Document Search
A document search system returns whole documents relevant to the query. It’s useful if you’re not looking for a specific answer but rather want to explore and understand the context around your query.
Document Search Applications
Document search is the base for almost any pipeline in Haystack Enterprise Platform. If you’re building a retrieval-augmented generation (RAG) pipeline, document search is the part that feeds the correct document to the large language model (LLM).
If you’re building an extractive question answering (QA) pipeline, the QA model can only find answers in the documents retrieved by the document search part of the pipeline.
How Does It Work?
Document search systems help you find the documents related to your query. The basic component of a document search system is the Retriever. When given a query, the Retriever reviews all documents in your database and fetches the most relevant ones.
Retrieval Types
You can use two types of retrievers in your document search system: keyword-based and vector-based. You can also combine them to take advantage of their strengths.
Keyword-Based Retrieval
This retrieval type uses a keyword-based retriever. An example of such a retriever is OpenSearchBM25Retriever.
Keyword retrievers work with keywords, looking for words shared between the document and the query. They operate on a bag-of-words level and don’t consider the order of words or their contextual meanings, which means they may not capture semantic nuances as effectively as dense retrievers.
These retrievers don’t need any training, are fast and effective, and can work in any language and any domain.
Vector-Based Retrieval
This retrieval type relies on vector-based retrievers, such as OpenSearchEmbeddingRetriever. Vector retrievers use a model to transform both the documents and the query into numerical vectors (embeddings). Then, they compare both embeddings and, based on that, fetch the documents most similar to the query.
Vector retrievers are very good at capturing nuances in queries and documents, recognizing similarities that go beyond keyword matching. They can recognize contextual and semantic information about words and their relationships within a sentence.
Unlike keyword retrievers, vector retrievers need to be trained. This means they perform best in the domain and language they were trained on. They’re also more computationally expensive than keyword-based retrievers.
Hybrid Retrieval
Keyword retrievers are fast and can quickly reduce the number of candidate documents. Vector retrievers are better at capturing semantic nuances, thus improving the relevance of search results.
For example, keyword searches are best when searching for product IDs. When given the query “P12642,” a sparse retriever would fetch “Miura climbing shoes” as a result. Such a query would throw off dense retrievers since they can return results with a similar product ID.
On the other hand, a query like “What are EVs?” would be easier for vector-based retrievers. They would retrieve results like “Electric cars are..” while keyword retrievers would look for the exact keyword match.
Combining both retrieval methods in one system makes it more robust for different kinds of queries and documents.
Once the retrievers fetch the most relevant documents, you can use a combination strategy to produce the final ranking and return the top documents as search results.
A good use case for hybrid retrieval is when your documents are from a niche domain, and it’s unlikely the model was trained on it. Hybrid retrieval saves you the time and money you’d need to train or fine-tune a model, and it’s a good trade-off between speed and accuracy.
Ranking Documents
You can add an additional ranking step to your document search system to sort your documents by relevance, the time they were created, or their metadata field values. This can improve retrieval as some ranking models are more powerful and better than retrievers at determining which documents are relevant. Adding a ranker also makes it possible to consider metadata when ranking documents.
The way ranking works is:
- The retriever fetches documents from the document store.
- The ranking component goes through the documents the retriever fetched and ranks them according to the criteria specified. This may mean putting the most relevant documents first, or ordering documents based on their recentness, and so on.
- The ranked documents are displayed as results.
Ranking may take some time and make the system slightly slower, especially if you use CohereRanker or SentenceTransformersRanker, but there are scenarios where it's crucial to ensure the desired performance. One example is a system that searches through news articles, where the recentness of the articles plays a crucial role.
Applications
Document search is best suited for scenarios where users do not seek a specific, concise answer but want to explore a topic and understand its context. Some common applications include:
- Web search engines
- Academic paper search
- Legal document search
- Enterprise search running on internal databases.
Retrieval-Augmented Generation
Document search is also the first stage in RAG, where the retriever chooses the documents to pass in the prompt to the LLM. The LLM then generates the answer based on these documents rather than its inherent knowledge. This puts a lot of responsibility on the retriever - if the LLM gets incorrect documents, it will generate an incorrect answer.
Document Search in Haystack Enterprise Platform
Haystack Platform offers the following components for building information retrieval systems:
Retrievers- you can choose from both vector-based and keyword-based retrievers.Rankers- for ordering documents based on your specified criteria.
You can use one of the ready-made templates to get you started.
