Release 2023.11
Have a look at the features we added in November 2023.
Support for Models Hosted on Amazon Bedrock
You can now use text generation models available on Amazon Bedrock. For model IDs and a full list, see Amazon Bedrock documentation.
To use a model hosted on Bedrock, pass its ID preceded by deepset-cloud- in the model_name_or_path parameter of PromptNode:
components:
- name: PromptNode
type: PromptNode
params:
model_name_or_path: deepset-cloud-anthropic.claude-v2 #This PromptNode uses the Claude 2 model hosted on Bedrock
model_kwargs:
temperature: 0.6
Creating Labeled Datasets for Document Search
We've added Labeling Projects you can use to collaboratively label documents. First, you create a project and configure its settings, such as the pipeline you want to use to pre-filter the documents, the number of labels you want to reach, or any guidelines you want to give to the labelers. Then, you invite people to help you label.
Once you've reached the number of labels you were targeting, you can easily export them into a .CSV and use as an evaluation dataset in experiments.
To make things easier, we created a pipeline template specially designed to be used in document search labeling projects. You can use it in your projects as it is. But you can also update it or use any other document search pipeline you like.
For instructions on how to use labeling projects, see Create a Labeling Project and Label Answers.
For more background information on what the projects are and how they work, see Labeling Projects.
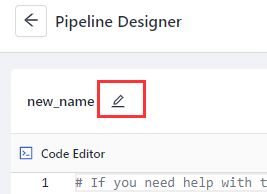
Easy Pipeline Renaming
We've moved the pipeline name out of the code editor so that you can easily change it without undeploying the pipeline. Just open the pipeline whose name you want to change, click the icon next to the name, and type a new name. That's it!
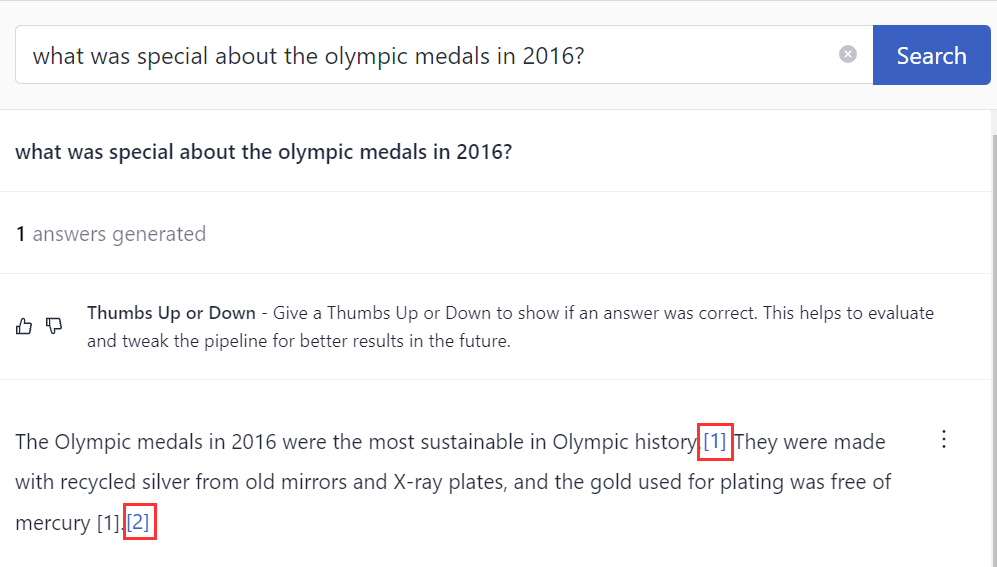
Showing References to Answers Generated by LLMs
If you're worried about hallucinations, try out the ReferencePredictor node in your RAG pipelines. It attaches references to answers the large language model generated. You can configure how often the references appear using the answer_window_size parameter.
You can click a reference to open it up and check its contents. Say hello to well-grounded answers!
Updated 8 months ago