Pipeline Components
Components are the fundamental building blocks of your pipelines, dictating the flow of data. Each component performs a designated task on the data and then forwards the results to subsequent components.
How Components Work
Components receive predefined inputs within the pipeline, execute a specific function, and produce outputs. For example, a component may take files, convert them into embeddings, and pass these embeddings on to the next connected component. You have the flexibility to mix, match, and interchange components in your pipelines.
Components are often powered by language models, like LLMs or transformer models, to perform their tasks.
Connecting Components: Inputs and Outputs
Components accept specific inputs and produce defined outputs. To connect components in a pipeline, you must know the types of inputs and outputs they accept. The output type from one component must be compatible with the input type of the subsequent one. For example, to connect a retriever and a ranker in a pipeline, you must know that the retriever outputs List[Document] and the ranker accepts List[Document] as input.
When creating a pipeline in Pipeline Builder, you can click the connector to see the list of popular and compatible connections:
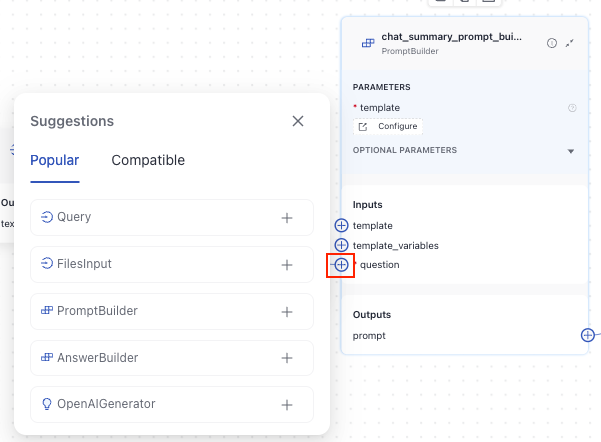
To connect components, click a connection point on one component, then on the other, and you'll see a line formed from one component's output to the other component's input.
When working in YAML, you indicate their output and input names, for example:
...
connections:
- sender: retriever.documents
receiver: ranker.documents
..The output of the sender component can have a different name than the input of the receiver component as long as their types match, as in this example:
...
connections:
- sender: file_type_router.text/plain
receiver: text_converter.sources
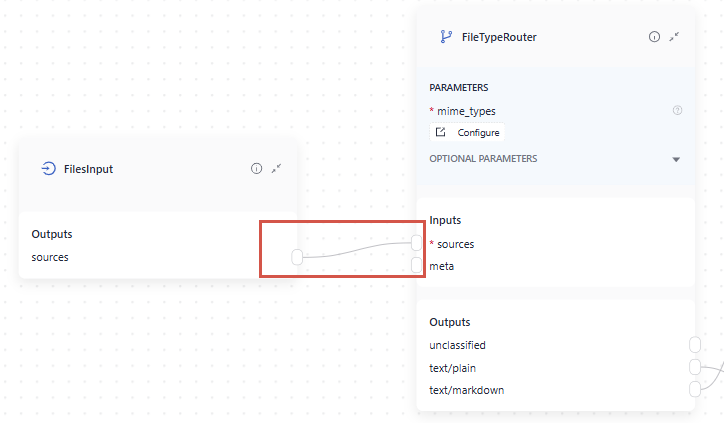
..A component must always receive all of its required inputs. Typically, a component's input can connect to only one output. But, if a component's input type is variadic, it can receive multiple outputs.
