Tutorial: Creating a Chat App With REST API
Create a chat app that can answer questions about Python Enhancement Proposals (PEPs) using REST API endpoints.
- Level: Basic
- Time to complete: 15 minutes
- Prerequisites:
- You must have a basic understanding of REST API: HTTP methods, response and request structure, and basic concepts.
- Basic programming knowledge is a plus.
- You must have a Haystack Platform API key. For instructions, see Generate an API Key.
- OpenAI API key to use GPT models. (This tutorial uses GPT-4, but you can exchange it for another model.)
- Goal: After completing this tutorial, you will have built a chat assistant that runs on Python Enhancements Proposals and can answer questions about the contents of the https://peps.python.org/ website. You'll be able to plug it into a UI of your choice.
Upload Files
First, let's upload the files our chat will run on.
- Download the peps_main.zip file to your machine and unzip it.
- Create a new workspace:
- Log in to Haystack Enterprise Platform and click the workspace name to expand the workspace list.
- Type
pepsas the new workspace name and click Create. You're automatically moved to the new workspace.
- In the navigation, click Files>Upload Files.
- Choose the files you extracted in step 1 and click Upload. You should have 664 files. Result: You have uploaded 664 files containing to your workspace.
Create an Index
Index prepares your files for search by chunking them and storing in a document store, where the query pipeline can access them.
- Go to Indexes > Create Index.
- Chose the Standard Index (English) template.
- Leave the default name and click Create Index. The index opens in Builder.
- Save the index and click Enable in the top right corner of the Builder.

Result: You created and enabled an index you can now connect to your query pipelines to give them access to your files.
Create a Chat Pipeline
Now, we'll create a chat pipeline you'll later call with REST API endpoints.
-
In Haystack Enterprise Platform, ensure you're in the same workspace where you uploaded the files, and click Pipeline Templates.
-
Choose Conversational templates, hover over RAG Chat, and click Use Template.
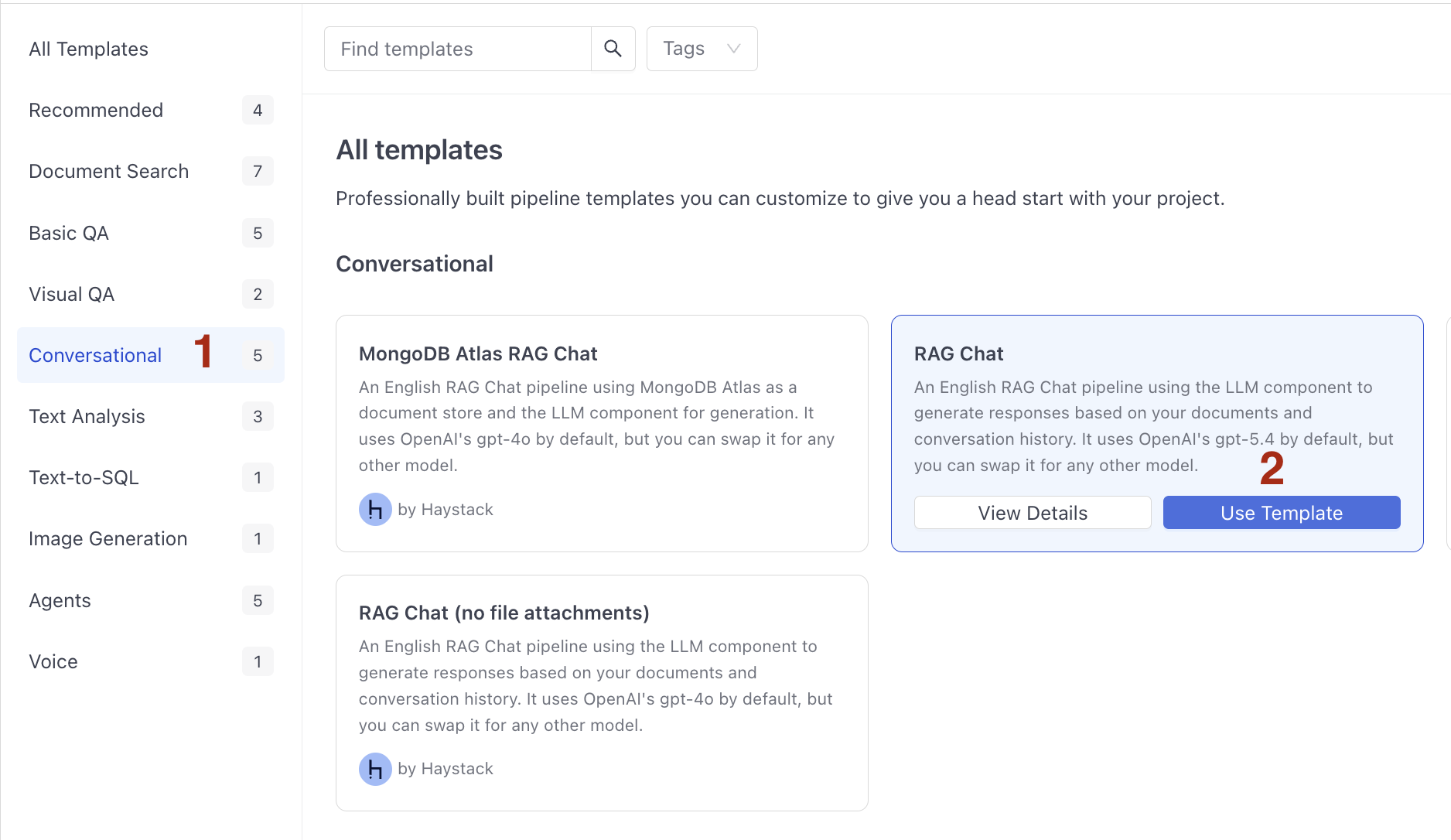
-
Rename the pipeline to
rag-chatand click Create Pipeline. The pipeline opens in Pipeline Builder. -
Find
OpenSearchDocumentStoreamong your pipeline components and click it to open the configuration. You'll notice it shows a warning that an index is missing. Choose theStandard-Index_Englishindex on the component card.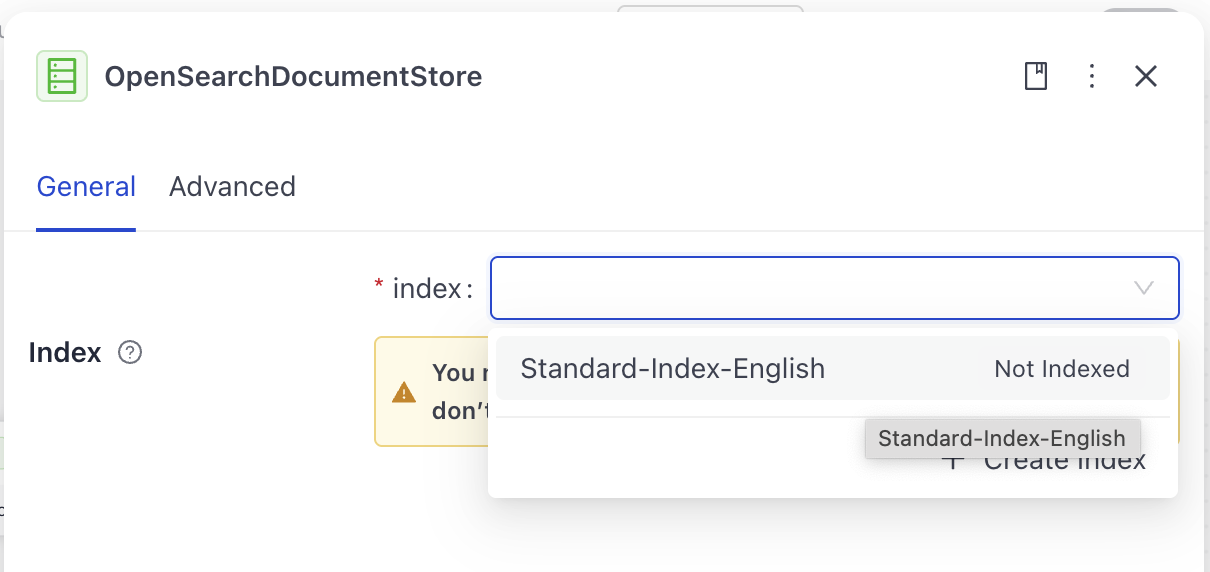
-
Save and deploy the pipeline.
Result: You have created and deployed a chat pipeline. It's ready for use.
Call the Pipeline with REST API
To send user queries to your chat pipelines:
- Get the ID of your chat pipeline. You can do this in the UI by clicking the pipeline name and checking the ID on the Pipeline Details page.
- Create a search session with the Create Search Session endpoint.
- Send user queries using the Chat endpoint.
Get Pipeline ID
- From the UI
- Using REST API Endpoint
