Evaluation Datasets
An evaluation dataset is a file with gold answers for your search system. Learn about the format of the dataset and how to prepare it.
What's an Evaluation Dataset?
An evaluation dataset is an annotated set of data held back from your model. The annotations, or labels, can be question-answer pairs (for a question answering system), question-passage pairs (for an information retrieval system), or just questions (for RAG systems). They indicate the gold answers, which are the answers you would expect your search system to return.
Evaluation datasets are based on the files you uploaded to deepset Cloud. For question answering and document search, deepset Cloud automatically matches the labels in your dataset with the files in your workspace using file names. This happens automatically after you upload the dataset. If there are labels for which there is no match, deepset Cloud lets you know. The evaluation dataset only works for the files that existed in deepset Cloud at the time when you uploaded the evaluation set.
Why Do You Need an Evaluation Dataset?
During the evaluation, deepset Cloud uses the questions from your evaluation dataset and runs them through the evaluated pipeline, letting the system find the answers in all your files. The more files you provide, the more complex the task for the system is.
deepset Cloud then compares the answers returned by your search system to the gold answers from your evaluation dataset and, based on the results, calculates the metrics you can use to tweak your pipeline and boost its performance.
For RAG pipelines, you can use an evaluation dataset that contains just questions. deepset Cloud then runs it through your RAG pipeline and based on its answers it calculates the groundedness score of the answers and the no answer ratio.
Evaluation Datasets in deepset Cloud
In deepset Cloud, you can upload a pre-labeled evaluation dataset or label a dataset with other collaborators on the platform.
Dataset Format
The format differs for question answering, document retrieval, and RAG. In all cases, it must be a comma-delimited CSV file with UTF-8 encoding, but its contents differ.
RAG Dataset
To evaluate groundedness score and no answer ratio, all you need is an evaluation dataset with queries. You can use the search history of your pipeline to obtain the queries.
The evaluation dataset must be a CSV file with the following columns:
question: the question text. This is the only column that you must fill in.
Additionally, the file can have the following columns:
textcontextfile_nameanswer_startanswer_endfilters
Here's an example evaluation dataset: RAG dataset.
Question Answering Dataset
The evaluation dataset must be a CSV file with the following columns:
question: the question text.text: the answer to the question.context: the text surrounding the answer.file_name: the name of the file that contains the answer. It's optional.answer_start: the position of the character that starts the answer text in the context.answer_end: the position of the character that ends the answer text in the context.filters: any filters that should be used for search. This field is optional. You can use it to add filters you'd use in a real-life search. The filters should be in the following format:{"key1":"value1", "key1":"value2", "key2":"value3"}. If you don't want to use any filters, delete this column.
If the file contains any other columns, deepset Cloud ignores them.
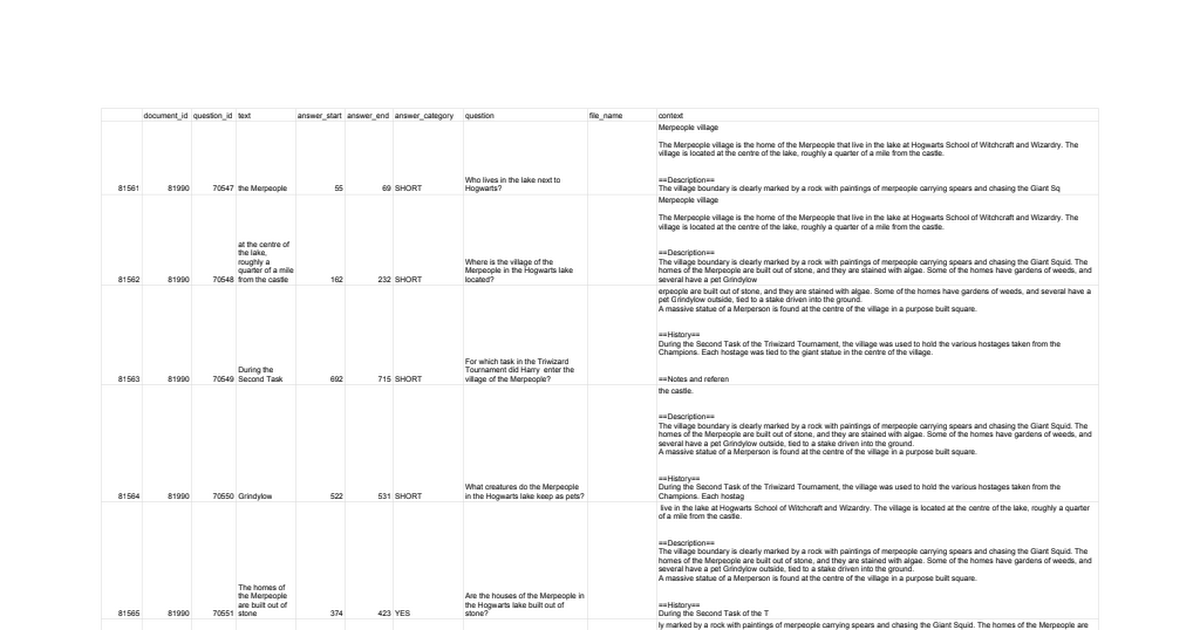
Here's an evaluation dataset for Harry Potter. The additional columns answer_category, question_id, and document_id are ignored in deepset Cloud. This example is meant to show you the format your dataset should follow.
Document Retrieval Dataset
The evaluation dataset must be a CSV file with the following columns:
question: the query text.text: leave this column empty.context: the document to be retrieved as an answer.file_name: the name of the file where the document comes from. This column is optional.filters: any filters that should be used for search. This field is optional. You can use it to add filters you'd use in a real-life search. The filters should be in the following format:{"key1":"value1", "key1":"value2", "key2":"value3"}. If you don't want to use any filters, delete this column. For more information, see Filtering Logic.
Here's an example document retrieval dataset: ms-marco.
Updated 6 months ago