Quick Start Guide
Create an AI-powered pipeline using one of our ready-made templates and enjoy the benefits of Haystack Enterprise Platform.
In a nutshell, here are the steps to create a search app:
- Upload your data to the Platform or connect your data source.
- Create an index to prepare your data for search and write it to a database (document store).
- Create a pipeline to build your search application and connect it to the index.
- Test your pipeline and share your prototype with others. Gather feedback and iterate.
- Deploy your pipeline to production.
Set Up Your Workspace
In Haystack Enterprise Platform, you work in workspaces, where you store your files, indexes, and pipelines. You can have up to 100 workspaces in your organization. Let's start by creating a workspace dedicated for your data:
- Log in to Haystack Platform. You land in the
defaultworkspace. - In the upper left corner, click the name of the workspace. This opens a list of workspaces
- Type the name of the new workspace and click Create.
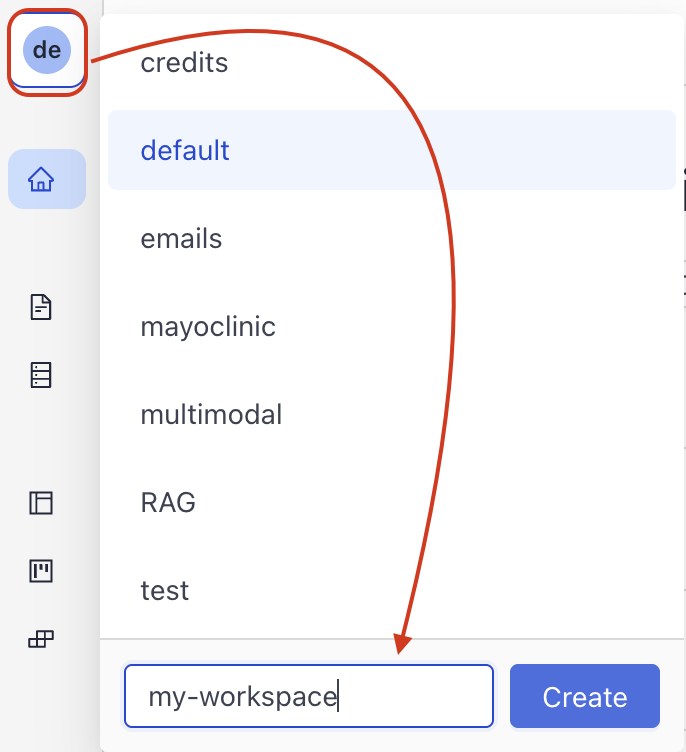
You can switch between workspaces by clicking the name of the workspace and choosing another workspace from the list.
Upload Your Files
You can also use one of the sample datasets we prepared. They're available on the Files page.
Add the files on which you want to run your searches:
- Make sure you're in the workspace you just created, and in the left navigation, go to Files > Upload Files.
- Drag the files from your computer and drop them into the Upload Files window.
- Click Upload. Your files are now listed on the Files page.
You can also use Haystack Platform SDK or REST API endpoints. For details, see Upload Files.
Create an Index
Indexes define how your files are prepared for search and specify the document store where they’re saved. For an easy start, use a template:
- Go to Indexes and click Create Index.
- Choose the Standard Index (English) template. This template works for most use cases.
- Click the template card, give your index a name, and click Create Index.
- Click More actions next to your index and choose Enable. Your files are being indexed. Once the indexing is complete, your query pipeline can run searches on the indexed files.

You can reuse indexes among your query pipelines. To learn more about indexes, see Indexes.
Create a Pipeline
Pipelines in Haystack Platform are the engines powering your apps. A pipeline defines the steps your app takes to resolve a user query.
Now, create a pipeline in the simplest way:
-
In Haystack Enterprise Platform, go to Pipeline Templates.
-
Find a template that best matches your use case, hover over it, and click Use Template.
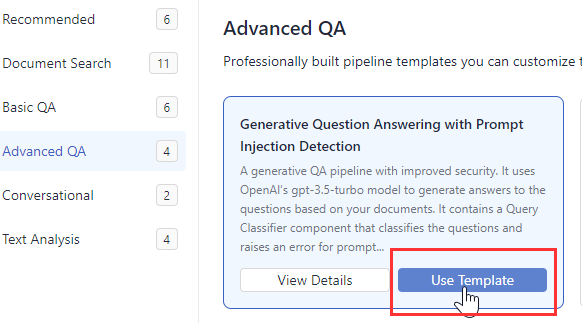
-
Give your pipeline a name and click Create Pipeline. You're redirected to the Builder.
-
Find the
OpenSearchDocumentStorecomponent and click it to open its configuration. This component is an interface to the document store where your indexed files are stored. By default, it's configured to use the index you previously created. Available indexes are shown in the list on the component card.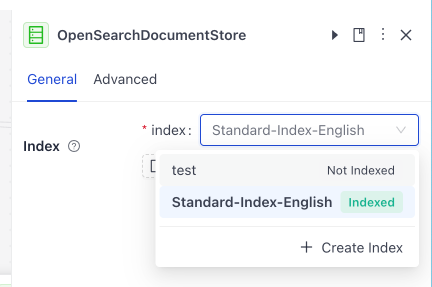
-
Save your pipeline.
-
To test your pipeline, click Run Pipeline next to the
Inputcomponent.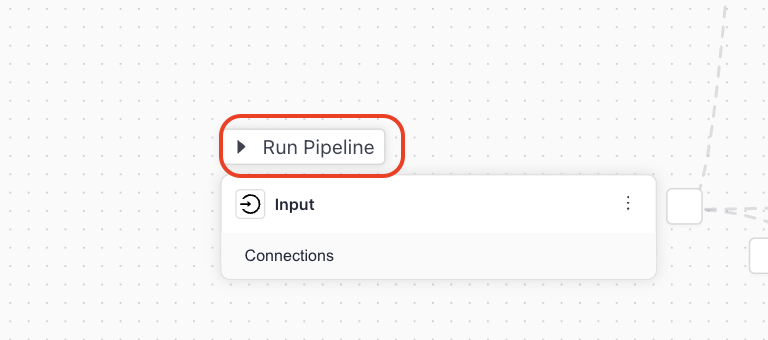
-
To test your pipeline in the Playground or share it with others, deploy it first. Click Deploy in the upper right corner.

For a deeper dive into pipelines and components, see Pipelines and Pipeline Components.
Test Your Pipeline
- In Builder, switch to Playground.
- Choose the pipeline version to test.
- Type a query and click Submit to try out your pipeline. That's it!
What To Do Next?
Have a look at our tutorials, we suggest you start with the basic ones available at Learn the Basics.
For guides on how to perform tasks in Haystack Platform, see the How-to Guides section.
To learn about how things work in Haystack Platform and understand the concepts, see the Concepts section.
Was this page helpful?