Click Pipelines, find the pipeline whose ID you want to copy, and click its name. This opens the Pipeline Details page. The ID is shown right below the pipeline name.

Use the Get Pipeline endpoint. You can use the following code snippet (cURL or Python). Fill in:
- workspace name and pipeline name (in the URL).
- your Haystack Platform API key (in headers).
- Python
- cURL
import requests
url = "https://api.cloud.deepset.ai/api/v1/workspaces/<YOUR_WORKSPACE_NAME>/pipelines/<YOUR_PIPELINE_NAME>"
headers = {
"accept": "application/json",
"authorization": "Bearer <DEEPSET_API_KEY>"
}
response = requests.get(url, headers=headers)
print(response.text)
curl --request GET \
--url https://api.cloud.deepset.ai/api/v1/workspaces/<YOUR_WORKSPACE_NAME>/pipelines/<YOUR_PIPELINE_NAME> \
--header 'accept: application/json' \
--header 'authorization: Bearer <DEEPSET_API_KEY>'
Sample response
{
"name": "RAG-QA-Llama3.1-405b",
"pipeline_id": "07b04f1a-e053-4bd1-b3d5-e740b0dd6f2d", /* the pipeline ID*/
"status": "DEPLOYED",
"desired_status": "DEPLOYED",
"created_at": "2024-12-09T11:35:38.218604Z",
"deleted": false,
"is_default": false,
"created_by": {
"given_name": "Jane",
"family_name": "Smith",
"user_id": "f6398740-5555-445d-8ae3-ef980ea4191d"
},
"last_edited_by": {
"given_name": "Jane",
"family_name": "Smith",
"user_id": "f6398740-5555-445d-8ae3-ef980ea4191d"
},
"last_edited_at": "2024-12-09T11:35:44.219398Z",
"supports_prompt": true,
"output_type": "GENERATIVE",
"last_deployed_at": "2024-12-09T11:39:34.767557Z",
"service_level": "DEVELOPMENT",
"idle_timeout_in_seconds": 1200,
"deepset_cloud_version": "v2",
"indexing": {
"pending_file_count": 0,
"failed_file_count": 0
}
}
Create a Search Session
Search session lets you display chat history when running queries. Use the Create Search Session endpoint. You'll need to provide the following information:
- your workspace name (in the URL).
- your chat pipeline ID (you can find it in the Get Pipeline response).
- your Haystack Platform API key (in headers).
Here is a sample code you can use:
- Python
- cURL
import requests
url = "https://api.cloud.deepset.ai/api/v1/workspaces/peps/search_sessions" #legal-chat is the workspace name
payload = { "pipeline_id": "<pipeline_id>" } #insert the pipeline ID you got in the Get Pipeline response
headers = {
"accept": "application/json",
"content-type": "application/json",
"authorization": "Bearer <your_api_key>" #insert your deepset API key
}
response = requests.post(url, json=payload, headers=headers)
print(response.text)
curl --request POST \
--url https://api.cloud.deepset.ai/api/v1/workspaces/peps/search_sessions \
--header 'accept: application/json' \
--header 'authorization: Bearer <your_api_key>' \
--header 'content-type: application/json' \
--data '
{
"pipeline_id": "<pipeline_id>"
}
'
As a response, you get the search session ID, which you'll need to start the chat:
{
"search_session_id": "52bda5ec-23d9-4240-9d12-e7c48513158b"
}
Start a Chat
Send your queries to the Chat endpoint to start chatting with your pipeline. You'll need to provide:
- your pipeline and workspace name (in the URL).
- your Haystack Platform API key (in headers).
