Use Case: A Document Search System
This example explains how to set up a system that searches for documents. It describes the benefits of this type of a system, the users, the data and the pipelines you will need.
Description
A document search system, also called document retrieval, is a system that returns whole documents relevant to the query.
A document search system is best if:
- Answers cannot be short spans of text but need to be more complex and long text passages.
- You need a fast system. A document retrieval system doesn't use a reader, which speeds it up significantly.
- You need a system that can handle millions of requests and has very low latency.
- You need a system that can handle natural language questions.
- Word-based approaches like Elasticsearch are not enough for your use case.
Document search is faster and cheaper than a question answering system. It can even work on the CPU in production. Also, the document-search models available are very powerful already, so domain adaptation is easier than it is for question answering.
An example of document search
Here's what a document search system looks like:
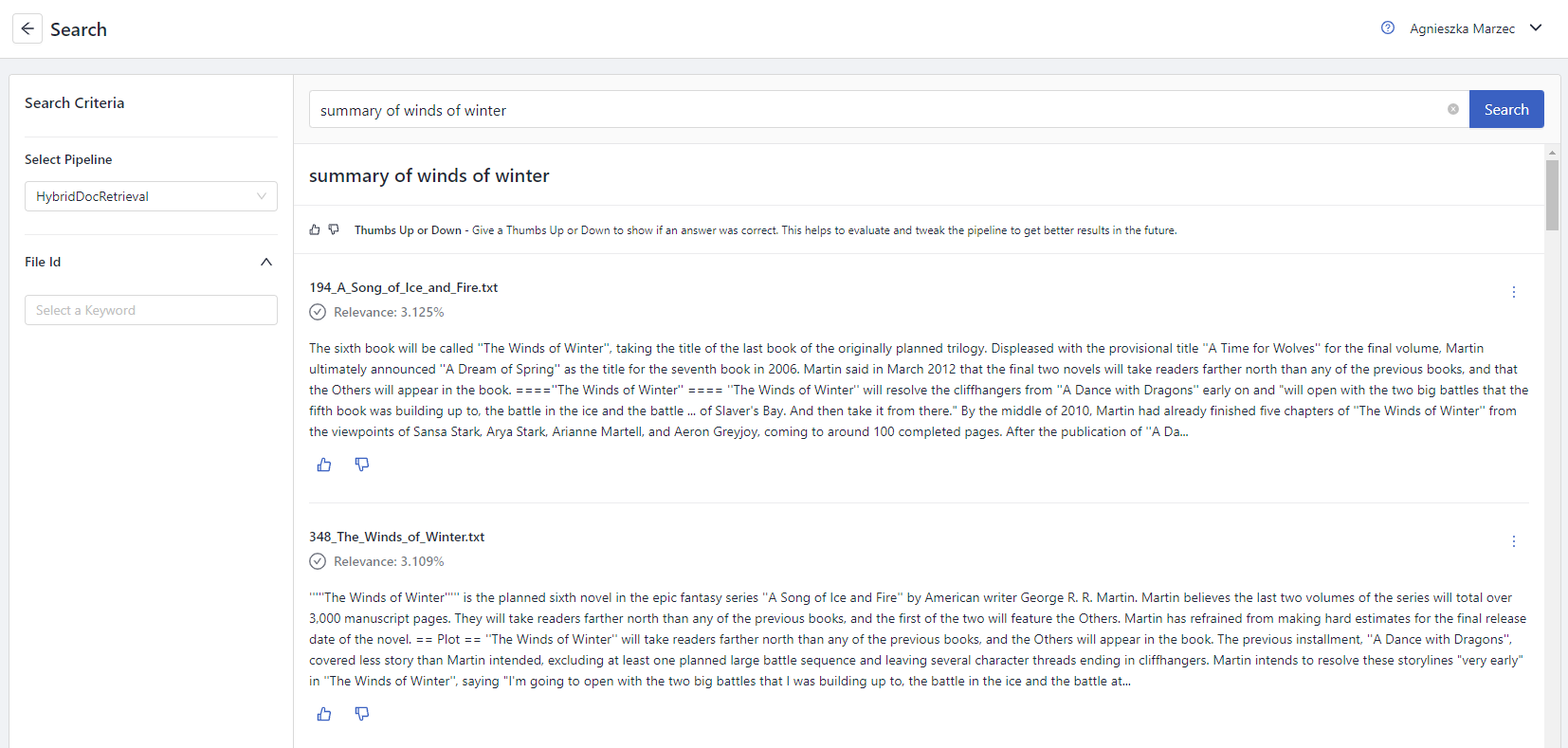
Answers returned by a document search system
Data
You can use any text data. For a fast prototype, your data should be restricted to one domain.
You can divide your data into underlying text data and an annotated set for evaluating your pipelines.
Users
- Data scientists: Design the system, create the pipelines, and supervise domain experts.
- Domain experts: Use the system and provide their feedback in the deepset Cloud interface.
Pipelines
For examples of pipelines, see Document Search Pipelines.
What to Do Next?
You can now demo your search system to the users. Share your pipeline prototype and have them test it. Have a look at the Guidelines for Onboarding Your Users to ensure that your demo is successful.
Updated about 1 month ago