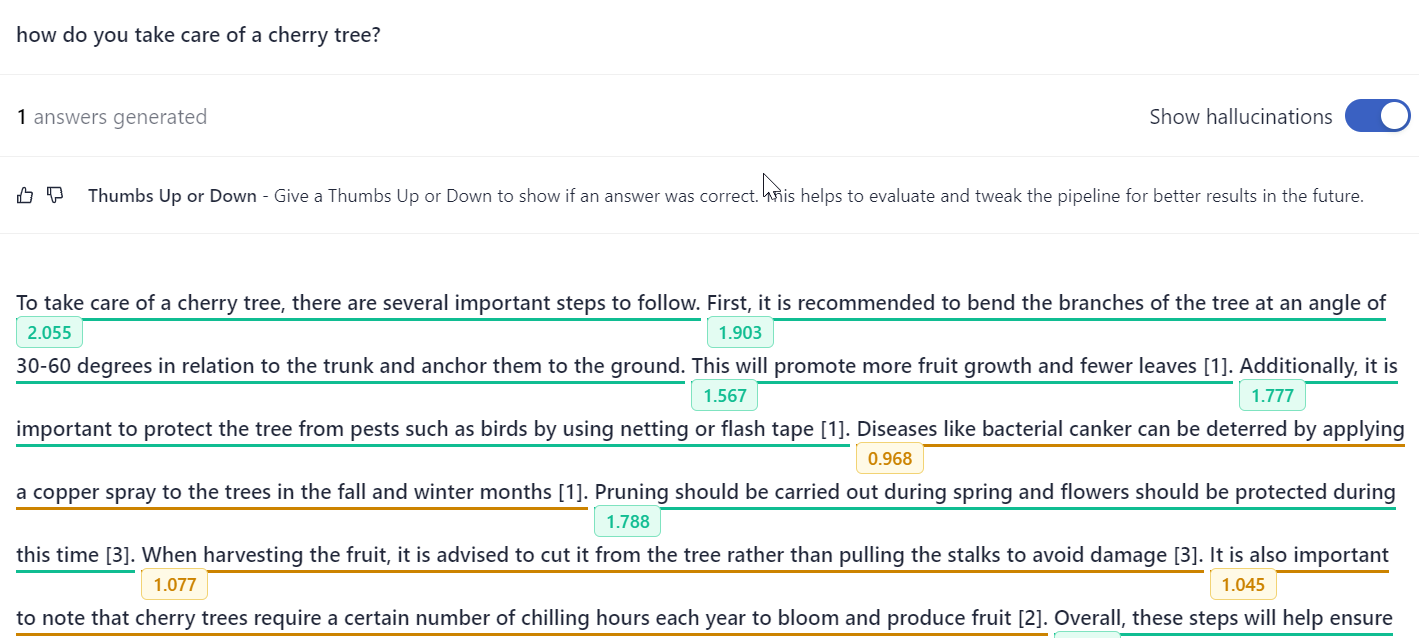
If you add HallucinationDetector to your generative pipeline, you can then enable it on the Search page. When enabled. HallucinationDetector highlights each sentence in the answer, indicating if it's grounded in the documents. Green highlight means the sentence is based on the documents. Orange highlight means it's partially based on the documents. Red highlight means it's a hallucination.
An example of an answer with hallucinations underlined
Basic Information
- Pipeline type: Used in query pipelines.
- Position in a pipeline: After PromptNode.
- Input: Documents
- Output: Answers
- Available Classes: TransformersHallucinationDetector
Usage Example
It's best to leave the node with its default parameters:
...
components:
- name: HallucinationDetector
type: TransformersHallucinationDetector
...
pipelines:
- name: query
nodes:
- name: Retriever
inputs: [Query]
- name: PromptNode
inputs: [Retriever]
- name: HallucinationDetector
inputs: [PromptNode]
...
Arguments
| Argument | Type | Possible Values | Description |
|---|---|---|---|
model_name_or_path | String | It uses a model we trained for detecting hallucinations. | The model used for detecting whether an answer is grounded in the documents. Mandatory. |
model_version | String | The version of the model. Optional. | |
language | String | cs - Czechda - Danishde - Germanel - Greeken - Englishes - Spanishet - Estonianfi - Finnishfr - Frenchit - Italianml - Malayamnl - Dutchno - Norwegianpl - Polishpt - Portugeseru - Russiansl - Slovenesv - Swedishtr - TurkishDefault: en | The language of the documents using the nltk format. Mandatory. |
use_gpu | Boolean | True/False Default: True | Uses GPU if available. If not, it falls back on the CPU. Mandatory. |
batch_size | Integer | Default: 16 | The batch size for inference. Mandatory. |
use_auth_token | String, Boolean | An API token if you're using a private model. Optional. | |
devices | String, torch.device | A list of devices to use for inference. Optional. | |
class_thresholds | String, float | Default: "full_support": 1.5"partial_support": -0.5"no_support": -0.2 | The thresholds for the classes. The classes are: - full_support (the whole sentence is grounded in the documents)- partial_support (a part of the sentence is grounded in the documents)- no_support (the sentence is not in the documents)- contradiction (the sentence contradicts the documents).We trained the model to return: 2 for full_support1 for partial_support0 for no_support-1 for contradiction.Thresholds are inclusive, which means that if full_support is 1.3, the value of 1.3 is considered full_support.Changing the thresholds between the classes can help you calibrate what the model considers as grounded in the documents or not. Optional. |
default_class | String | contradictionfull_supportno_supportpartial_supportDefault: contradiction | The default class if the value is below all thresholds. Mandatory. |
Updated 6 months ago