- queries
- search session ID (from the Create Search Session response)
You can use this code snippet:
- Python
- cURL
import requests
url = "https://api.cloud.deepset.ai/api/v1/workspaces/peps/pipelines/rag-chat/chat" #peps is the workspace name, rag-chat is the pipeline name
payload = {
"chat_history_limit": 3, # the number of chat history items to show in the chat
"debug": False,
"view_prompts": False,
"queries": ["How do you present datetime objects in human readable format?"], # the queries to ask
"search_session_id": "52bda5ec-23d9-4240-9d12-e7c48513158b" # ID of the search session
}
headers = {
"accept": "application/json",
"content-type": "application/json",
"authorization": "Bearer <your_api_key>" # your deepset API key
}
response = requests.post(url, json=payload, headers=headers)
print(response.text)
curl --request POST \
--url https://api.cloud.deepset.ai/api/v1/workspaces/peps/pipelines/rag-chat/chat \
--header 'accept: application/json' \
--header 'authorization: Bearer <your_api_key>' \
--header 'content-type: application/json' \
--data '
{
"chat_history_limit": 3,
"debug": false,
"view_prompts": false,
"queries": [
"How do you present datetime objects in human readable format?"
],
"search_session_id": "52bda5ec-23d9-4240-9d12-e7c48513158b"
}
'
Sample response
{
"query_id": "036b2866-2703-4d59-823d-9d8e683c7fa1",
"results": [
{
"query_id": "036b2866-2703-4d59-823d-9d8e683c7fa1",
"query": "How do you present datetime objects in human readable format?",
"answers": [
{
"answer": "To present datetime objects in a human-readable format, you can use the `strftime()` method provided by the `datetime` class. This method allows you to specify the format of the output string using format specifiers that correspond to various components of the date and time. For example, you can format a datetime object to display the date and time in a readable format like \"Today is: {0:%a %b %d %H:%M:%S %Y}\". This would output a string such as \"Today is: Mon Sep 16 10:34:54 2023\" . Additionally, the `isoformat()` and `ctime()` methods on datetime objects return string representations of the time in ISO 8601 format and a more traditional format similar to the C function `asctime()`, respectively .",
"type": "generative",
"score": null,
"context": null,
"offsets_in_document": [],
"offsets_in_context": [],
"document_id": null,
"document_ids": [
"7001548c9e254ad0d2a35c1fea7a93ebaca5edc7f7e58ccbdf9bb2c665960040",
"b4f79b5862793f5fa1c3f9b669a1c27e1a9aa9cff9b6481fa0de2513b3c3264d",
"edbc2088c4f9922d1e38554a6e1919508f3d739682abb07769ff14bcfd53c132",
"a83b9c8fdf043d00e92fe0247e5913ea5de8234b6c5a793efbafd410f01e418b",
"bdf4d62f2f52e9a3d1e87e6e41b9679ada4a930c321d33d3e77544c137cb88fb",
"d707bfed2ede5435c51068efc5690033457d7e3106572b2221ee30097e16c20e",
"66722fd08f8adab75357847e2d8ab324d6175816435c99063e2c2d8a96171d74",
"d9878e926481ac189a88db4f7ed36cb64cd9e28bd58c450ee11c2731dba935d6"
],
"meta": {
"_references": [
{
"answer_end_idx": 487,
"answer_start_idx": 487,
"document_id": "edbc2088c4f9922d1e38554a6e1919508f3d739682abb07769ff14bcfd53c132",
"document_position": 3,
"label": "grounded",
"score": 0,
"doc_end_idx": 1607,
"doc_start_idx": 0,
"origin": "llm"
},
{
"answer_end_idx": 706,
"answer_start_idx": 706,
"document_id": "7001548c9e254ad0d2a35c1fea7a93ebaca5edc7f7e58ccbdf9bb2c665960040",
"document_position": 1,
"label": "grounded",
"score": 0,
"doc_end_idx": 1738,
"doc_start_idx": 0,
"origin": "llm"
}
]
},
"file": {
"id": "3ee143f6-47b8-4ceb-bd69-0b0eede32aac",
"name": "pep-0321.txt"
},
"files": [
{
"id": "3ee143f6-47b8-4ceb-bd69-0b0eede32aac",
"name": "pep-0321.txt"
},
{
"id": "c549dad4-9306-417e-9e31-72eff4db300c",
"name": "pep-0498.txt"
},
{
"id": "d6987234-60e7-4651-864d-017631ca53b3",
"name": "pep-3101.txt"
},
{
"id": "25a9a573-222b-4fc4-b284-a776903ed1ea",
"name": "pep-0495.txt"
},
{
"id": "5eda3f1a-74b9-4887-9772-35ca44be1e99",
"name": "pep-0410.txt"
},
{
"id": "cf52312b-26b9-4ded-ac2b-cb6faf344a86",
"name": "pep-0500.txt"
},
{
"id": "a8a8d83e-6696-46c7-9ebf-3a953da41132",
"name": "pep-0519.txt"
}
],
"result_id": "7ec72d79-639a-4291-8258-86a173ec02ae",
"prompt": "You are a technical expert.\nYou answer questions truthfully based on provided documents.\nIf the answer exists in several documents, summarize them.\nIgnore documents that don't contain the answer to the question.\nOnly answer based on the documents provided. Don't make things up.\nIf no information related to the question can be found in the document, say so.\nAlways use references in the form [NUMBER OF DOCUMENT] when using information from a document, e.g. [3] for Document[3].\nNever name the documents, only enter a number in square brackets as a reference.\nThe reference must only refer to the number that comes in square brackets after the document.\nOtherwise, do not use brackets in your answer and reference ONLY the number of the document without mentioning the word document.\nThese are the documents:\n\nDocument[1]:\nPEP: 321\nTitle: Date/Time Parsing and Formatting\nVersion: $Revision$\nLast-Modified: $Date$\nAuthor: A.M. Kuchling <amk@amk.ca>\nStatus: Withdrawn\nType: Standards Track\nContent-Type: text/x-rst\nCreated: 16-Sep-2003\nPython-Version: 2.4\nPost-History:\n\n\nAbstract\n========\n\nPython 2.3 added a number of simple date and time types in the\n``datetime`` module. There's no support for parsing strings in various\nformats and returning a corresponding instance of one of the types.\nThis PEP proposes adding a family of predefined parsing function for\nseveral commonly used date and time formats, and a facility for generic\nparsing.