Use Metadata in Your Search System
Attach metadata to the files you upload to Haystack Enterprise Platform and take advantage of them in your search system. Learn about different ways you can use metadata.
Applications of Metadata
Metadata in Haystack Enterprise Platform can serve as filters that narrow down the selection of documents for generating the final answer or to customize retrieval and ranking.
Let's say we have a document with the following metadata:
{
"title": "Mathematicians prove Pólya's conjecture for the eigenvalues of a disk",
"subtitle": "A 70-year old math problem proven",
"authors": ["Alice Wonderland"],
"published_date": "2024-03-01",
"category": "news",
"rating": 2.1
}
We'll refer to these metadata throughout this guide to illustrate different applications.
To learn how to add metadata, see Add Metadata to Your Files.
Metadata as Filters
Metadata acts as filters that narrow down the scope of your search. All metadata from your files are shown as filters in the Playground:
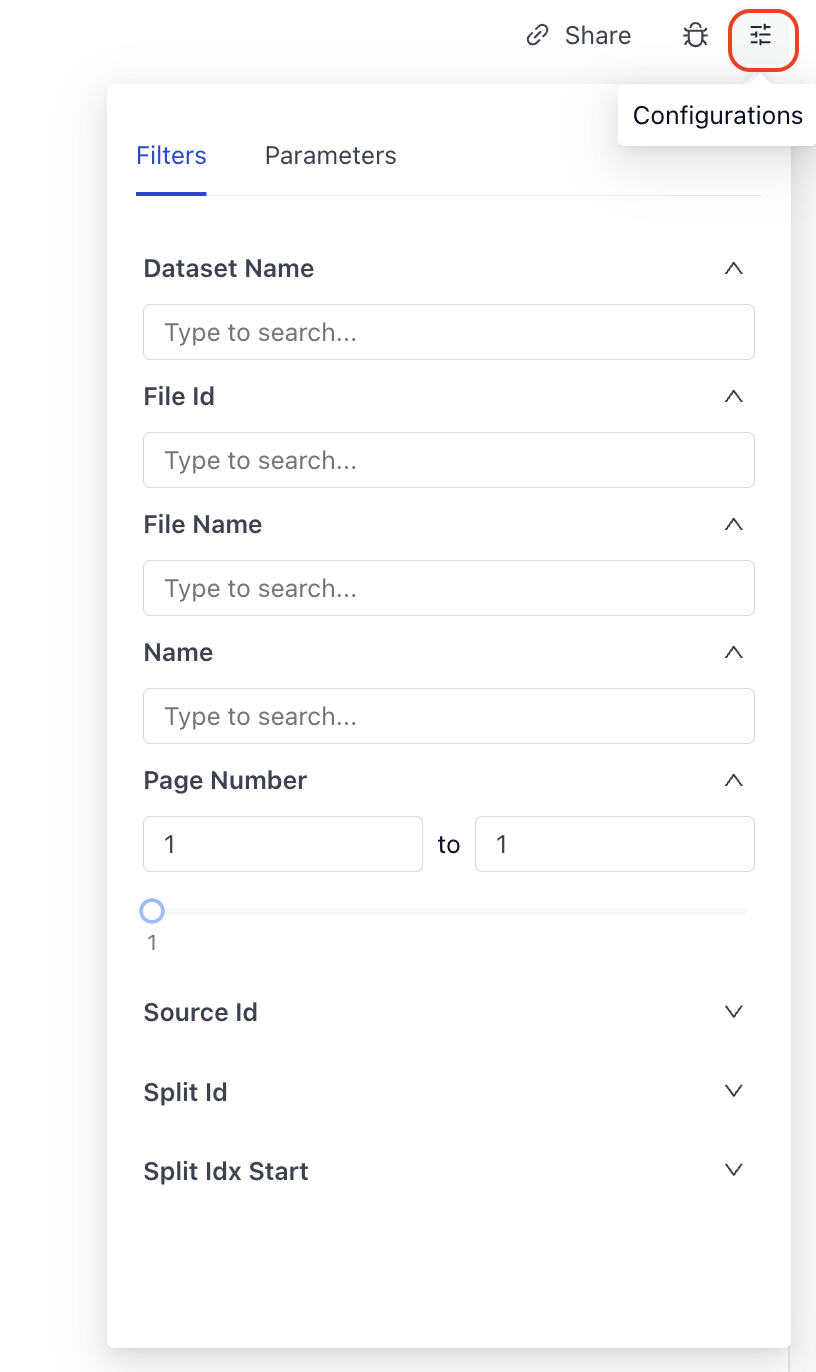
But you can also use metadata to add a preset filter to your pipeline or when searching through REST API.
