Language Models
With such a variety of readily available fine-tuned models, it's difficult to choose the best one for your use case. This guide tells you about different types of models and when to use them.
What Are Language Models?
Language models are neural networks trained on large amounts of text to learn how a language works. If you think about the way you're using your native tongue, you'll observe that it's intuitive. You don't have to think about grammar rules when speaking; you just know and apply them intuitively. A language model attempts to enable machines to use language in a similar way humans do.
Language models are no magic. The way a model works is that it decides how probable it is that a word is valid in a particular word sequence. By valid, we mean that it resembles the way humans talk, not that it complies with any grammar rules.
The latest advance in NLP is the transformer architecture which led to top-performing models, such as BERT. It differs from previously used architectures in that instead of processing passages of text word-by-word, transformer-based models can process whole sentences at once, which makes them much faster in training but also in inference. They can also learn the relations between different words in a sentence and how these relations affect the expected model output—a functionality called attention mechanism.
Fine-Tuned Models
A fine-tuned model is a language model trained on a large amount of raw text to perform a specific NLP task, such as text classification or question answering. A lot of fine-tuned models are publicly available for free on model hubs such as Hugging Face. You can just grab them from there and use them in your NLP app as a starting point. You no longer need to train your own model, which takes a lot of time and a lot of data and uses a lot of computer resources.
Large Language Models (LLMs)
Large language models (LLMs) are huge models trained on enormous amounts of data. Interacting with such a model resembles talking to another person. These models have general knowledge of the world. You can ask them almost anything, and they'll be able to answer.
LLMs are trained to perform many NLP tasks with little training data. Some examples of tasks they can handle are language translation, summarization, question answering, or text generation.
These models are called "large" because they are trained on a large dataset, typically consisting of millions of words. Also, their architecture is much more complicated than the architecture of regular models. It consists of hundreds of layers and millions of parameters. This makes these models take up a lot of computational resources to run.
During the training, these models are not explicitly given task-specific labels or examples to learn from. Instead, they learn by predicting the next word in a sequence of words based on the context. During training, they memorize a lot of the training data. That's where their knowledge comes from.
LLMs have their limitations as well. Their knowledge isn't updated, so they won't be able to answer questions about very recent events or questions where the answer changes over time. They'll answer with something that was correct in the past. An example question like that is "Who's the president of the USA?".
Some of the most well-known LLMs include GPT-4, Anthropic's Claude or Sonnet, Mistral, or LLaMA 2. For an overview of the models, see Large Language Models Overview.
Model Parameters
When interacting with large language models, take into account these three parameters as they can significantly impact your prompt performance:
temperature
The lower the temperature, the more realistic the results. For fact-based question answering, we recommend setting the temperature to lower values, like 0.
A higher temperature can lead to more random, creative, and diverse answers. You may consider setting the temperature to a higher value if you want the model to perform creative tasks, like poem generation.top_p
This parameter controls nucleus sampling, which is a technique to generate text that balances both coherence and diversity. It limits the set of possible next words (the nucleus) based on the threshold of probability value p. You typically set it to a value between 0 and 1.
If you want the model to generate factual answers, set top_p to a low value, like 0.stop_words
When the model generates the set of characters specified as the stop words, it stops generating more text. It helps to control the length and relevance of the generated text.
See also Prompt Engineering Guidelines.
Model Naming Conventions
If you're new to models, it's helpful to understand the model naming convention as the name already gives you a hint about what the model can do. The first part of the name is the user that trained and uploaded the model. Then, there is the architecture that the model uses and the size of the model. The last part of the name is the dataset used to train the model.
Here's a typical model name:
deepset/roberta-base-squad2
deepset is the user who trained and uploaded the model, roberta is the model architecture, base is the size, and squad2 is the dataset on which the model was trained.
Model Types
You don't need to have in-depth knowledge of its architecture to use a model, but it's helpful to have a rough overview of the most common model types out there and their key differences. This will help you to better understand which models to try out in your own pipeline. Here's a timeline showing when the most common model architectures were developed.
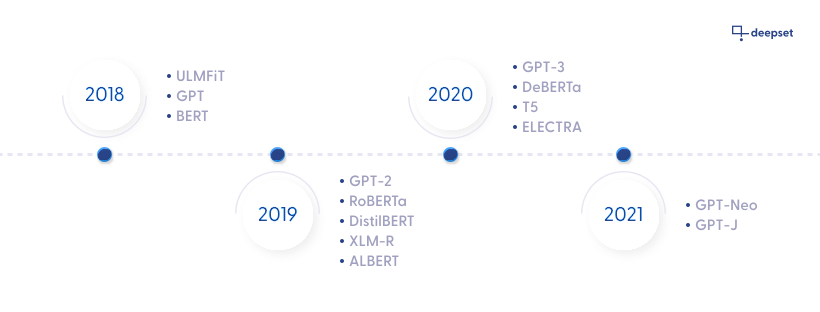
To get an idea of how different model types perform, have a look at Reader Performance Benchmarks. For recommended models, see Models in deepset AI Platform.
Model Size
Large models have better accuracy, but this comes at the cost of speed and the resources needed to run them. Large models can be significantly slower than smaller ones, using up a lot of your graphic card memory or even exceeding its limit. Distilled models are a good compromise, as they preserve accuracy similar to the larger models but are much smaller and easier to deploy.
Training Dataset
Standard datasets are used when training a model for a particular task. For example, SQuAD stands for Stanford Question Answering Dataset and is the standard dataset for training English-language models for question answering.
TipWhen searching for a model for your task, you can check what dataset is typically used for it and then search for a model that was trained on this dataset.
Updated about 2 months ago