DeepsetAzureOpenAIVisionGenerator
Generate text using text and image capabilities of OpenAI's LLMs through Azure services.
This component is deprecated. It will continue to work in your existing pipelines for now. You can replace it with the AzureOpenAIChatGenerator` component.
DeepsetAzureOpenAIVisionGenerator works with GPT-4 and GPT-3.5 turbo families of models hosted on Azure. These models can understand images, making it possible to describe them, analyze details, and answer questions based on images. For details and limitations, check OpenAI's Vision documentation.
Key Features
- Accepts both text prompts and images (as
Base64Imageobjects) for multimodal generation. - Works with GPT-4 and GPT-3.5 turbo families of models hosted on Azure.
- Supports streaming responses token by token.
- Customizable generation via
generation_kwargs, includingmax_tokens,temperature,top_p, and more.
Configuration
- Drag the
DeepsetAzureOpenAIVisionGeneratorcomponent onto the canvas from the Component Library. - Click on the component to open the configuration panel.
- On the General tab:
- Enter the Azure Endpoint (for example,
https://example-resource.azure.openai.com/). - Enter the Azure Deployment name (usually the model name, for example,
gpt-4o). - Enter the API Version (for example,
2023-05-15). - Make sure Haystack Platform is connected to Azure OpenAI. You need an Azure OpenAI API key and endpoint. For help, see Add Integrations.
- Enter the Azure Endpoint (for example,
- Go to the Advanced tab to configure
system_prompt,streaming_callback,generation_kwargs,timeout,max_retries, anddefault_headers.
Connections
DeepsetAzureOpenAIVisionGenerator receives a text prompt from PromptBuilder through its prompt input and a list of Base64Image objects (typically from DeepsetPDFDocumentToBase64Image) through its images input. It outputs generated text as a list of strings through its replies output, which you connect to DeepsetAnswerBuilder.
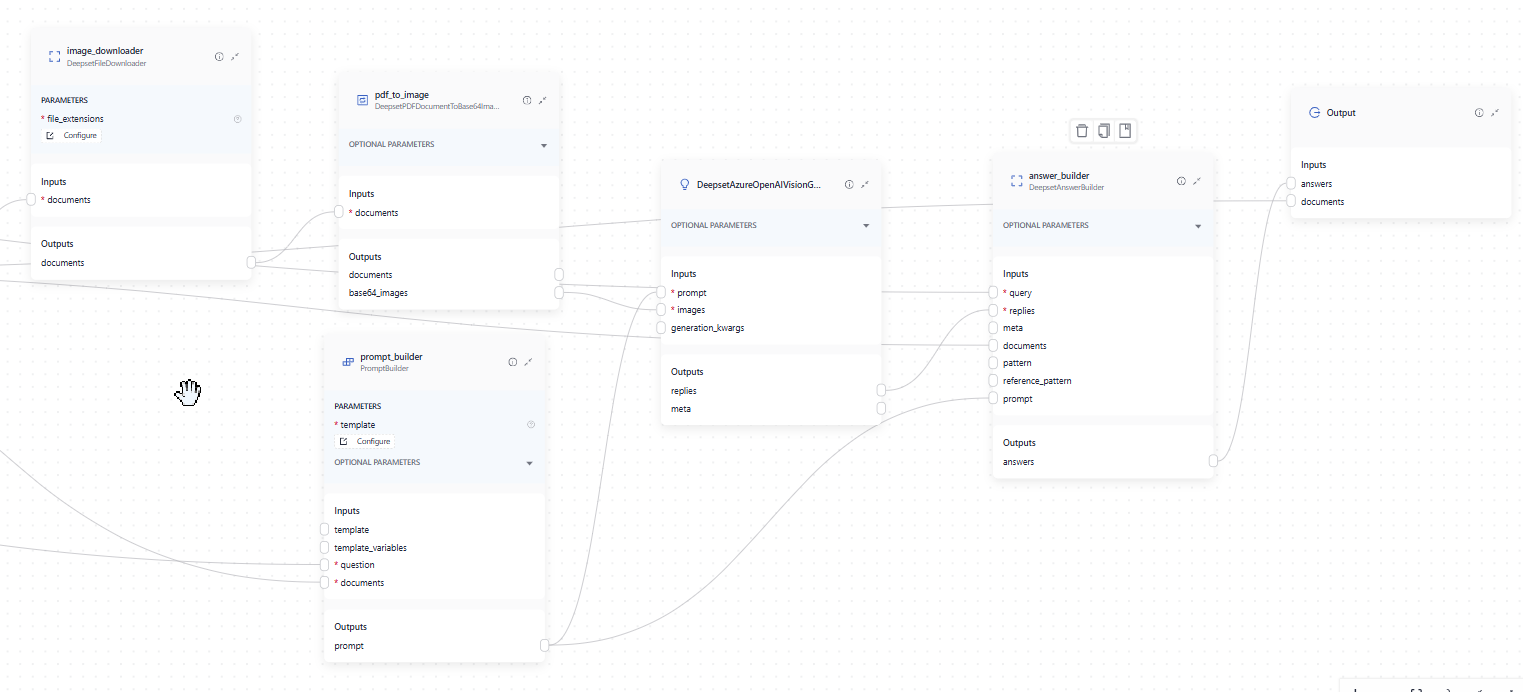
Here's an example of the pipeline in Pipeline Builder:
Usage Examples
Basic Configuration
DeepsetAzureOpenAIVisionGenerator:
type: deepset_cloud_custom_nodes.generators.azure_openai_vision.DeepsetAzureOpenAIVisionGenerator
init_parameters:
azure_endpoint: <endpoint>
api_version: '2023-05-15'
azure_deployment: gpt-4o
generation_kwargs:
max_tokens: 650
temperature: 0
seed: 0
Using the Component in a Pipeline
Here's an example of a query pipeline with DeepsetAzureOpenAIVisionGenerator. It's preceded by DeepsetFileDownloader (image_downloader), which downloads the documents returned by previous components, such as a Ranker or DocumentJoiner. It then sends the downloaded files to DeepsetPDFDocumentToBase64Image (pdf_to_image), which converts them into Base64Image objects that DeepsetAzureOpenAIVisionGenerator can take in. The Generator also receives the prompt from the PromptBuilder. It then sends the generated replies to DeepsetAnswerBuilder.
