Improving Your Question Answering Pipeline
It can happen that the experiments fail or fall short of your expectations. It's nothing that can't be fixed. This page helps you figure out how to tweak your question answering pipeline to achieve the results you want.
This page focuses on the extractive QA pipeline analysis here. If your pipeline didn't live up to your expectations, you could consider optimizing PreProcessors, Retriever, or Reader.
Optimizing the Splitter
Splitters, like DocumentSplitter, split your documents into smaller ones. To improve its performance, you can change the value of the split_length parameter. It's best to set this parameter to a value between 200 and 500 words. This is because there is a limit on the number of words an embedding retriever can process. The exact number depends on the model you use for your retriever, but once the document length passes that number, it cuts off the rest of the document.
Optimizing the Retriever
When evaluating the Retriever, it's good to start with OpenSearchBM25Retriever, as it's the standard. Here's what you can try:
- Increase the number of documents the retriever returns. Use the
top_kparameter to do that. This will increase the chances that the retriever sees a document containing the right answer. Doing this, though, slows down the search system as the reader must then check more documents. - Replace the
OpenSearchBM25RetrieverwithOpenSearchEmbeddingRetriever. Have a look at the Models for Information Retrieval and check if any of them outperforms the BM25 retriever. - Send the combined output of both
BM25RetrieverandEmbeddingRetrieverto the next component consuming the documents.
For tips on how to improve the retrieval part of your pipeline, see Improving Your Document Search Pipeline.
Optimizing the Reader
Finding the Right Model
Metrics are an important indicator of your pipeline's performance, but you should also look into the predictions and let other users test your pipeline to get a better understanding of its weaknesses. To get an idea of what metric values you can achieve, check the metrics for state-of-the-art models on Hugging Face. Make sure you're checking the models trained on question answering datasets. Ideally, you should find a dataset that closely mirrors the one you're evaluating in Haystack Enterprise Platform.
For example, to find models trained on a particular dataset in Hugging Face, go to Datasets>Tasks and choose question-answering under the Natural Language Processing category.
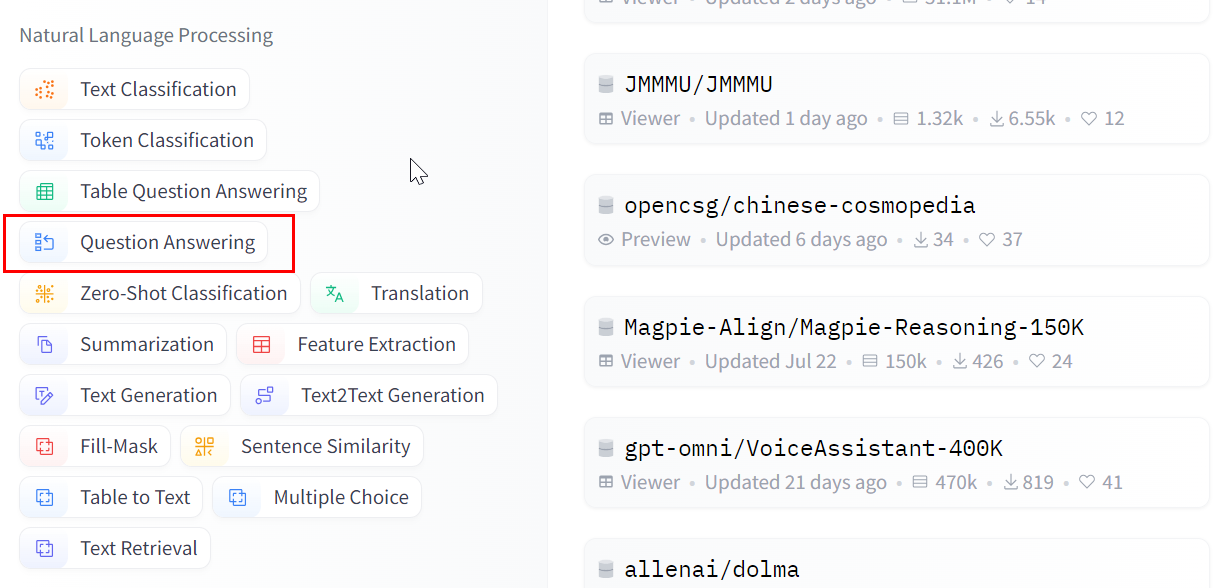
When you click a particular dataset, you can see its details and all the models trained on it. You can then check the model cards for performance benchmarks.
