Extractive Question Answering
This type of question answering (QA) extracts answers directly from the documents by highlighting the span of text that makes up the answer.
How Does It Work?
Extractive QA systems help you find answers to questions within your documents. The documents are processed by a reader model, which identifies and highlights the relevant answers. Unlike generative QA systems, extractive QA systems don't generate new text. Instead, they focus on extracting information from the documents you provide.
Here's an example of what an answer in an extractive QA system may look like:
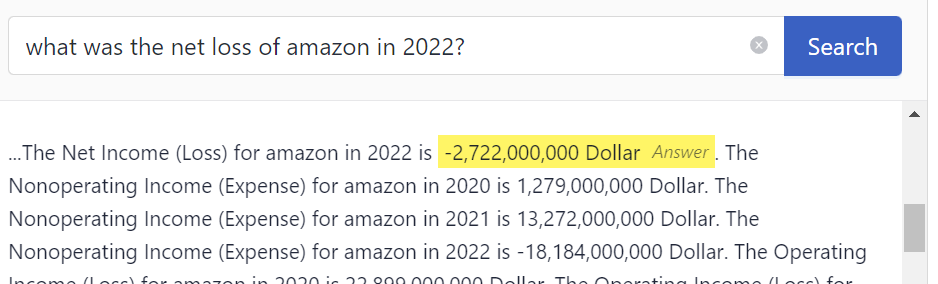
Advantages
Extractive QA systems offer several benefits:
- Factual accuracy: They provide factual answers that you can easily verify because they're highlighted directly in the source.
- Efficiency: Extractive QA systems are often more computationally efficient compared to generative QA systems. Extracting an answer is faster than generating it, and the models used in extractive QA are smaller than those used in generative QA.
- Handling large volumes of text: These systems are well-suited for handling and extracting answers from long documents, such as books or research papers.
- Ability to fine-tune the model: The models used in extractive QA systems are relatively small, and it's easy to train them on your own data.
Challenges
Extractive QA systems also come with a set of challenges you should be aware of:
- Out-of-scope questions: Extractive QA systems excel when providing answers that are present verbatim in the text. They struggle with questions that require synthesizing information or generating answers not directly stated in the document text.
- Document format: Tables may be challenging for extractive QA, as it performs best on textual documents.
- Quality of source data: The accuracy of an extractive QA system heavily depends on the quality of the documents it runs on, as it can't generate answers on its own.
Extractive QA in Haystack Enterprise Platform
A basic extractive QA pipeline in Haystack Enterprise Platform combines a Retriever and an ExtractiveReader. When given a query, the Retriever scans all your documents and retrieves only the ones relevant to the query. It then passes them on to the Reader, which goes only through the retrieved documents and highlights the correct answers. This combination ensures optimal speed and accuracy.
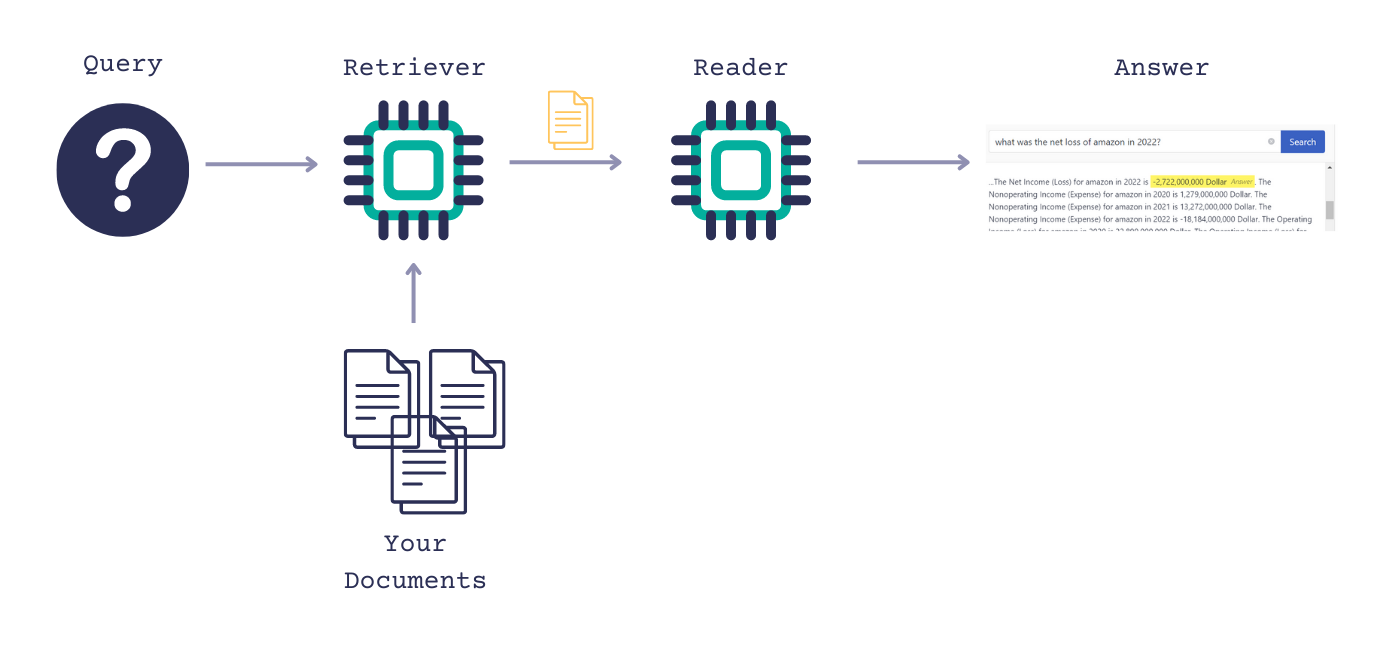
Haystack Enterprise Platform comes with ready-made templates for creating an extractive QA pipeline. These templates work well out of the box, so you only need to modify the name.
Was this page helpful?