Use OpenAI Models
Use OpenAI models in your pipelines.
About This Task
You can use OpenAI's embedding models and LLMs:
- For a list of embedding models, see OpenAI documentation.
- For a list of LLMs, see OpenAI model overview.
Prerequisites
You need an API key from an active OpenAI account. For details on obtaining it, see Secret keys in OpenAI.
Use OpenAI Models
First, connect Haystack Enterprise Platform to OpenAI through the Integrations page. You can set up the connection for a single workspace or for the whole organization:
Add Workspace-Level Integration
- Click your profile icon and choose Settings.
- Go to Workspace>Integrations.
- Find the provider you want to connect and click Connect next to them.
- Enter the API key and any other required details.
- Click Connect. You can use this integration in pipelines and indexes in the current workspace.
Add Organization-Level Integration
- Click your profile icon and choose Settings.
- Go to Organization>Integrations.
- Find the provider you want to connect and click Connect next to them.
- Enter the API key and any other required details.
- Click Connect. You can use this integration in pipelines and indexes in all workspaces in the current organization.
Then, add a component that uses an OpenAI model to your pipeline. Here are the components by the model type they use:
-
Embedding models:
OpenAITextEmbedder: Calculates embeddings for text, like query. Often used in query pipelines to embed a query and pass the embedding to an embedding retriever.OpenAIDocumentEmbedder: Calculates embeddings for documents. Often used in indexes to embed documents and pass them toDocumentWriter.Embedding Models in Pipelines and IndexesThe embedding model you use to embed documents in your index must be the same as the embedding model you use to embed the query in your pipeline.
This means the embedders for your indexes and pipelines must match. For example, if you use
CohereDocumentEmbedderto embed your documents, you should useCohereTextEmbedderwith the same model to embed your queries.
-
LLMs:
OpenAIChatGenerator: Generates text using OpenAI models, often used in RAG pipelines.LLM: Generates text using OpenAI models, often used in RAG pipelines.
Available OpenAI LLMs
The following OpenAI LLMs are available in Haystack Enterprise Platform:
| Model | Description |
|---|---|
| GPT-5.6 Sol | Latest GPT-5.6 variant with reasoning_effort and reasoning_summary parameters. |
| GPT-5.6 Terra | Latest GPT-5.6 variant with reasoning_effort and reasoning_summary parameters. |
| GPT-5.6 Luna | Latest GPT-5.6 variant with reasoning_effort and reasoning_summary parameters. |
| GPT-5.5 | GPT-5.5 with reasoning_effort and reasoning_summary parameters. |
| GPT-5.5 Pro | GPT-5.5 Pro variant. |
| GPT-5.4 | GPT-5.4 model. |
| GPT-5.4 Pro | GPT-5.4 Pro variant. |
| GPT-5.4 mini | Smaller, faster GPT-5.4 variant. |
| GPT-5.4 nano | Compact GPT-5.4 variant. |
| GPT-5.2 | GPT-5.2 model. |
| GPT-5.2 Pro | GPT-5.2 Pro variant (no text-to-speech support). |
| GPT-5.1 | GPT-5.1 model. |
| GPT-5 | GPT-5 base model. |
| GPT-5 Pro | GPT-5 Pro variant. |
| GPT-5 mini | Smaller, faster GPT-5 variant. |
| GPT-5 nano | Compact GPT-5 variant. |
| GPT-4.1 | GPT-4.1 model. |
| GPT-4.1 mini | Smaller GPT-4.1 variant. |
| GPT-4.1 nano | Compact GPT-4.1 variant. |
| GPT-4o | GPT-4o model. |
| GPT-4o mini | Smaller GPT-4o variant. |
| GPT-3.5 Turbo | GPT-3.5 Turbo model. |
Usage Examples
This is an example of how to use OpenAI's embedding models and an LLM in an index and a query pipeline (each in a separate tab):
- Index
- Query Pipeline
components:
# ...
splitter:
type: haystack.components.preprocessors.document_splitter.DocumentSplitter
init_parameters:
split_by: word
split_length: 250
split_overlap: 30
document_embedder:
type: haystack.components.embedders.openai_document_embedder.OpenAIDocumentEmbedder
init_parameters:
model: text-embedding-ada-002 # the model to use
writer:
type: haystack.components.writers.document_writer.DocumentWriter
init_parameters:
document_store:
type: haystack_integrations.document_stores.opensearch.document_store.OpenSearchDocumentStore
init_parameters:
embedding_dim: 768
similarity: cosine
policy: OVERWRITE
connections: # Defines how the components are connected
# ...
- sender: splitter.documents
receiver: document_embedder.documents
- sender: document_embedder.documents
receiver: writer.documents
# haystack-pipeline
pipeline_output_type: "chat"
components:
retriever:
# Selects the most similar documents from the document store
type: haystack_integrations.components.retrievers.opensearch.open_search_hybrid_retriever.OpenSearchHybridRetriever
init_parameters:
document_store:
type: haystack_integrations.document_stores.opensearch.document_store.OpenSearchDocumentStore
init_parameters:
embedding_dim: 768
index: Standard-Index-English
max_chunk_bytes: 104857600
return_embedding: false
create_index: true
settings:
index.knn: true
top_k: 20 # The number of results to return
embedder:
type: haystack.components.embedders.openai_text_embedder.OpenAITextEmbedder
init_parameters:
model: text-embedding-ada-002
fuzziness: 0
ranker:
type: haystack.components.rankers.transformers_similarity.TransformersSimilarityRanker
init_parameters:
model: intfloat/simlm-msmarco-reranker
top_k: 8
device: null
meta_field_grouping_ranker:
type: haystack.components.rankers.meta_field_grouping_ranker.MetaFieldGroupingRanker
init_parameters:
group_by: file_id
subgroup_by:
sort_docs_by: split_id
qa_llm:
type: haystack.components.generators.chat.llm.LLM
init_parameters:
# You can swap this for any other model. Switch to the Builder view and choose another model from the list on the component card.
chat_generator:
init_parameters:
model: gpt-5.4
type: haystack.components.generators.chat.openai_responses.OpenAIResponsesChatGenerator
system_prompt:
user_prompt: >-
{% message role="user" %}
You are a technical expert.
You answer questions truthfully based on provided documents.
Ignore typing errors in the question.
For each document check whether it is related to the question.
Only use documents that are related to the question to answer it.
Ignore documents that are not related to the question.
If the answer exists in several documents, summarize them.
Only answer based on the documents provided. Don't make things up.
Just output the structured, informative and precise answer and nothing
else.
If the documents can't answer the question, say so.
Always use references in the form [NUMBER OF DOCUMENT] when using
information from a document, e.g. [3] for Document [3] .
Never name the documents, only enter a number in square brackets as a
reference.
The reference must only refer to the number that comes in square
brackets after the document.
Otherwise, do not use brackets in your answer and reference ONLY the
number of the document without mentioning the word document.
These are the documents:
{%- if documents|length > 0 %}
{% for document in documents %}
Document [{{ loop.index }}] :
Name of Source File: {{ document.meta.file_name }}
{{ document.content }}
{% endfor %}
{%- else %}
No relevant documents found.
Respond with "Sorry, no matching documents were found, please adjust the
filters or try a different question."