\n\nThe types provided by the ``datetime`` module all have\n``.isoformat()`` and ``.ctime()`` methods that return string\nrepresentations of a time, and the ``.strftime()`` method can be used\nto construct new formats. There are a number of additional\ncommonly-used formats that would be useful to have as part of the\nstandard library; this PEP also suggests how to add them.\n\n\nInput Formats\n=======================\n\nUseful formats to support include:\n\n* `ISO8601`_\n* ARPA/:rfc:`2822`\n* `ctime`_\n* Formats commonly written by humans such as the American\n \"MM/DD/YYYY\", the European \"YYYY/MM/DD\", and variants such as\n \"DD-Month-YYYY\".\n* CVS-style or tar-style dates (\"tomorrow\", \"12 hours ago\", etc.)\n\nXXX The Perl `ParseDate.pm`_ module supports many different input formats,\nboth absolute and relative. Should we try to support them all?\n\nOptions:\n\n1) Add functions to the ``datetime`` module::\n\n import datetime\n d = datetime.parse_iso8601(\"2003-09-15T10:34:54\")\n\n2) Add class methods to the various types. There are already various\n class methods such as ``.now()``, so this would be pretty natural.\n\nDocument[2]:\nHowever, ``str.format()`` is not without its issues. Chief among them\nis its verbosity. For example, the text ``value`` is repeated here::\n\n >>> value = 4 * 20\n >>> 'The value is {value}.'.format(value=value)\n 'The value is 80.'Even in its simplest form there is a bit of boilerplate, and the value\nthat's inserted into the placeholder is sometimes far removed from\nwhere the placeholder is situated::\n\n >>> 'The value is {}.'.format(value)\n 'The value is 80.'With an f-string, this becomes::\n\n >>> f'The value is {value}.''The value is 80.'F-strings provide a concise, readable way to include the value of\nPython expressions inside strings.\n\nIn this sense, ``string.Template`` and %-formatting have similar\nshortcomings to ``str.format()``, but also support fewer formatting\noptions. In particular, they do not support the ``__format__``\nprotocol, so that there is no way to control how a specific object is\nconverted to a string, nor can it be extended to additional types that\nwant to control how they are converted to strings (such as ``Decimal``\nand ``datetime``). This example is not possible with\n``string.Template``::\n\n >>> value = 1234\n >>> f'input={value:#06x}'\n 'input=0x04d2'\n\nAnd neither %-formatting nor ``string.Template`` can control\nformatting such as::\n\n >>> date = datetime.date(1991, 10, 12)\n >>> f'{date} was on a {date:%A}'\n '1991-10-12 was on a Saturday'\n\nNo use of globals() or locals()\n-------------------------------\n\nIn the discussions on python-dev [#]_, a number of solutions where\npresented that used locals() and globals() or their equivalents. All\nof these have various problems. \n\nDocument[3]:\nSame as 'g' except switches to 'E'\n if the number gets to large.\n 'n' - Number. This is the same as 'g', except that it uses the\n current locale setting to insert the appropriate\n number separator characters.\n '%' - Percentage. Multiplies the number by 100 and displays\n in fixed ('f') format, followed by a percent sign.\n '' (None) - similar to 'g', except that it prints at least one\n digit after the decimal point.\n\nObjects are able to define their own format specifiers to\nreplace the standard ones. An example is the 'datetime' class,\nwhose format specifiers might look something like the\narguments to the ``strftime()`` function::\n\n \"Today is: {0:%a %b %d %H:%M:%S %Y}\".format(datetime.now())\n\nFor all built-in types, an empty format specification will produce\nthe equivalent of ``str(value)``. It is recommended that objects\ndefining their own format specifiers follow this convention as\nwell.\n\n\nExplicit Conversion Flag\n------------------------\n\nThe explicit conversion flag is used to transform the format field value\nbefore it is formatted. This can be used to override the type-specific\nformatting behavior, and format the value as if it were a more\ngeneric type. Currently, two explicit conversion flags are\nrecognized::\n\n !r - convert the value to a string using repr().\n !s - convert the value to a string using str().\n\nThese flags are placed before the format specifier::\n\n \"{0!r:20}\".format(\"Hello\")\n\nIn the preceding example, the string \"Hello\" will be printed, with quotes,\nin a field of at least 20 characters width.\n\n\n\nDocument[4]:\nOnly complicated formats need to be supported; :rfc:`2822`\nis currently the only one I can think of.\n\nOptions:\n\n1) Provide predefined format strings, so you could write this::\n\n import datetime\n d = datetime.datetime(...)\n print d.strftime(d.RFC2822_FORMAT) # or datetime.RFC2822_FORMAT?\n\n2) Provide new methods on all the objects::\n\n d = datetime.datetime(...)\n print d.rfc822_time()\n\n\nRelevant functionality in other languages includes the `PHP date`_\nfunction (Python implementation by Simon Willison at\nhttp://simon.incutio.com/archive/2003/10/07/dateInPython)\n\n\nReferences\n==========\n\n.. _ISO8601: http://www.cl.cam.ac.uk/~mgk25/iso-time.html\n\n.. _ParseDate.pm: http://search.cpan.org/author/MUIR/Time-modules-2003.0211/lib/Time/ParseDate.pm\n\n.. _ctime: http://www.opengroup.org/onlinepubs/007908799/xsh/asctime.html\n\n.. _PHP date: http://www.php.net/date\n\nOther useful links:\n\nhttp://www.egenix.com/files/python/mxDateTime.html\nhttp://ringmaster.arc.nasa.gov/tools/time_formats.html\nhttp://www.thinkage.ca/english/gcos/expl/b/lib/0tosec.html\nhttps://moin.conectiva.com.br/DateUtil\n\n\nCopyright\n=========\n\nThis document has been placed in the public domain.\n\n\n\f\n..