# haystack-pipeline
components:
bm25_retriever:
type: haystack_integrations.components.retrievers.opensearch.bm25_retriever.OpenSearchBM25Retriever
init_parameters:
document_store:
type: haystack_integrations.document_stores.opensearch.document_store.OpenSearchDocumentStore
init_parameters:
use_ssl: true
verify_certs: false
hosts:
- ${OPENSEARCH_HOST}
http_auth:
- ${OPENSEARCH_USER}
- ${OPENSEARCH_PASSWORD}
embedding_dim: 1024
similarity: cosine
top_k: 20
query_embedder:
type: haystack.components.embedders.sentence_transformers_text_embedder.SentenceTransformersTextEmbedder
init_parameters:
model: BAAI/bge-m3
tokenizer_kwargs:
model_max_length: 1024
embedding_retriever:
type: haystack_integrations.components.retrievers.opensearch.embedding_retriever.OpenSearchEmbeddingRetriever
init_parameters:
document_store:
type: haystack_integrations.document_stores.opensearch.document_store.OpenSearchDocumentStore
init_parameters:
use_ssl: true
verify_certs: false
hosts:
- ${OPENSEARCH_HOST}
http_auth:
- ${OPENSEARCH_USER}
- ${OPENSEARCH_PASSWORD}
embedding_dim: 1024
similarity: cosine
top_k: 20
document_joiner:
type: haystack.components.joiners.document_joiner.DocumentJoiner
init_parameters:
join_mode: concatenate
ranker:
type: haystack.components.rankers.transformers_similarity.TransformersSimilarityRanker
init_parameters:
model: BAAI/bge-reranker-v2-m3
top_k: 8
model_kwargs:
torch_dtype: torch.float16
tokenizer_kwargs:
model_max_length: 1024
meta_fields_to_embed:
- file_name
image_downloader:
type: deepset_cloud_custom_nodes.augmenters.deepset_file_downloader.DeepsetFileDownloader
init_parameters:
file_extensions:
- .pdf
pdf_to_image:
type: deepset_cloud_custom_nodes.converters.pdf_to_image.DeepsetPDFDocumentToBase64Image
init_parameters:
detail: high
prompt_builder:
type: haystack.components.builders.prompt_builder.PromptBuilder
init_parameters:
template: |-
Answer the questions briefly and precisely using the images and text passages provided.
Only use images and text passages that are related to the question to answer it.
In your answer, only refer to images and text passages that are relevant in answering the query.
Only use references in the form [NUMBER OF IMAGE] if you are using information from an image.
Or [NUMBER OF DOCUMENT] if you are using information from a document.
These are the documents:
{% for document in documents %}
Document[ {{ loop.index }} ]:
File Name: {{ document.meta['file_name'] }}
Text only version of image number {{ loop.index }} that is also provided.