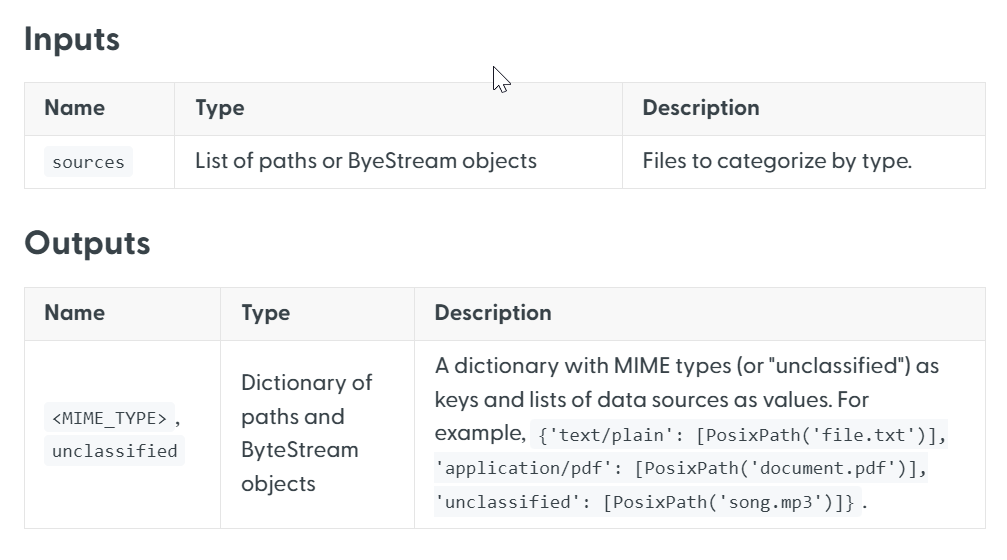
For detailed specifications on what inputs and outputs each component requires and generates, refer to the individual documentation pages for each component. The component's inputs and outputs are listed at the top of the page:
Configuring Components
In Pipeline Builder
In Pipeline Builder, you simply drag components onto the canvas from the component library. You can then customize the component's parameters on the component card:
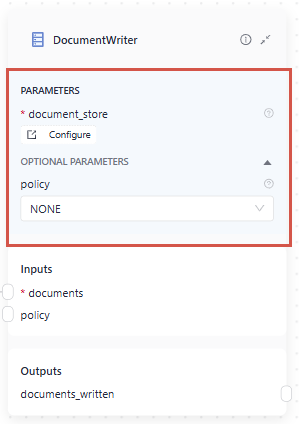
You can change the component name by clicking it and typing in a new name. And that's it!
In YAML
When adding a component to the pipeline YAML configuration, you must add the following information:
-
Component name: This is a custom name you give to a component. You then use this name when configuring the component's connections.
-
Type: Each component has a type you must add to the YAML. You can check the component's type on the component's documentation page:
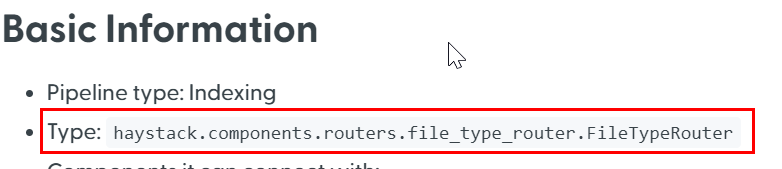
-
Init_parameters: These are the configuration parameters for the component. You can check them on the component's documentation page or in the API reference. To leave the default values, add an empty dictionary:
init_parameters: {}.
This is an example of how you can configure a component in the YAML:
components:
my_component: # this is a custom name
type: haystack.components.routers.file_type_router.FileTypeRouter # this is the component type you can find in component's documentation
init_parameters: {} # this uses the default parameter values
another_component:
type: haystack.components.joiners.document_joiner.DocumentJoiner
init_parameters:
join_mode: concatenate
sort_by_score: falseConnecting Components
As components can have multiple outputs, you must explicitly indicate the component's output you want to send to another component. You configure how components connect in the connections section of the YAML, specifying the custom names of the components and the names of their output and input you want to connect, as in this example:
connections:
# we're connecting the text/plain output of the sender to the sources input of the receiver component
- sender: my_component.text/plain
receiver: text_converter.sourcesIf a component accepts outputs from multiple components, you explicitly define each connection, as in this example:
connections:
- sender: embedding_retriever.documents
receiver: joiner.documents
- sender: bm25_retriever.documents
receiver: joiner.documentsHaystack Components
Haystack is deepset's open source Python framework for building production-ready AI-based systems. deepset AI Platform is based on Haystack and uses its components, pipelines, and methods under the hood. To learn more about Haystack, see the Haystack website.
External Links
deepset AI Platform combines Haystack components with its own unique components. The deepset-specific components are fully documented on this website. For Haystack components, we provide direct links to the official Haystack documentation. To help you differentiate, Haystack components are marked with an arrow icon in the navigation. Clicking on these components will take you to the Haystack documentation page.
Using Haystack Components Documentation
In Haystack, you can run some components on their own. You can see examples of this in the Usage section of each component page. In deepset AI Platform, you can only use components in pipelines. To see usage examples, check the Usage>In a pipeline section.
You can also check the component's code in the Haystack repository. The path to the component is always available at the top of the component documentation page.
Updated about 1 month ago