\n Local Variables:\n mode: indented-text\n indent-tabs-mode: nil\n sentence-end-double-space: t\n fill-column: 70\n End:\n\nDocument[5]:\nOnly datetime/time instances with ``fold=1`` pickled\nin the new versions will become unreadable by the older Python\nversions. Pickles of instances with ``fold=0`` (which is the\ndefault) will remain unchanged.\n\n\nQuestions and Answers\n=====================\n\nWhy not call the new flag \"isdst\"?\n----------------------------------\n\nA non-technical answer\n......................\n\n* Alice: Bob - let's have a stargazing party at 01:30 AM tomorrow!\n* Bob: Should I presume initially that Daylight Saving Time is or is\n not in effect for the specified time?\n* Alice: Huh?\n\n-------\n\n* Bob: Alice - let's have a stargazing party at 01:30 AM tomorrow!\n* Alice: You know, Bob, 01:30 AM will happen twice tomorrow. Which time do you have in mind?\n* Bob: I did not think about it, but let's pick the first.\n\n-------\n\n(same characters, an hour later)\n\n-------\n\n* Bob: Alice - this Py-O-Clock gadget of mine asks me to choose\n between fold=0 and fold=1 when I set it for tomorrow 01:30 AM.\n What should I do?\n* Alice: I've never hear of a Py-O-Clock, but I guess fold=0 is\n the first 01:30 AM and fold=1 is the second.\n\n\nA technical reason\n..................\n\nWhile the ``tm_isdst`` field of the ``time.struct_time`` object can be\nused to disambiguate local times in the fold, the semantics of such\ndisambiguation are completely different from the proposal in this PEP.\n\n\n\nDocument[6]:\nThere is also an ordering issues with daylight saving time (DST) in\nthe duplicate hour of switching from DST to normal time.\n\ndatetime.datetime has been rejected because it cannot be used for functions\nusing an unspecified starting point like os.times() or time.clock().\n\nFor time.time() and time.clock_gettime(time.CLOCK_GETTIME): it is already\npossible to get the current time as a datetime.datetime object using::\n\n datetime.datetime.now(datetime.timezone.utc)\n\nFor os.stat(), it is simple to create a datetime.datetime object from a\ndecimal.Decimal timestamp in the UTC timezone::\n\n datetime.datetime.fromtimestamp(value, datetime.timezone.utc)\n\n.. note::\n datetime.datetime only supports microsecond resolution, but can be enhanced\n to support nanosecond.\n\ndatetime.timedelta\n------------------\n\ndatetime.timedelta is the natural choice for a relative timestamp because it is\nclear that this type contains a timestamp, whereas int, float and Decimal are\nraw numbers. It can be used with datetime.datetime to get an absolute timestamp\nwhen the starting point is known.\n\ndatetime.timedelta has been rejected because it cannot be coerced to float and\nhas a fixed resolution. One new standard timestamp type is enough, Decimal is\npreferred over datetime.timedelta. Converting a datetime.timedelta to float\nrequires an explicit call to the datetime.timedelta.total_seconds() method.\n\n.. note::\n datetime.timedelta only supports microsecond resolution, but can be enhanced\n to support nanosecond.\n\n\n.. _tuple:\n\nTuple of integers\n-----------------\n\nTo expose C functions in Python, a tuple of integers is the natural choice to\nstore a timestamp because the C language uses structures with integers fields\n(e.g. timeval and timespec structures). Using only integers avoids the loss of\nprecision (Python supports integers of arbitrary length). \n\nDocument[7]:\nPEP: 500\nTitle: A protocol for delegating datetime methods to their tzinfo implementations\nVersion: $Revision$\nLast-Modified: $Date$\nAuthor: Alexander Belopolsky <alexander.belopolsky@gmail.com>, Tim Peters <tim.peters@gmail.com>\nDiscussions-To: datetime-sig@python.org\nStatus: Rejected\nType: Standards Track\nContent-Type: text/x-rst\nRequires: 495\nCreated: 08-Aug-2015\nResolution: https://mail.python.org/pipermail/datetime-sig/2015-August/000354.html\n\nAbstract\n========\n\nThis PEP specifies a new protocol (PDDM - \"A Protocol for Delegating\nDatetime Methods\") that can be used by concrete implementations of the\n``datetime.tzinfo`` interface to override aware datetime arithmetics,\nformatting and parsing. We describe changes to the\n``datetime.datetime`` class to support the new protocol and propose a\nnew abstract class ``datetime.tzstrict`` that implements parts of this\nprotocol necessary to make aware datetime instances to follow \"strict\"\narithmetic rules.\n\n\nRationale\n=========\n\nAs of Python 3.5, aware datetime instances that share a ``tzinfo``\nobject follow the rules of arithmetics that are induced by a simple\nbijection between (year, month, day, hour, minute, second,\nmicrosecond) 7-tuples and large integers. In this arithmetics, the\ndifference between YEAR-11-02T12:00 and YEAR-11-01T12:00 is always 24\nhours, even though in the US/Eastern timezone, for example, there are\n25 hours between 2014-11-01T12:00 and 2014-11-02T12:00 because the\nlocal clocks were rolled back one hour at 2014-11-02T02:00,\nintroducing an extra hour in the night between 2014-11-01 and\n2014-11-02.\n\nMany business applications require the use of Python's simplified view\nof local dates. No self-respecting car rental company will charge its\ncustomers more for a week that straddles the end of DST than for any\nother week or require that they return the car an hour early.\n\n\nDocument[8]:\nOne part is the proposal of a\nprotocol for objects to declare and provide support for exposing a\nfile system path representation. The other part deals with changes to\nPython's standard library to support the new protocol. These changes\nwill also lead to the pathlib module dropping its provisional status.\n\nProtocol\n--------\n\nThe following abstract base class defines the protocol for an object\nto be considered a path object::\n\n import abc\n import typing as t\n\n\n class PathLike(abc.ABC):\n\n \"\"\"Abstract base class for implementing the file system path protocol.