{% endif %}
Question: {{ question.text }}
Answer:
{% endmessage %}
required_variables: "*"
streaming_callback:
connections:
- sender: retriever.documents
receiver: ranker.documents
- sender: ranker.documents
receiver: meta_field_grouping_ranker.documents
- sender: meta_field_grouping_ranker.documents
receiver: qa_llm.documents
inputs:
filters:
- retriever.filters_bm25
- retriever.filters_embedding
files: []
query:
- qa_llm.question
- ranker.query
- retriever.query
outputs:
documents: meta_field_grouping_ranker.documents
messages: qa_llm.messages
updated_query:
max_runs_per_component: 100
metadata: {}
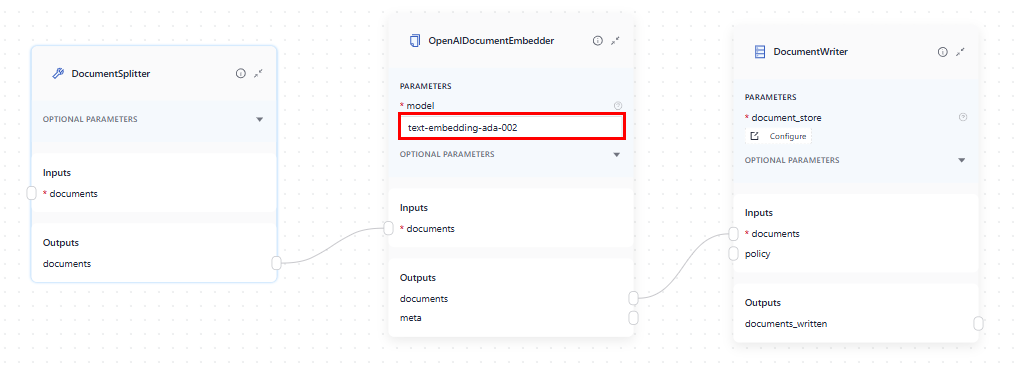
Here is how to connect the components in Pipeline Builder. In the index, OpenAIDocumentEmbedder receives documents from DocumentSplitter and then passes the embedded documents to DocumentWriter, which writes them into the Document Store:
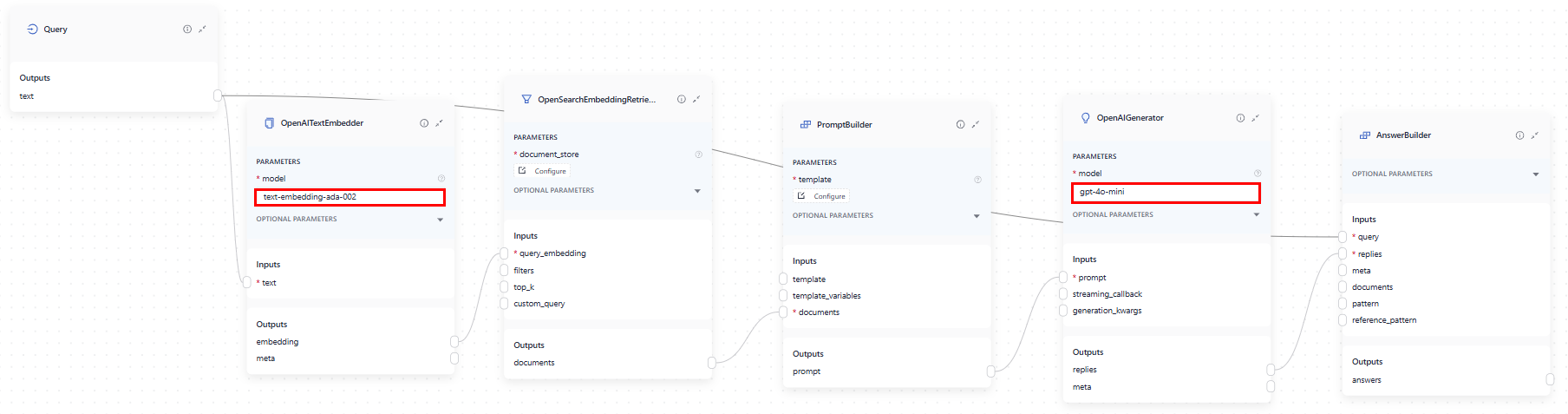
In a query pipeline, OpenAITextEmbedder embeds the query using the same model as the OpenAIDocumentEmbedder in the index. Then, it sends the embedded query to the retriever, which fetches matching documents and sends them to PromptBuilder. OpenAIGenerator then receives the rendered prompt from the PromptBuilder and sends the generated replies to AnswerBuilder to build a proper GeneratedAnswer object.
Related Information
Was this page helpful?