Label Your Data
Label your data using labeling projects to prepare annotated datasets for your pipelines. You can later on use these datasets for experiments.
About This Task
To label your data, create a labeling project and invite labelers to it. This way, you can easily collaborate with others to create labeled datasets.
Currently, deepset Cloud supports labeling for document retrieval pipelines.
There are two roles involved in labeling: the admin and the labelers. The admin creates and configures the project. They need to think about:
- How to pre-filter the documents that are likely to be positive.
You need a pipeline that uses various retrieval methods. The retrieval method used for labeling will always be among the best-performing ones, so the more variation you have, the better. deepset Cloud provides a pipeline template dedicated to labeling and ready for you to use, or you can choose an existing document search pipeline from your workspace.
During labeling, labelers run searches using this pipeline and label the resulting documents. - The guidelines for labelers.
This can include any advice for the labelers or points they should pay attention to. - The number of queries the project should have.
You can set a query target for the project to give the labelers an idea of how many queries you expect them to run. We recommend a minimum of 50 queries. - The files.
Make sure you upload your files. Currently, the project runs on all the files in the workspace.
The labelers run queries and indicate if the retrieved documents are relevant or not.
Once the project is finished and you're happy with the number of labels, you can export them into a .CSV file and use them as an evaluation dataset for experiments.
Coming soon - the Labeler role
Currently only admins can label, but we're working on a separate user role for the labelers. We'll let you know when it's ready.
Creating a Project
You must be an Admin to perform this task.
-
Log in to deepset Cloud.
-
Go to Labeling > New project.
-
Give your project a name and, optionally, a description. Click Create.
You land on the project overview page, where you can see all the tasks you must complete for this project. -
Open the Settings tab to start configuring the project.
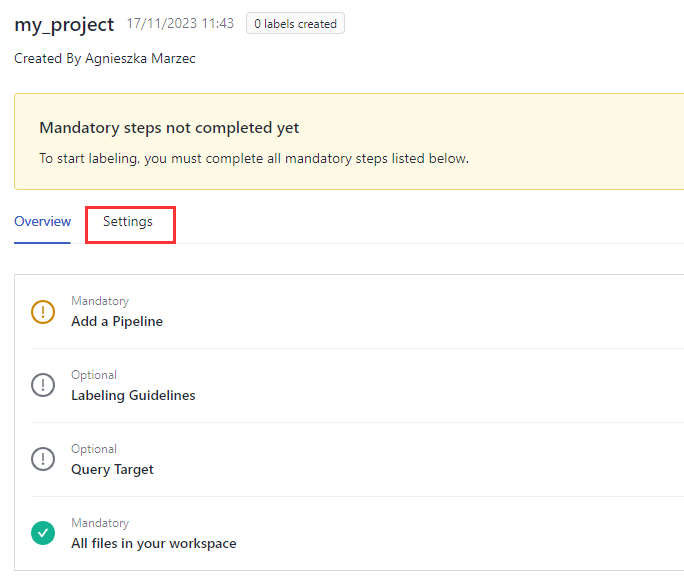
-
Add a pipeline. This pipeline pre-selects documents that are potentially relevant to the query.
- Choose Use Template to use the template prepared especially for labeling, or select a document search pipeline you previously created.
Note: Only document search pipelines are shown as options in the selection menu. - Give your pipeline a name and click Create Pipeline. You're redirected to a new browser tab with the pipeline open in code editor.
- If needed, update the pipeline, then save and deploy it.
Note: Make sure the pipeline is deployed and indexed before you invite labelers to the project.
- Choose Use Template to use the template prepared especially for labeling, or select a document search pipeline you previously created.
-
Go back to the browser tab with your labeling project.
-
Optionally, add labeling guidelines for the users that will be labeling the documents.
-
Set the query target for the project. This is optional. It's the number of queries you want the labelers to run for this project. We recommend at least 50 queries.
-
Make sure there are files in your workspace. The project runs on all the files in the workspace. For detailed instructions on uploading files, see Upload Files.
What To Do Next
Your project is ready. You can now start labeling and invite others to help you as well. Add users to your deepset Cloud organization as Admin users and ask them to start labeling.
When you have the number of labels you need, you can export them into a .CSV file. The format of the files complies with what deepset Cloud experiments require. To download the labels:
-
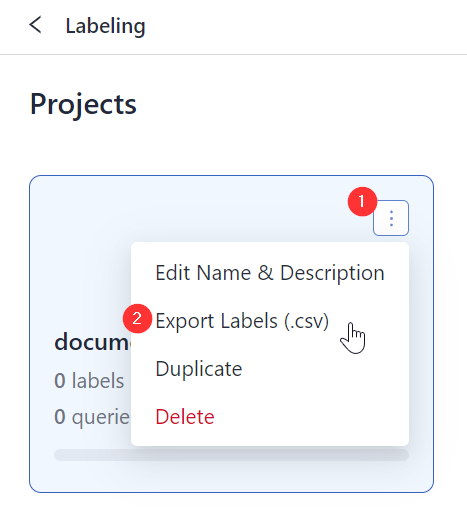
In the navigation, click Labeling.
-
Find the project whose labels you want to download and click the ellipsis button on its card.
-
Choose Export Labels (.csv).
Updated 6 months ago