Connect Your S3 Bucket
Haystack Enterprise Platform comes with seamless integration with Amazon S3, a simple storage service by Amazon Web Services. Store your data in an AWS S3 bucket and connect it to Haystack Enterprise Platformd to use the files in S3 in your Haystack Platform pipelines.
About This Task
You use the API to connect Haystack Enterprise Platform to your Amazon Web Services S3 bucket. There are four steps you must complete:
- Give Haystack Enterprise Platform an AWS role that can access your S3 bucket.
- Send an API call to create the S3 credentials for a Haystack Platform workspace.
- Send an API call to create a Haystack Platform workspace you want to connect to your S3 bucket.
- Upload files to this Haystack Platform workspace using one of the available methods described in Upload Files
You can't connect an S3 bucket to an existing workspace. This is because we want your files to be secure. When you create a dedicated workspace connected to your private cloud, you can be certain all your files are stored in your private cloud, not in Haystack Enterprise Platform. This wouldn't be the case if you connected your private cloud to an existing workspace.
Haystack Enterprise Platform transfers the files you upload to the Haystack Platform workspace to the connected S3 bucket. While you can still view these files in Haystack Platform, they are actually stored in S3. Any pipelines created in the Haystack Platform workspace will use the files stored in the connected S3 bucket.
Haystack Enterprise Platform does not sync files bidirectionally with S3. If you upload files directly to S3 and then connect the bucket to Haystack Platform, these files will not be visible or usable in Haystack Enterprise Platform. To use files in pipelines, first connect the bucket to a Haystack Platform workspace, then upload the files through the Haystack Platform workspace.
Prerequisites
- You can either use an existing AWS S3 bucket, or let CloudFormation create a new one.
- Have the name for your bucket at hand. You'll need it for CloudFormation to create a role for Haystack Enterprise Platform, and in the request to create S3 credentials in Haystack Enterprise Platform.
- Have your Haystack Platform organization ID at hand. Use the Read Users Me API endpoint to obtain it. You'll need it when creating a stack in CloudFormation to grant Haystack Enterprise Platform access to your bucket.
Connect Your S3 Bucket to deepset
-
Add a role for Haystack Enterprise Platform to authorize it to work with your files:
-
In AWS, open CloudFormation and click Create stack.
-
Select Template is ready.
-
As template source, choose Amazon S3 URL, paste this URL:
https://deepsetcloud-cloudformation-templates.s3.eu-central-1.amazonaws.com/BringYourOwnCloud/AWS/FileStore/S3Bucket/deepsetCloud-BringYourOwnCloud-AWS-FileStore-S3Bucket_cloudformation.yamland click Next. -
Give your stack a name.
-
In the Parameters section:
- Choose whether you want to use an existing bucket or not.
- Set the bucket name.
- Set your Haystack Platform organization ID as the ExternalId.
- Set the name for the IAM Role to create.
-
For all other options, leave the default settings. Continue to the last step.
-
On the last step, acknowledge the AWS statement in the Capabilities section and click Submit. Wait until the status of your stack changes to CREATE_COMPLETE.
-
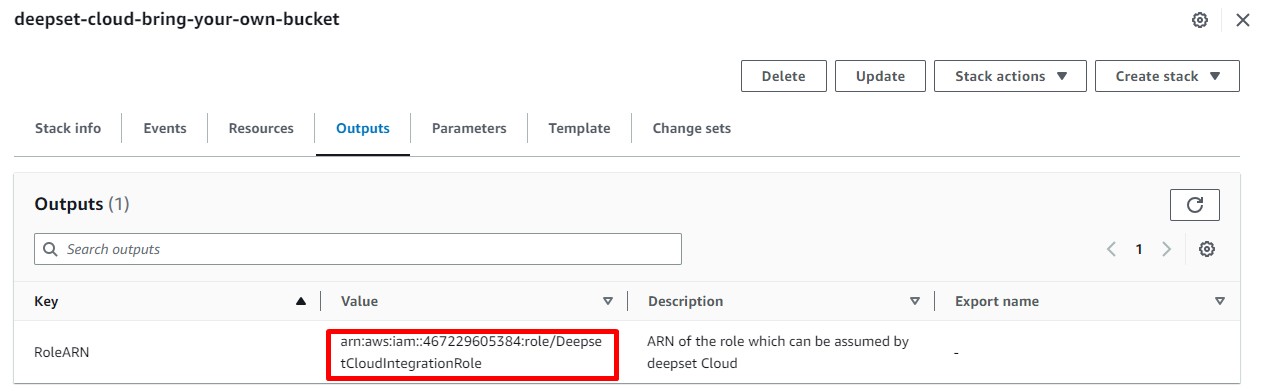
Open the stack and go to the Outputs tab.
-
Copy the value of the RoleARN key as you'll need it when sending a request to create the credentials.
-
-
Add the S3 credentials using the Add S3 Credentials endpoint. Here's a sample request you can use as a starting point:
curl --request POST \
--url https://api.cloud.deepset.ai/api/v1/infrastructure/file_stores \
--header 'accept: application/json' \
--header 'content-type: application/json' \
--data '
{
"assume_role": {
"role_arn": "<roleARN>",
"role_session_name": "<session_name>"
},
"bucket_name": "<name_of_your_bucket>"
}
'role_session_nameis any name you want to give to this session. -
Wait for the response. The response contains the ID of the credentials for S3. You'll need it to create the workspace connected to S3.
-
Create the workspace that will use the files stored in S3. Use the Create Workspace endpoint and specify the
file_store_credentials. You can ignore thedocument_store_credentials(it's used for OpenSearch).
Here's the code you can use to start with:curl --request POST \
--url https://api.cloud.deepset.ai/api/v1/workspaces \
--header 'accept: application/json' \
--header 'content-type: application/json' \
--data '
{
"file_store_credentials": {
"file_store_credentials_id": "<credentials_id_from_the_response>"
},
"name": "<workspace_name>"
}
'
What To Do Next
You connected your newly created workspace to your S3 bucket. All the files you upload to this workspace will be stored in your S3 bucket, and all the pipelines you create in this workspace will use the files from S3.
You can now upload files to your Haystack Platform workspace. For instructions, see Upload Files
Updating Credentials
If your credentials to any of the S3 buckets connected to Haystack Enterprise Platform change, do the following:
- Delete the workspace that uses the credentials. (You can also do this from Haystack Platform interface.)
- Delete the credentials using the Delete S3 Credentials endpoint.
- Add new credentials .
- Create a new workspace. You can then copy your pipelines over to this workspace.
Deleting Credentials
To delete the credentials used by a cluster, you must first delete the workspace that uses them and then delete the credentials. If you delete the credentials without deleting the workspace, the workspace becomes unusable anyway.
Backup
Haystack Enterprise Platform doesn't create any backups for the data of your pipelines to prevent the data from spreading into Haystack Platform's storage. We highly recommend you configure regular or continuous backups for your S3 buckets, and create runbooks, and regularly practice index recovery.
Was this page helpful?