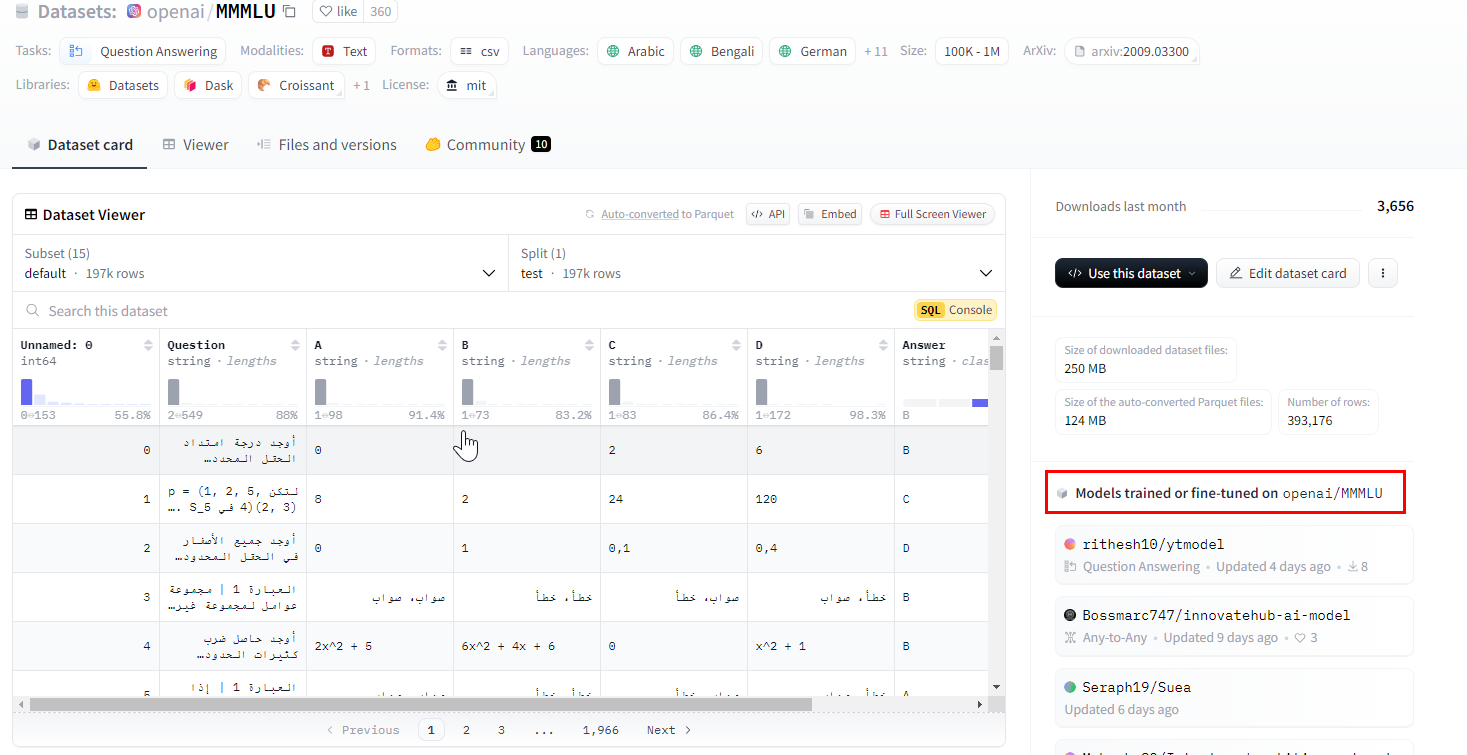
Try different reader models. For more guidance, see Models for Question Answering.
When choosing a model, remember that larger models usually perform better but are slower than smaller ones. You must decide on a balance between reader accuracy and search latency that you're comfortable with.
Fine-Tuning the Reader Model
If you find that none of the available models perform well enough, you can always fine-tune a model. To do that, you need to collect and annotate data. Our experience is that collecting feedback in Haystack Enterprise Platform doesn't boost the reader performance as much as annotated data.
Once you have all the data, fine-tune the best-performing reader models you tried in the previous steps with the data you collected.
Reducing Duplicate Answers
If your search returns duplicate answers coming from overlapping documents, try reducing the split_overlap value of DocumentSplitter to a value around or below 10.
Was this page helpful?