Tutorial: Building Your First Document Search App
This tutorial teaches you how to build a document search system in the easiest and fastest possible way. It uses the UI for uploading the sample files and a template for creating the document retrieval pipeline.
- Level: Beginner
- Time to complete: 10 minutes
- Prerequisites:
- This tutorial assumes a basic knowledge of language models.
- You must be an Admin to complete this tutorial.
- Make sure you have a deepset Cloud workspace where the information retrieval pipeline will run.
- Goal: After completing this tutorial, you will have built a complete English document retrieval system from scratch that can fetch NHS documents.
Upload Files
First, let's get the files the search will run on into deepset Cloud.
-
Download the .zip file from gdrive and unzip it to a location on your computer.
-
Log in to deepset Cloud, switch to the right workspace, and go to Files.
-
Click Upload Files, drag the files you unpacked in step 1, and drop them to the Upload Files window. (You must select all files in a folder; deepset Cloud doesn't support uploading folders.)
-
Click Upload and wait until the upload finishes. Even when the upload is finished, the files may take a while to show up in deepset Cloud. That's expected; just wait a while and refresh the page if needed.
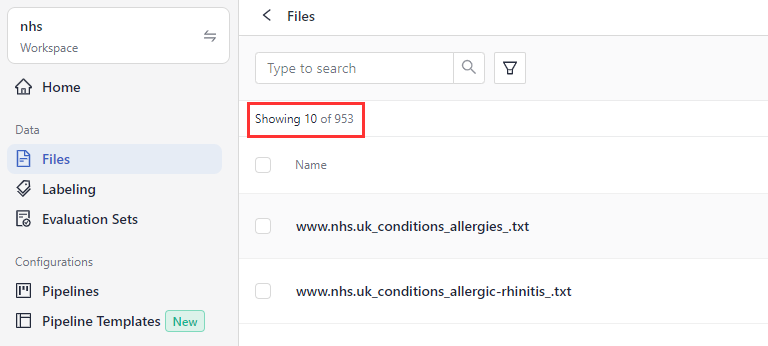
Result: Your files have been uploaded and are shown on the Files page. You should have 953 files.
Create a Pipeline
The next step is to define the components of your search app. We'll use a document search pipeline template with a vector retriever to create the pipeline.
-
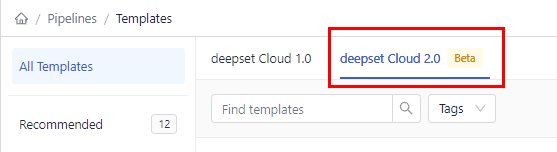
Go to Pipeline Templates and make sure you're on the deepset Cloud 2.0 tab.
-
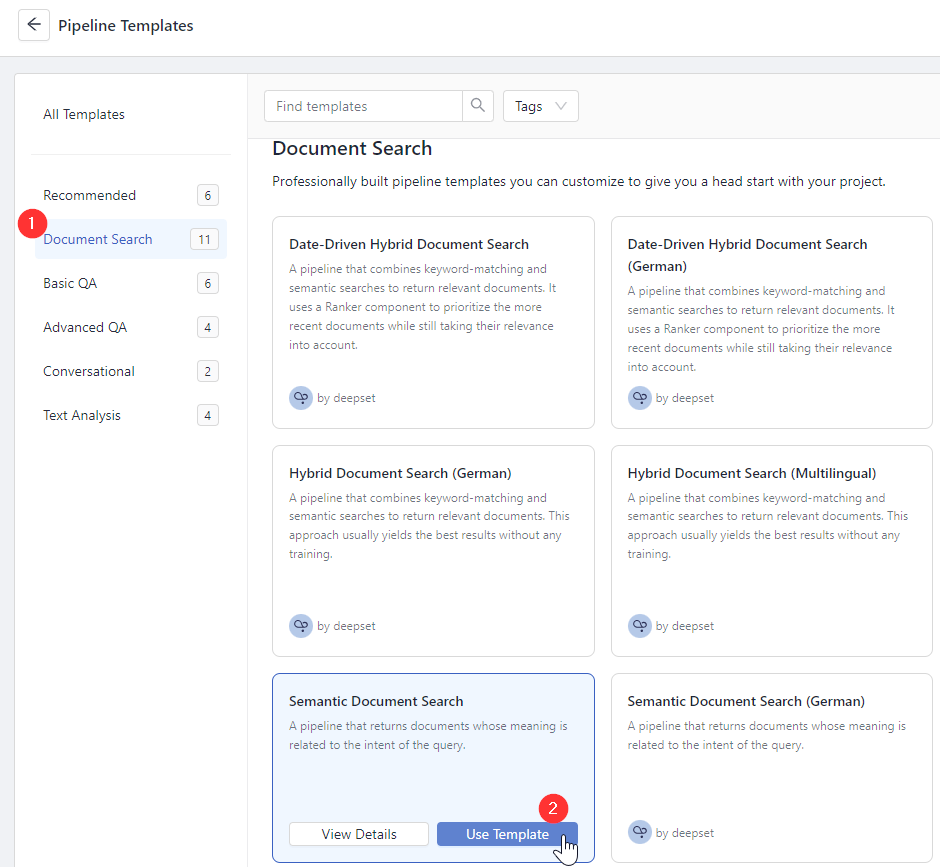
Choose Document Search as the category, find Semantic Document Search, and click Use Template.
-
Type NHS_doc_search as the pipeline name and click Create Pipeline. You're redirected to the Pipelines page. You can find your pipeline in the All tab.
Info: Newly created undeployed pipelines are automatically classified as drafts, so you can also find your pipeline in the _Drafts tab. But once you deploy it, it changes to a Development pipeline and is moved from the _Drafts to the Development tab. -
Click Deploy next to your pipeline. This triggers indexing and prepares your pipeline for search.
-
Wait until the status of your pipeline changes to Indexed. This can take a couple of minutes.
Tip: When you hover your mouse over the status, you can see the number of files already indexed.
Result: You created and deployed a pipeline, which means your documents have been indexed, and you can now run a search. Your pipeline status is Indexed.
Your pipeline is at the development service level. We recommend you test it before setting it to the production service level.

Try Your Pipeline
Let's see what the pipeline can do.
- Go to Playground.
- Choose NHS_doc_search as the pipeline.
- Type "How do I treat atopic skin?" and search for relevant documents. You should get a number of documents sorted by the most relevant ones.
Result: Congratulations! You have built a search system that can retrieve documents related to health. You can now ask health-related queries, and it will find relevant documents.
What's Next
Your pipeline is now a development pipeline. Once it's ready for production, change its service level to Production. You can do this on the Pipeline Details page shown after clicking a pipeline name. To learn more, see Pipeline Service Levels.
Updated 4 months ago