\"\"\"@abc.abstractmethod\n def __fspath__(self) -> t.Union[str, bytes]:\n \"\"\"Return the file system path representation of the object.\"\"\"raise NotImplementedError\n\n\nObjects representing file system paths will implement the\n``__fspath__()`` method which will return the ``str`` or ``bytes``\nrepresentation of the path. The ``str`` representation is the\npreferred low-level path representation as it is human-readable and\nwhat people historically represent paths as.\n\n\nStandard library changes\n------------------------\n\nIt is expected that most APIs in Python's standard library that\ncurrently accept a file system path will be updated appropriately to\naccept path objects (whether that requires code or simply an update\nto documentation will vary). The modules mentioned below, though,\ndeserve specific details as they have either fundamental changes that\nempower the ability to use path objects, or entail additions/removal\nof APIs.\n\n\nbuiltins\n''''''''\n\n``open()`` [#builtins-open]_ will be updated to accept path objects as\nwell as continue to accept ``str`` and ``bytes``.\n\n\n\n\nQuestion: How do you present datetime objects in human readable format?\nAnswer:"
}
],
"documents": [
{
"id": "7001548c9e254ad0d2a35c1fea7a93ebaca5edc7f7e58ccbdf9bb2c665960040",
"content": "PEP: 321\nTitle: Date/Time Parsing and Formatting\nVersion: $Revision$\nLast-Modified: $Date$\nAuthor: A.M. Kuchling <amk@amk.ca>\nStatus: Withdrawn\nType: Standards Track\nContent-Type: text/x-rst\nCreated: 16-Sep-2003\nPython-Version: 2.4\nPost-History:\n\n\nAbstract\n========\n\nPython 2.3 added a number of simple date and time types in the\n``datetime`` module. There's no support for parsing strings in various\nformats and returning a corresponding instance of one of the types.\nThis PEP proposes adding a family of predefined parsing function for\nseveral commonly used date and time formats, and a facility for generic\nparsing.\n\nThe types provided by the ``datetime`` module all have\n``.isoformat()`` and ``.ctime()`` methods that return string\nrepresentations of a time, and the ``.strftime()`` method can be used\nto construct new formats. There are a number of additional\ncommonly-used formats that would be useful to have as part of the\nstandard library; this PEP also suggests how to add them.\n\n\nInput Formats\n=======================\n\nUseful formats to support include:\n\n* `ISO8601`_\n* ARPA/:rfc:`2822`\n* `ctime`_\n* Formats commonly written by humans such as the American\n \"MM/DD/YYYY\", the European \"YYYY/MM/DD\", and variants such as\n \"DD-Month-YYYY\".\n* CVS-style or tar-style dates (\"tomorrow\", \"12 hours ago\", etc.)\n\nXXX The Perl `ParseDate.pm`_ module supports many different input formats,\nboth absolute and relative. Should we try to support them all?\n\nOptions:\n\n1) Add functions to the ``datetime`` module::\n\n import datetime\n d = datetime.parse_iso8601(\"2003-09-15T10:34:54\")\n\n2) Add class methods to the various types. There are already various\n class methods such as ``.now()``, so this would be pretty natural.",
"content_type": "text",
"meta": {
"_split_overlap": [
{
"range": [
0,
279
],
"doc_id": "850d4b3a9055c249407bc6c2577ffd340ffb1e297f532513274d584b899f42c0"
}
],
"split_idx_start": 0,
"file_name": "pep-0321.txt",
"_file_created_at": "2024-10-18T09:04:08.908838+00:00",
"split_id": 0,
"_file_size": 4372,
"page_number": 1,
"source_id": "0f5123e030c45b644e8c5db6c65c4beadbf11c82bf30e48a99f7b9ed02c696e9"
},
"score": 0.09124755859375,
"embedding": null,
"file": {
"id": "3ee143f6-47b8-4ceb-bd69-0b0eede32aac",
"name": "pep-0321.txt"
},
"result_id": "f93ab9cc-76ec-4120-9cfe-e6ac374b6684"
},
{
"id": "b4f79b5862793f5fa1c3f9b669a1c27e1a9aa9cff9b6481fa0de2513b3c3264d",
"content": "However, ``str.format()`` is not without its issues. Chief among them\nis its verbosity. For example, the text ``value`` is repeated here::\n\n >>> value = 4 * 20\n >>> 'The value is {value}.'.format(value=value)\n 'The value is 80.'Even in its simplest form there is a bit of boilerplate, and the value\nthat's inserted into the placeholder is sometimes far removed from\nwhere the placeholder is situated::\n\n >>> 'The value is {}.'.format(value)\n 'The value is 80.'With an f-string, this becomes::\n\n >>> f'The value is {value}.''The value is 80.'F-strings provide a concise, readable way to include the value of\nPython expressions inside strings.\n\nIn this sense, ``string.Template`` and %-formatting have similar\nshortcomings to ``str.format()``, but also support fewer formatting\noptions. In particular, they do not support the ``__format__``\nprotocol, so that there is no way to control how a specific object is\nconverted to a string, nor can it be extended to additional types that\nwant to control how they are converted to strings (such as ``Decimal``\nand ``datetime``). This example is not possible with\n``string.Template``::\n\n >>> value = 1234\n >>> f'input={value:#06x}'\n 'input=0x04d2'\n\nAnd neither %-formatting nor ``string.Template`` can control\nformatting such as::\n\n >>> date = datetime.date(1991, 10, 12)\n >>> f'{date} was on a {date:%A}'\n '1991-10-12 was on a Saturday'\n\nNo use of globals() or locals()\n-------------------------------\n\nIn the discussions on python-dev [#]_, a number of solutions where\npresented that used locals() and globals() or their equivalents. All\nof these have various problems. ",
"content_type": "text",
"meta": {
"_split_overlap": [
{
"range": [
1194,
1425
],
"doc_id": "d873a90f56222b0c02ef2987a6ef2390aa5f7400bb6f8fe5c1cfafebaba3a9d4"