Here’s what an example document search system could look like:
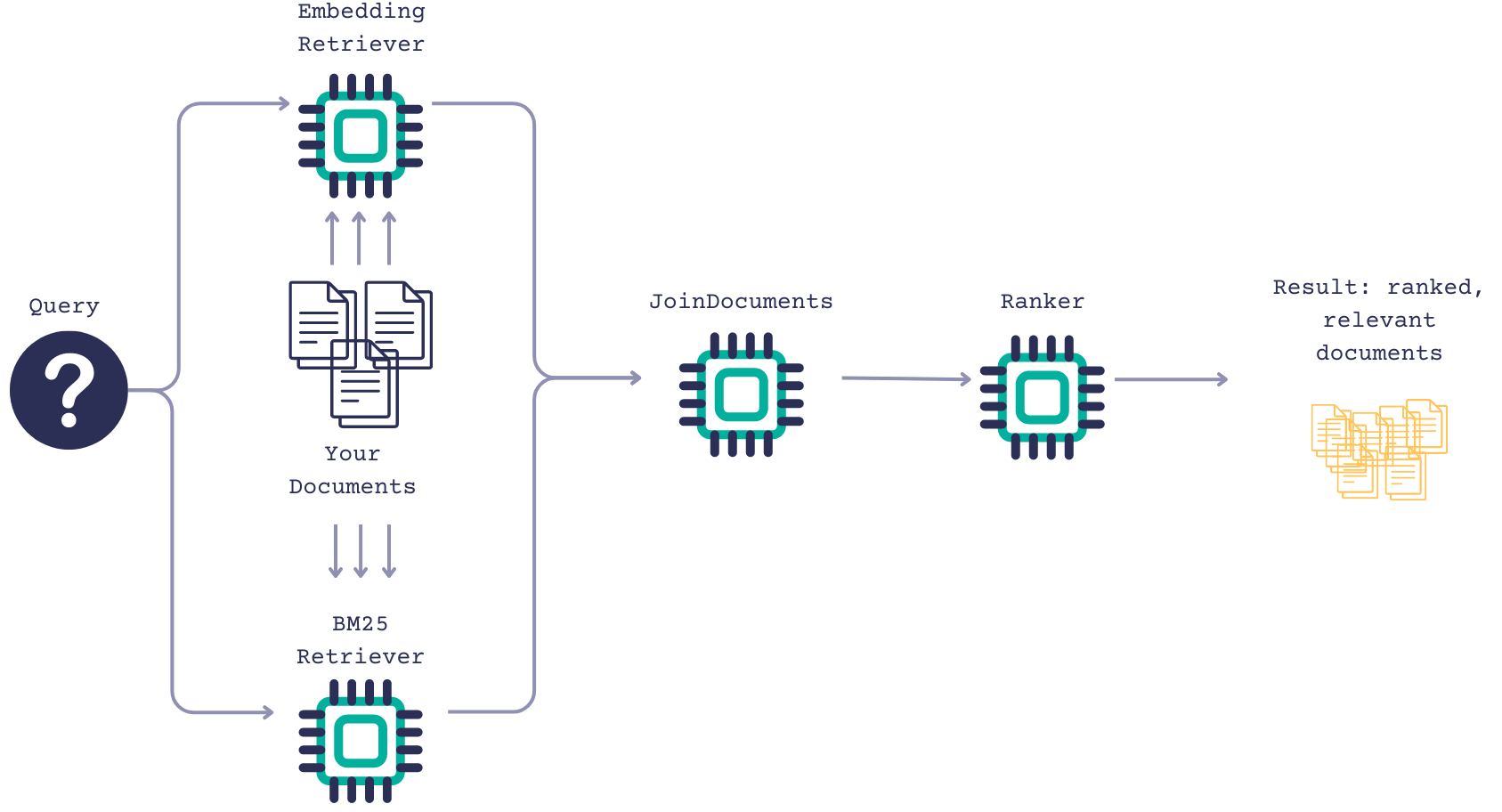
When given a query, the keyword and vector retrievers fetch relevant documents. DocumentJoiner then combines the documents from both retrievers and a ranker ranks these documents. As a result, you get a list of the most relevant documents ranked based on the criteria you specified.
Considerations
Here’s what you should consider before you start building your document search system:
-
Which retriever do you want to use: keyword-based, vector-based, or both?
How you preprocess documents depends on the type of retriever you use. For keyword-based retrievers, you can split your documents into bigger chunks. For vector-based retrievers, you need to adjust the size of documents to the number of tokens the retriever model can process. Check how many tokens the model was trained on and split your documents into chunks within the model token size limit. Usually, chunks of ~250 words work best.
If you’re using hybrid retrieval, you also adjust the document size to the model of the vector-based retriever.
You specify the document size using thesplit_lengthsetting of DocumentSplitter:splitter:
type: haystack.components.preprocessors.document_splitter.DocumentSplitter
init_parameters:
split_by: word
split_length: 250
split_overlap: 30 -
If you chose a vector-based retriever, you must use an
Embedderwith it to turn the documents and the query into vectors. What model do you want to use to embed the texts?
You can check our Embedding Models overview for guidance. -
Do you want to embed your documents’ metadata?
This is possible with EmbeddingRetriever, CohereRanker, and SentenceTransformersRanker. You can vectorize not only document text but also document metadata. For example, if your system will run on company reports, you may embed the name of the company a report comes from if it’s in the document metadata. To do this, pass the names of the metadata fields in themeta_fields_to_embedparameter of the embedder, for example:document_embedder:
type: haystack.components.embedders.sentence_transformers_document_embedder.SentenceTransformersDocumentEmbedder
init_parameters:
model: "intfloat/multilingual-e5-base"
device: null
meta_fields_to_embed: [title, company]
Was this page helpful?