Retrieval Augmented Generation (RAG) Question Answering
Generative question answering (QA) uses large language models (LLMs) to generate human-like, novel responses to user queries. Learn about its advantages, challenges, and how generative QA is done in Haystack Enterprise Platform.
What's RAG QA?
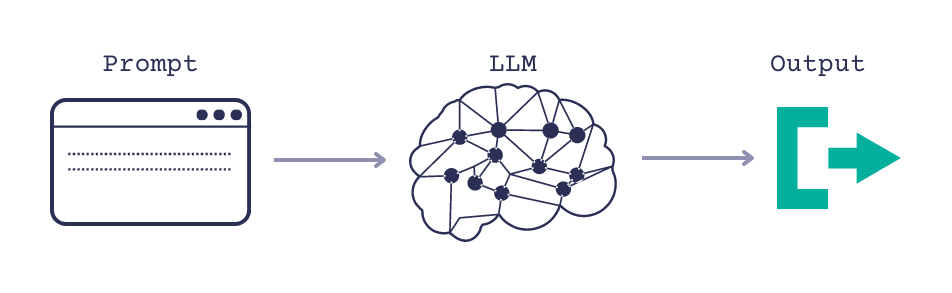
RAG question answering uses large language models to generate human-like responses to user queries in question-answering apps. Instead of simply extracting answers from existing documents, generative systems create new text based on instructions provided in the prompt. A prompt is a specific instruction given to the model in natural language to help it understand the task and generate an appropriate response.
To build a basic RAG QA system, you need a large language model (LLM), like GPT-4, and a simple prompt. Based on the prompt, the model generates an answer.
Advantages
RAG QA offers several advantages compared to extractive QA:
- Extracting information from multiple sources: The system can extract and combine information from various sources to produce coherent and informative answers from scratch.
- Generating original content: LLMs go beyond extracting existing answers and produce more creative and personalized responses. You can use them to create a system that matches your brand voice or feels like talking to a real human.
- Language flexibility: LLMs are trained on large amounts of text, allowing them to generate natural language responses that include idioms or language variations.
- Reasoning capabilities: LLMs have some reasoning capabilities, which make it possible for them to compare facts or draw conclusions.
Challenges
RAG QA systems also have limitations that are important to consider:
- Cost: Proprietary LLMs often come with a price tag. The pricing models are based on the number of tokens processed or per query.
- Limited context length: Models have a maximum token limit they can handle. This includes both the prompt and the generated output. When handling long documents, the model may truncate the generated text to fit within the allowed context length.
- Factual accuracy: Models may generate fictional or incorrect outputs with a high level of confidence. This is known as hallucinations. Hallucinations can occur because of biases in training data or the model's inability to differentiate between factual and fictional information.
- Latency: Generative QA systems are generally slower compared to extractive QA systems.
- Output control: LLMs can sometimes generate harmful, inappropriate, or biased content.
- Evaluation: Evaluating generative models remains challenging. Some of the reasons for that include a lack of objective metrics. Evaluation often involves subjective human judgment, and the diverse outputs make establishing a single ground truth difficult.
Generative QA on Your Data
To mitigate concerns about hallucinations and unreliable answers, you can run a generative QA system on your own data using a retrieval-augmented generation (RAG) approach. This involves limiting the context to a predefined set of documents and adding a Retriever component to your QA system.
In Haystack Enterprise Platform, you can pass your documents in the prompt. When given a query, the Retriever finds the most relevant documents, injects them into the prompt, and passes them on to the generative model. The model uses these documents to produce the final answer.