Filtering with a Preset Filter
You can configure your pipeline to use only documents with specific metadata values. The following components support filters through their filters parameter:
(With MetadataRouter, you can use filters in the rules parameter to route documents matching the filters to specific branches of your pipeline.)
For example, to retrieve only documents of the news category ("category": "news" in metadata) using FilterRetriever, you could pass this query:
components:
retriever:
type: haystack.components.retrievers.filter_retriever.FilterRetriever
init_parameters:
document_store:
type: haystack_integrations.document_stores.opensearch.document_store.OpenSearchDocumentStore
init_parameters:
use_ssl: True
verify_certs: False
http_auth:
- "${OPENSEARCH_USER}"
- "${OPENSEARCH_PASSWORD}"
filters:
field: meta.category
operator: ==
value: "news"
Filtering at Query Time with REST API
When making a search request through API, add the filter to the payload when making the request like this:
--request POST \
--url https://api.cloud.deepset.ai/api/v1/workspaces/WORKSPACE_NAME/pipelines/PIPELINE_NAME/search \
--header 'accept: application/json' \
--header 'authorization: Bearer <your_api_key>' \
--header 'content-type: application/json' \
--data '
{
"debug": false,
"filters": {
"category": "news",
"published_date": "2024"
},
"view_prompts": false,
"queries": [
"What did Alice write?"
]
}
'
See also Filter Syntax.
Embedding Metadata with DocumentEmbedders
DocumentEmbedders can vectorize not only the document text but also the metadata you indicate in the meta_fields_to_embed parameter. In this example, SentenceTransformersDocumentEmbedder embeds the title and subtitle of documents:
components:
document_embedder:
type: haystack.components.embedders.sentence_transformers_document_embedder.SentenceTransformersDocumentEmbedder
init_parameters:
model: "intfloat/e5-base-v2"
meta_fields_to_embed: ["title", "subtitle"]
This means that the title and subtitle would be prepended to the document content.
Metadata for Ranking
When using TransformersSimilarityRanker or CohereRanker, you can assign a higher rank to documents with certain metadata values. To learn more about rankers, see Rankers.
All three rankers mentioned above take the meta_fields_to_embed parameter, where you can pass the metadata fields you want to prioritize. Like with DocumentEmbedders, the values of these fields are then prepended to the document content and embedded there. This means that the content of the metadata fields you indicate is taken into consideration during the ranking. In this example, the Ranker prioritizes documents with fields category and authors:
components:
ranker:
type: haystack.components.rankers.transformers_similarity.TransformersSimilarityRanker
init_parameters:
model: "intfloat/simlm-msmarco-reranker"
top_k: 8
meta_fields_to_embed: ["category", "authors"]
There's also MetaFieldRanker, which sorts documents based on the value of a specific metadata field. It also lets you choose how important the metadata field is in the ranking process. For example, to prioritize documents with the highest rating (assuming the rating is part of the document's metadata), you could use MetaFieldRanker:
components:
ranker:
type: haystack.components.rankers.meta_field.MetaFieldRanker
init_parameters:
meta_field: "rating"
weight: 1.0
Setting weight to 1.0 means MetaFieldRanker only ranks by the metadata field, ignoring any previous rankings or document content.
Metadata in Prompts
You can pass documents' metadata in prompts for additional context and then instruct the LLM to use them. To pass the metadata, you can use the Jinja2 for loop that iterates over the documents displaying its number (loop.index), title (doc.meta['title']), and content (doc.content):
You are a helpful assistant. Please answer the question based on the following documents:
{% for doc in documents %}
Document {{ loop.index }}:
Title: {{ doc.meta['title'] }}
Content: {{ doc.content }}
{% endfor %}
Question: {{ query }}
Answer:
"""
The syntax for accessing a document's metadata is: document.meta['metadata_key'].
