Connect Your OpenSearch Cluster
You can store the files in your AWS OpenSearch cluster and connect Haystack Enterprise Platform to it. This way, you control where your files are stored but you can still use them in your search app.
About This Task
Currently, we support connecting Amazon Web Services OpenSearch clusters in the eu-central-1 region to Haystack Enterprise Platform.
When you connect Haystack Enterprise Platform to your OpenSearch cluster, here's how it works: First, you upload your data to Haystack Platform. Then, Haystack Platform takes care of seamlessly transferring your data to the OpenSearch cluster. Although you can still view the files in Haystack Enterprise Platform, they're located in your OpenSearch cluster.
You can use one or two AWS clusters for this. We recommend you use two OpenSearch clusters: one for the workspace files and one for serving the pipelines. This way, you can save money, as the workspace cluster doesn't need that many resources.
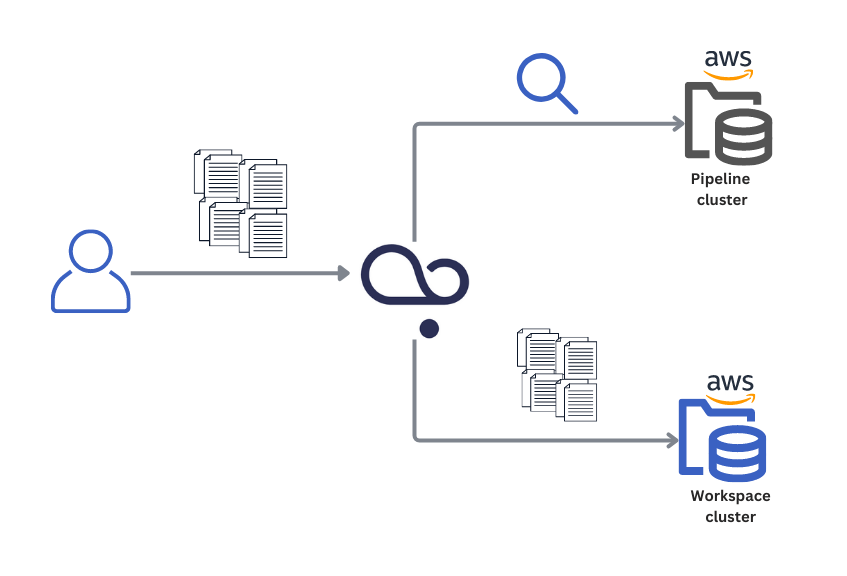
The workspace cluster is where the files are stored as raw text. It's not used for search, and it doesn't store the vector representations of the files. For this cluster, you need a basic setup and less memory than for the pipeline cluster.
The pipeline cluster is the cluster where vector representations of files are stored and where the search happens. This cluster needs more memory than the workspace cluster. When you allocate memory to it, also consider whether you're planning to run a vector-based or keyword-based search on the files stored in this cluster. Vector-based search needs more memory than keyword-based one.
You can connect Haystack Enterprise Platform to your Amazon OpenSearch Services cluster through API. There are four steps to do that:
- Authorize the Haystack Platform AWS account to connect to your OpenSearch cluster.
- Send an API call to create the OpenSearch credentials for the Haystack Platform workspace.
- Send an API call to create the OpenSearch credentials for your pipelines.
- Send an API call to create a Haystack Platform workspace that you want to connect with your OpenSearch cluster. The pipelines in this workspace will run on your OpenSearch cluster.
You can't connect an OpenSearch cluster to an existing workspace. This is because we want your files to be secure. When you create a dedicated workspace connected to your private cloud, you can be certain all your files are stored in your private cloud, not in Haystack Enterprise Platform. This wouldn't be the case if you connected your private cloud to an existing workspace.
Prerequisites
- You must have your Amazon OpenSearch Services clusters ready. We recommend using one cluster for the workspace and another one for your pipelines.
- The cluster for your workspace is only used to index the files. It doesn't store any embeddings, so you don't need to allocate too much memory to it.
- The cluster for your pipelines handles the vector representations of the files, so make sure you allocate sufficient memory to it.
- Both clusters must be in the
eu-central-1region in AWS. If you need support for another region, contact your Haystack Platform representative.
- Have the
arnfor your workspace and pipeline clusters ready. You'll add it to the request to create the credentials.
Obtaining the ARN for your clusters
-
Log in to your AWS account and open Amazon OpenSearch Service.
-
Select the cluster whose ARN you want to check.
The cluster details page opens, and in the General information section, you can see the domain ARN for the cluster.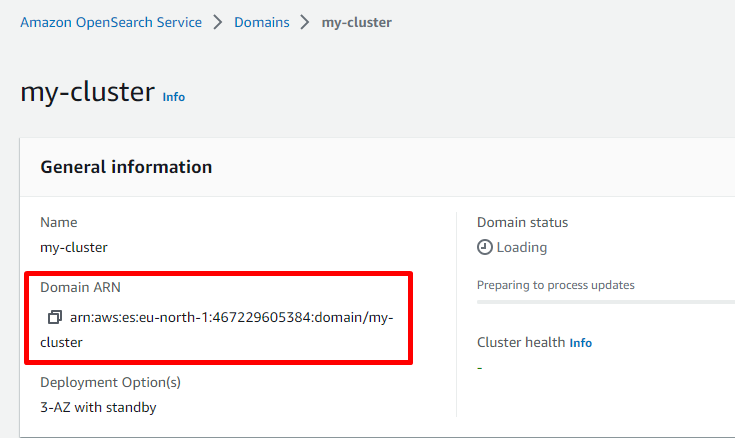
Connect Your Cluster to Haystack Enterprise Platform
-
Authorize Haystack Enterprise Platform to use your OpenSearch clusters:
-
Log in to your AWS account and open Amazon OpenSearch Service.