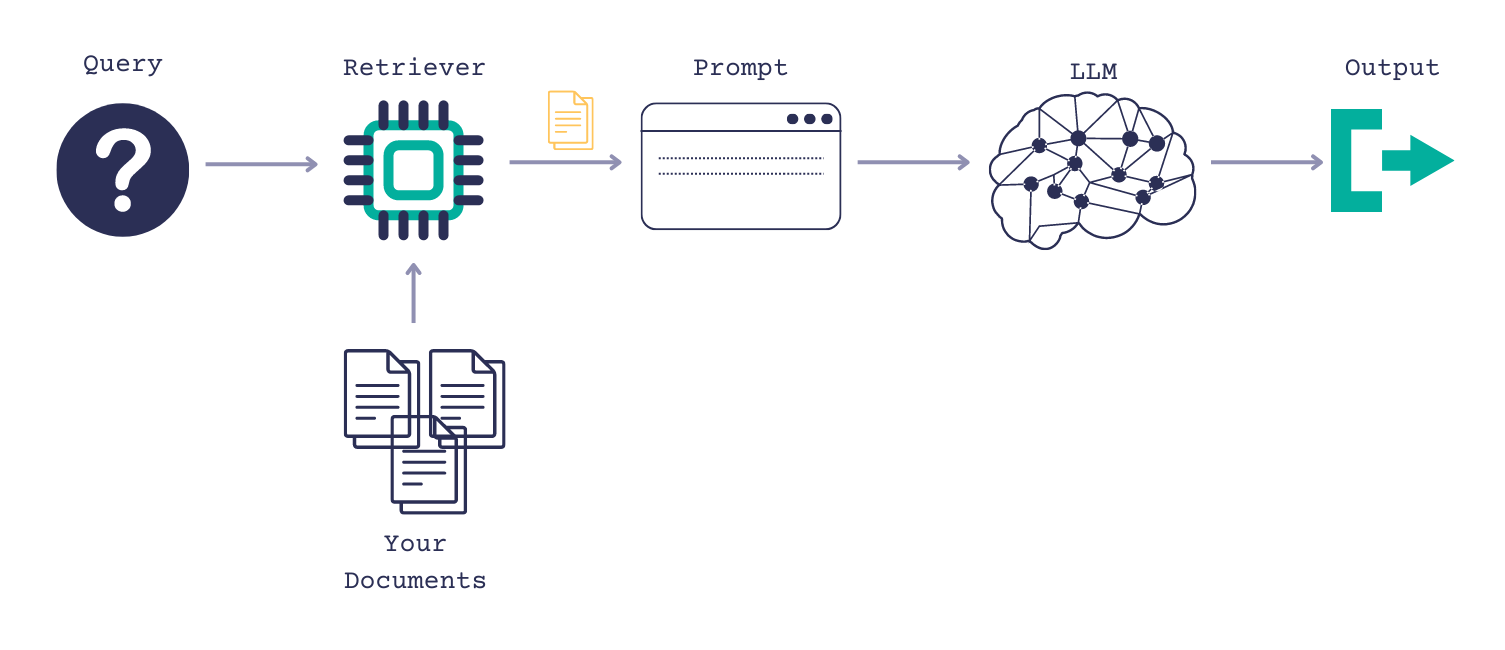
To ensure the generated answers are based on the documents you feed to the model, instruct the LLM to add references to the answer text so that you can verify it's grounded in your data. This helps build a reliable system that users can trust. For details, see Enable References.
Applications
RAG QA systems excel in scenarios where you need novel, natural-language answers and not verbatim from existing documents. Some popular applications include:
- Chatbots, AI assistants, and customer support applications offering personalized assistance across various questions.
- Writing aids and content generation apps automating content creation tasks and assisting with content curation.
- Learning assistants in educational applications, providing explanations and summaries of content.
- Translation aids.
RAG in Haystack Enterprise Platform
RAG pipelines in Haystack Platform:
- Are search systems that generate novel answers based on your data or the model's knowledge of the world, depending on the setup.
- Can work on your own data (retrieval-augmented generation). You can pass the documents in the prompt and filter them with a
Retriever. - Can be chat-based. There is a RAG-Chat pipeline template that you can use out of the box and then test in Playground.
Haystack Platform supports you throughout the process of creating a generative QA system by:
- Providing pipeline templates, ready to use.
- Providing Prompt Explorer, which is a sandbox environment for prompt engineering.
- Offering a library of tested and curated prompts you can reuse and modify as needed.
Haystack Platform provides templates with models by OpenAI, Claude by Anthropic, Command by Cohere, and more. But even if you choose a template with a specific model, you can then easily swap it for another one by choosing a different model in the component settings.
Was this page helpful?