},
{
"range": [
0,
548
],
"doc_id": "76db0307a81ca4d9012184b0066414935f4342f14219f177170a61737d6bfd2c"
}
],
"split_idx_start": 3396,
"file_name": "pep-0498.txt",
"_file_created_at": "2024-10-18T09:03:54.839485+00:00",
"split_id": 3,
"_file_size": 25320,
"page_number": 1,
"source_id": "51927b0152d7c0504de7a4e0a4f5265617143fce6a5f763d17118f6afdc92298"
},
"score": 0.06280517578125,
"embedding": null,
"file": {
"id": "c549dad4-9306-417e-9e31-72eff4db300c",
"name": "pep-0498.txt"
},
"result_id": "0c46d7af-4542-4b1e-ac23-95d5d2bdbc7c"
},
{
"id": "edbc2088c4f9922d1e38554a6e1919508f3d739682abb07769ff14bcfd53c132",
"content": "Same as 'g' except switches to 'E'\n if the number gets to large.\n 'n' - Number. This is the same as 'g', except that it uses the\n current locale setting to insert the appropriate\n number separator characters.\n '%' - Percentage. Multiplies the number by 100 and displays\n in fixed ('f') format, followed by a percent sign.\n '' (None) - similar to 'g', except that it prints at least one\n digit after the decimal point.\n\nObjects are able to define their own format specifiers to\nreplace the standard ones. An example is the 'datetime' class,\nwhose format specifiers might look something like the\narguments to the ``strftime()`` function::\n\n \"Today is: {0:%a %b %d %H:%M:%S %Y}\".format(datetime.now())\n\nFor all built-in types, an empty format specification will produce\nthe equivalent of ``str(value)``. It is recommended that objects\ndefining their own format specifiers follow this convention as\nwell.\n\n\nExplicit Conversion Flag\n------------------------\n\nThe explicit conversion flag is used to transform the format field value\nbefore it is formatted. This can be used to override the type-specific\nformatting behavior, and format the value as if it were a more\ngeneric type. Currently, two explicit conversion flags are\nrecognized::\n\n !r - convert the value to a string using repr().\n !s - convert the value to a string using str().\n\nThese flags are placed before the format specifier::\n\n \"{0!r:20}\".format(\"Hello\")\n\nIn the preceding example, the string \"Hello\" will be printed, with quotes,\nin a field of at least 20 characters width.\n\n",
"content_type": "text",
"meta": {
"_split_overlap": [
{
"range": [
1386,
1647
],
"doc_id": "0080ddf63825baab764048b3e068878bd23701f44610365cd5808be57d4fe36d"
},
{
"range": [
0,
255
],
"doc_id": "2629b8672811bd4a8a6da1adaa55dc166d2fc0e3ba1b8336690e7599c77cc5f2"
}
],
"split_idx_start": 12752,
"file_name": "pep-3101.txt",
"_file_created_at": "2024-10-18T09:03:29.826858+00:00",
"split_id": 11,
"_file_size": 33149,
"page_number": 1,
"source_id": "b42e3a8de46bd3686eb4e0ec3015b34e916f424f29e9398acb58d062e89c15bf"
},
"score": 0.05792236328125,
"embedding": null,
"file": {
"id": "d6987234-60e7-4651-864d-017631ca53b3",
"name": "pep-3101.txt"
},
"result_id": "e497e02b-3aa9-498c-b687-fc850ed4398f"
},
{
"id": "a83b9c8fdf043d00e92fe0247e5913ea5de8234b6c5a793efbafd410f01e418b",
"content": "Only complicated formats need to be supported; :rfc:`2822`\nis currently the only one I can think of.\n\nOptions:\n\n1) Provide predefined format strings, so you could write this::\n\n import datetime\n d = datetime.datetime(...)\n print d.strftime(d.RFC2822_FORMAT) # or datetime.RFC2822_FORMAT?\n\n2) Provide new methods on all the objects::\n\n d = datetime.datetime(...)\n print d.rfc822_time()\n\n\nRelevant functionality in other languages includes the `PHP date`_\nfunction (Python implementation by Simon Willison at\nhttp://simon.incutio.com/archive/2003/10/07/dateInPython)\n\n\nReferences\n==========\n\n.. _ISO8601: http://www.cl.cam.ac.uk/~mgk25/iso-time.html\n\n.. _ParseDate.pm: http://search.cpan.org/author/MUIR/Time-modules-2003.0211/lib/Time/ParseDate.pm\n\n.. _ctime: http://www.opengroup.org/onlinepubs/007908799/xsh/asctime.html\n\n.. _PHP date: http://www.php.net/date\n\nOther useful links:\n\nhttp://www.egenix.com/files/python/mxDateTime.html\nhttp://ringmaster.arc.nasa.gov/tools/time_formats.html\nhttp://www.thinkage.ca/english/gcos/expl/b/lib/0tosec.html\nhttps://moin.conectiva.com.br/DateUtil\n\n\nCopyright\n=========\n\nThis document has been placed in the public domain.\n\n\n\f\n..\n Local Variables:\n mode: indented-text\n indent-tabs-mode: nil\n sentence-end-double-space: t\n fill-column: 70\n End:",
"content_type": "text",
"meta": {
"_split_overlap": [
{
"range": [
1582,
1892
],
"doc_id": "850d4b3a9055c249407bc6c2577ffd340ffb1e297f532513274d584b899f42c0"
}
],
"split_idx_start": 3041,
"file_name": "pep-0321.txt",
"_file_created_at": "2024-10-18T09:04:08.908838+00:00",
"split_id": 2,
"_file_size": 4372,
"page_number": 1,
"source_id": "0f5123e030c45b644e8c5db6c65c4beadbf11c82bf30e48a99f7b9ed02c696e9"
},
"score": 0.02606201171875,
"embedding": null,
"file": {
"id": "3ee143f6-47b8-4ceb-bd69-0b0eede32aac",
"name": "pep-0321.txt"
},
"result_id": "0956c775-a701-40e9-b914-5fdf82c42f19"
},
{
"id": "bdf4d62f2f52e9a3d1e87e6e41b9679ada4a930c321d33d3e77544c137cb88fb",