-
On the dashboard, select the cluster you want to use for the workspace. (This is the cluster that is used to store the list of files only.)
-
On the cluster details page, go to VPC endpoints.
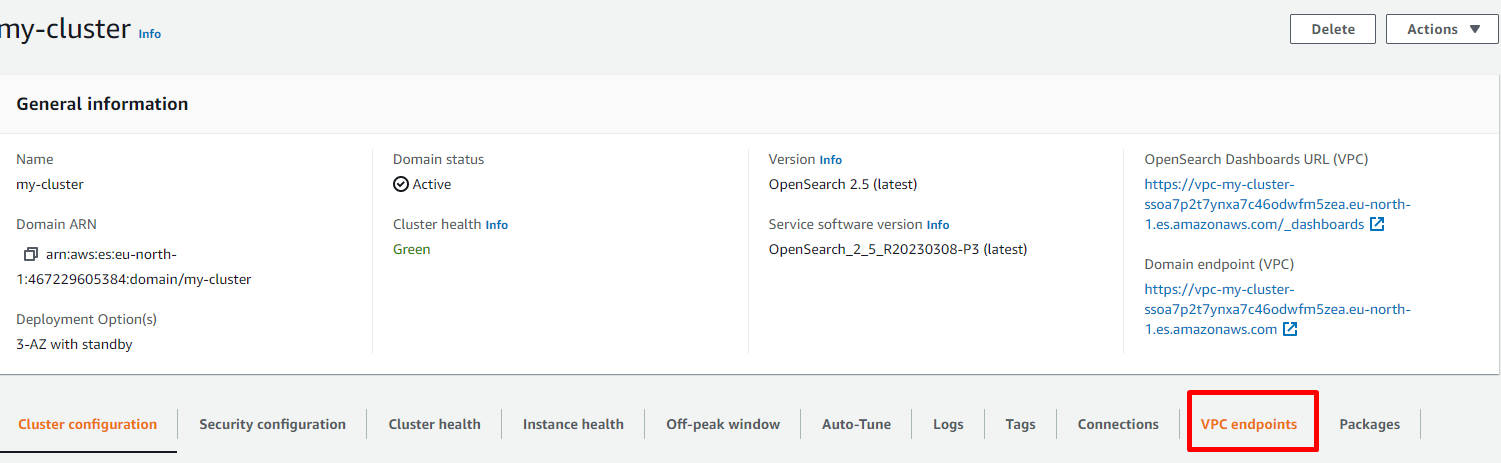
-
In the Authorized principals section, click Authorize principal and type in the Haystack Platform AWS account number:
364870968120. -
Click Authorize.
-
Repeat steps 1i to 1v for the cluster you want to use for your pipelines. (This cluster will store the embeddings, so it needs more memory allocated.)
-
-
Create the credentials for your workspace cluster using the Add OpenSearch credentials endpoint. The port number is always
443.
Here's a sample request you can use as a starting point:curl --request POST \
--url https://api.cloud.deepset.ai/api/v1/infrastructure/document_stores \
--header 'accept: application/json' \
--header 'content-type: application/json' \
--data '
{
"port": 443,
"password": "<OpenSearch user password>",
"aws_domain_arn": "<cluster_arn>",
"username": "<OpenSearch username>",
}
' -
Wait until you get the response. This may take a couple of minutes, as AWS takes some time to create the connection. The response contains the cluster's credentials ID. You'll need them to create the workspace in the last step.
-
Repeat step 2 for the pipeline cluster. Again, wait for the response and make sure you save the credentials ID from it.
Listing CredentialsYou can also use the List Available Opensearch Credentials endpoint to get a list of all the credentials created for your Haystack Platform organization.
-
Create the workspace that you want to connect to your clusters. Use the Create Workspace endpoint. Make sure you provide the workspace cluster and the pipeline cluster credentials IDs you obtained from responses in steps 2 and 3.
Here's the code you can use as a starting point for this request:curl --request POST \
--url https://api.cloud.deepset.ai/api/v1/workspaces \
--header 'accept: application/json' \
--header 'content-type: application/json' \
--data '
{
"document_store_credentials": {
"pipeline_document_store_credentials_id": "<pipeline_cluster_credentials_id>",
"workspace_document_store_credentials_id": "<workspace_cluster_credentials_id>"
},
"name": "<workspace_name>"
}
'
What To Do Next
Now, the pipelines you create and deploy in the newly created workspace will use the files stored in your OpenSearch cluster.
Updating Credentials
If your credentials to any of the clusters connected to Haystack Enterprise Platform change, you must:
- Delete the workspace that uses the credentials. (You can also do this form Haystack Platform inferface. For details, see Navigation.)
- Delete the credentials using the Delete OpenSearch credentials endpoint.
- Add the new credentials.
- Create a new workspace. You can then copy your pipelines over to this workspace.
Deleting Credentials
To delete the credentials used by a cluster, you must first delete the workspace that uses them and then delete the credentials. If you delete the credentials without deleting the workspace, the workspace becomes unusable anyway.
Backup
Haystack Enterprise Platform doesn't create any backups for the data of your pipelines to prevent the data from spreading into Haystack Platform's storage. We highly recommend you configure automated snapshots for your OpenSearch indexes, as well as create runbooks and regularly practice index recovery.
Was this page helpful?