Example
Here's an example pipeline that uses metadata during the retrieval, ranking, and answer generation stages. During retrieval, it focuses on documents from the "news" category and embeds the title and subtitle into the document's text. Then, when ranking the documents, it considers the document's title and subtitle. Finally, when generating the answer, it passes the document's published date in the prompt, instructing the LLM to prefer the most recent documents.
components:
bm25_retriever:
type: >-
haystack_integrations.components.retrievers.opensearch.bm25_retriever.OpenSearchBM25Retriever
init_parameters:
document_store:
type: >-
haystack_integrations.document_stores.opensearch.document_store.OpenSearchDocumentStore
init_parameters:
use_ssl: true
verify_certs: false
hosts:
- ${OPENSEARCH_HOST}
http_auth:
- ${OPENSEARCH_USER}
- ${OPENSEARCH_PASSWORD}
embedding_dim: 768
similarity: cosine
top_k: 20
custom_query: >
query:
bool:
must:
- multi_match:
query: $query
type: most_fields
fields:
- content
- title
- authors
operator: OR
filter:
term:
category: news
document_joiner:
type: haystack.components.joiners.document_joiner.DocumentJoiner
init_parameters:
join_mode: concatenate
ranker:
type: >-
haystack.components.rankers.transformers_similarity.TransformersSimilarityRanker
init_parameters:
model: intfloat/simlm-msmarco-reranker
top_k: 8
model_kwargs:
torch_dtype: torch.float16
meta_fields_to_embed:
- title
- subtitle
prompt_builder:
type: haystack.components.builders.prompt_builder.PromptBuilder
init_parameters:
template: >-
You are a media expert.
You answer questions truthfully based on provided documents.
For each document, check whether it is related to the question.
Only use documents that are related to the question to answer it.
Ignore documents that are not related to the question.
If the answer exists in several documents, summarize them.
Only answer based on the documents provided. Don't make things up.
Always use references in the form [NUMBER OF DOCUMENT] when using information from a document. e.g. [3], for Document[3].
The reference must only refer to the number that comes in square brackets after passage.
Otherwise, do not use brackets in your answer and reference ONLY the number of the passage without mentioning the word passage.
If the documents can't answer the question or you are unsure say: 'The answer can't be found in the text'.
For contradictory information, prefer recent documents.
These are the documents:
{% for doc in documents %}
Document {{ loop.index }}:
Title: {{ doc.meta['title'] }}
Subtitle: {{ doc.meta['subtitle'] }}
Published Date: {{ doc.meta['published_date'] }}
Content: {{ doc.content }}
{% endfor %}
Question: {{ question }}
Answer:
llm:
type: haystack.components.generators.openai.OpenAIGenerator
init_parameters:
api_key:
type: env_var
env_vars:
- OPENAI_API_KEY
strict: false
model: gpt-4o
generation_kwargs:
max_tokens: 650
temperature: 0
seed: 0
answer_builder:
type: >-
deepset_cloud_custom_nodes.augmenters.deepset_answer_builder.DeepsetAnswerBuilder
init_parameters:
reference_pattern: acm
FilterRetriever:
type: haystack.components.retrievers.filter_retriever.FilterRetriever
init_parameters:
document_store:
type: >-
haystack_integrations.document_stores.opensearch.document_store.OpenSearchDocumentStore
init_parameters:
use_ssl: true
verify_certs: false
hosts:
- ${OPENSEARCH_HOST}
http_auth:
- ${OPENSEARCH_USER}
- ${OPENSEARCH_PASSWORD}
embedding_dim: 768
similarity: cosine
filters:
category: news
connections:
- sender: bm25_retriever.documents
receiver: document_joiner.documents
- sender: document_joiner.documents
receiver: ranker.documents
- sender: ranker.documents
receiver: prompt_builder.documents
- sender: ranker.documents
receiver: answer_builder.documents
- sender: prompt_builder.prompt
receiver: llm.prompt
- sender: prompt_builder.prompt
receiver: answer_builder.prompt
- sender: llm.replies
receiver: answer_builder.replies
- sender: FilterRetriever.documents
receiver: document_joiner.documents
max_loops_allowed: 100
metadata: {}
inputs:
query:
- bm25_retriever.query
- ranker.query
- prompt_builder.question
- answer_builder.query
filters:
- bm25_retriever.filters
- FilterRetriever.filters
outputs:
documents: ranker.documents
answers: answer_builder.answers
Related Information
Was this page helpful?