{{ document.content }}
{% endfor %}
Question: {{ question }}
Answer:
answer_builder:
type: deepset_cloud_custom_nodes.augmenters.deepset_answer_builder.DeepsetAnswerBuilder
init_parameters:
reference_pattern: acm
TopKDocuments:
type: haystack.components.joiners.document_joiner.DocumentJoiner
init_parameters:
top_k: 8
DeepsetAzureOpenAIVisionGenerator:
type: deepset_cloud_custom_nodes.generators.azure_openai_vision.DeepsetAzureOpenAIVisionGenerator
init_parameters:
azure_endpoint: <endpoint>
api_version: '2023-05-15'
azure_deployment: gpt-4o
generation_kwargs:
max_tokens: 650
temperature: 0
seed: 0
connections:
- sender: bm25_retriever.documents
receiver: document_joiner.documents
- sender: query_embedder.embedding
receiver: embedding_retriever.query_embedding
- sender: embedding_retriever.documents
receiver: document_joiner.documents
- sender: document_joiner.documents
receiver: ranker.documents
- sender: image_downloader.documents
receiver: pdf_to_image.documents
- sender: prompt_builder.prompt
receiver: answer_builder.prompt
- sender: ranker.documents
receiver: prompt_builder.documents
- sender: ranker.documents
receiver: TopKDocuments.documents
- sender: TopKDocuments.documents
receiver: image_downloader.documents
- sender: ranker.documents
receiver: answer_builder.documents
- sender: prompt_builder.prompt
receiver: DeepsetAzureOpenAIVisionGenerator.prompt
- sender: pdf_to_image.base64_images
receiver: DeepsetAzureOpenAIVisionGenerator.images
- sender: DeepsetAzureOpenAIVisionGenerator.replies
receiver: answer_builder.replies
max_loops_allowed: 100
metadata: {}
inputs:
query:
- bm25_retriever.query
- query_embedder.text
- ranker.query
- prompt_builder.question
- answer_builder.query
filters:
- embedding_retriever.filters
- bm25_retriever.filters
outputs:
answers: answer_builder.answers
documents: ranker.documents
Parameters
Inputs
| Parameter | Type | Description |
|---|---|---|
prompt | str | The prompt with instructions for the model. |
images | List[Base64Image] | A list of Base64Images that represent the image content of the message. The base64 encoded images are passed to OpenAI for text generation. |
generation_kwargs | Optional[Dict[str, Any]] | Additional keyword arguments for text generation. These parameters potentially override the parameters in pipeline configuration. |
Outputs
| Parameter | Type | Description |
|---|---|---|
replies | List[str] | A list of strings containing the generated responses. |
meta | List[Dict[str, Any]] | A list of dictionaries containing the metadata for each response. |
Init Parameters
These are the parameters you can configure in Pipeline Builder:
| Parameter | Type | Default | Description |
|---|---|---|---|
azure_endpoint | Optional[str] | None | The endpoint of the deployed model, for example https://example-resource.azure.openai.com/. |
api_version | Optional[str] | 2023-05-15 | The version of the API to use. |
azure_deployment | Optional[str] | gpt-4o | The deployment of the model, usually the model name. |
api_key | Optional[Secret] | Secret.from_env_var('AZURE_OPENAI_API_KEY', strict=False) | The API key to use for authentication. |
azure_ad_token | Optional[Secret] | Secret.from_env_var('AZURE_OPENAI_AD_TOKEN', strict=False) | Azure Active Directory token. |
organization | Optional[str] | None | Your organization ID. For help, see Setting up your organization. |
streaming_callback | Optional[Callable[[StreamingChunk], None]] | None | A callback function called when a new token is received from the stream. |
system_prompt | Optional[str] | None | The system prompt to use for text generation. If not provided, the Generator omits the system prompt and uses the default system prompt. |
timeout | Optional[float] | None | Timeout for AzureOpenAI client. If not set, it is inferred from the OPENAI_TIMEOUT environment variable or set to 30. |
max_retries | Optional[int] | None | Maximum retries to establish contact with AzureOpenAI if it returns an internal error. If not set, it is inferred from the OPENAI_MAX_RETRIES environment variable or set to 5. |
generation_kwargs | Optional[Dict[str, Any]] | None | Other parameters to use for the model, sent directly to the OpenAI endpoint. For details, see OpenAI documentation. |
default_headers | Optional[Dict[str, str]] | None | Default headers to use for the AzureOpenAI client. |
Run Method Parameters
These are the parameters you can configure for the component's run() method. This means you can pass these parameters at query time through the API, in Playground, or when running a job. For details, see Modify Pipeline Parameters at Query Time.
| Parameter | Type | Default | Description |
|---|---|---|---|
prompt | str | The prompt with instructions for the model. | |
images | List[Base64Image] | A list of Base64Image's that represent the image content of the message. | |
generation_kwargs | Optional[Dict[str, Any]] | None | Additional keyword arguments for text generation. For more details, refer to the OpenAI documentation. |
Related Information
Was this page helpful?