"content": "Only datetime/time instances with ``fold=1`` pickled\nin the new versions will become unreadable by the older Python\nversions. Pickles of instances with ``fold=0`` (which is the\ndefault) will remain unchanged.\n\n\nQuestions and Answers\n=====================\n\nWhy not call the new flag \"isdst\"?\n----------------------------------\n\nA non-technical answer\n......................\n\n* Alice: Bob - let's have a stargazing party at 01:30 AM tomorrow!\n* Bob: Should I presume initially that Daylight Saving Time is or is\n not in effect for the specified time?\n* Alice: Huh?\n\n-------\n\n* Bob: Alice - let's have a stargazing party at 01:30 AM tomorrow!\n* Alice: You know, Bob, 01:30 AM will happen twice tomorrow. Which time do you have in mind?\n* Bob: I did not think about it, but let's pick the first.\n\n-------\n\n(same characters, an hour later)\n\n-------\n\n* Bob: Alice - this Py-O-Clock gadget of mine asks me to choose\n between fold=0 and fold=1 when I set it for tomorrow 01:30 AM.\n What should I do?\n* Alice: I've never hear of a Py-O-Clock, but I guess fold=0 is\n the first 01:30 AM and fold=1 is the second.\n\n\nA technical reason\n..................\n\nWhile the ``tm_isdst`` field of the ``time.struct_time`` object can be\nused to disambiguate local times in the fold, the semantics of such\ndisambiguation are completely different from the proposal in this PEP.\n\n",
"content_type": "text",
"meta": {
"_split_overlap": [
{
"range": [
1389,
1681
],
"doc_id": "a1270e82b4dbf104c429342bb71fb0a7fc80db41719f0d2a79ffa88215e9ced6"
},
{
"range": [
0,
211
],
"doc_id": "ea7d03dac129035cacbb28d07304048f31e99487736aecb2df16b8903874ccca"
}
],
"split_idx_start": 23551,
"file_name": "pep-0495.txt",
"_file_created_at": "2024-10-18T09:03:54.819307+00:00",
"split_id": 18,
"_file_size": 34899,
"page_number": 1,
"source_id": "04ae5810b522e53d51d5bb1f7e708f045a1e09977cde5b7e18a54646ffa0575f"
},
"score": 0.020294189453125,
"embedding": null,
"file": {
"id": "25a9a573-222b-4fc4-b284-a776903ed1ea",
"name": "pep-0495.txt"
},
"result_id": "77aed3e6-8840-4edf-a532-e9b66375b1e2"
},
{
"id": "d707bfed2ede5435c51068efc5690033457d7e3106572b2221ee30097e16c20e",
"content": "There is also an ordering issues with daylight saving time (DST) in\nthe duplicate hour of switching from DST to normal time.\n\ndatetime.datetime has been rejected because it cannot be used for functions\nusing an unspecified starting point like os.times() or time.clock().\n\nFor time.time() and time.clock_gettime(time.CLOCK_GETTIME): it is already\npossible to get the current time as a datetime.datetime object using::\n\n datetime.datetime.now(datetime.timezone.utc)\n\nFor os.stat(), it is simple to create a datetime.datetime object from a\ndecimal.Decimal timestamp in the UTC timezone::\n\n datetime.datetime.fromtimestamp(value, datetime.timezone.utc)\n\n.. note::\n datetime.datetime only supports microsecond resolution, but can be enhanced\n to support nanosecond.\n\ndatetime.timedelta\n------------------\n\ndatetime.timedelta is the natural choice for a relative timestamp because it is\nclear that this type contains a timestamp, whereas int, float and Decimal are\nraw numbers. It can be used with datetime.datetime to get an absolute timestamp\nwhen the starting point is known.\n\ndatetime.timedelta has been rejected because it cannot be coerced to float and\nhas a fixed resolution. One new standard timestamp type is enough, Decimal is\npreferred over datetime.timedelta. Converting a datetime.timedelta to float\nrequires an explicit call to the datetime.timedelta.total_seconds() method.\n\n.. note::\n datetime.timedelta only supports microsecond resolution, but can be enhanced\n to support nanosecond.\n\n\n.. _tuple:\n\nTuple of integers\n-----------------\n\nTo expose C functions in Python, a tuple of integers is the natural choice to\nstore a timestamp because the C language uses structures with integers fields\n(e.g. timeval and timespec structures). Using only integers avoids the loss of\nprecision (Python supports integers of arbitrary length). ",
"content_type": "text",
"meta": {
"_split_overlap": [
{
"range": [
1272,
1544
],
"doc_id": "2f29a4a6323783368c1160597feb0d31e710bffb8f3df64f28bc205d88de1698"
},
{
"range": [
0,
342
],
"doc_id": "c7a17a8edafad008f36b5244fcd85b81d3cb50261f11ba6159fe1297112fb956"
}
],
"split_idx_start": 8032,
"file_name": "pep-0410.txt",
"_file_created_at": "2024-10-18T09:04:01.074298+00:00",
"split_id": 6,
"_file_size": 20703,
"page_number": 1,
"source_id": "0a5ffe8e2eae3b854132370ba3ee43c31cba6d88fb72c635690acb723fcadeae"
},
"score": 0.019683837890625,
"embedding": null,
"file": {
"id": "5eda3f1a-74b9-4887-9772-35ca44be1e99",
"name": "pep-0410.txt"
},
"result_id": "fd0e6f52-d944-4642-bc66-61b852960cc8"
},
{
"id": "66722fd08f8adab75357847e2d8ab324d6175816435c99063e2c2d8a96171d74",
"content": "PEP: 500\nTitle: A protocol for delegating datetime methods to their tzinfo implementations\nVersion: $Revision$\nLast-Modified: $Date$\nAuthor: Alexander Belopolsky <alexander.belopolsky@gmail.com>, Tim Peters <tim.peters@gmail.com>\nDiscussions-To: datetime-sig@python.org\nStatus: Rejected\nType: Standards Track\nContent-Type: text/x-rst\nRequires: 495\nCreated: 08-Aug-2015\nResolution: https://mail.python.org/pipermail/datetime-sig/2015-August/000354.html\n\nAbstract\n========\n\nThis PEP specifies a new protocol (PDDM - \"A Protocol for Delegating\nDatetime Methods\") that can be used by concrete implementations of the\n``datetime.tzinfo`` interface to override aware datetime arithmetics,\nformatting and parsing. We describe changes to the\n``datetime.datetime`` class to support the new protocol and propose a\nnew abstract class ``datetime.tzstrict`` that implements parts of this\nprotocol necessary to make aware datetime instances to follow \"strict\"\narithmetic rules.\n\n\nRationale\n=========\n\nAs of Python 3.5, aware datetime instances that share a ``tzinfo``\nobject follow the rules of arithmetics that are induced by a simple\nbijection between (year, month, day, hour, minute, second,\nmicrosecond) 7-tuples and large integers. In this arithmetics, the\ndifference between YEAR-11-02T12:00 and YEAR-11-01T12:00 is always 24\nhours, even though in the US/Eastern timezone, for example, there are\n25 hours between 2014-11-01T12:00 and 2014-11-02T12:00 because the\nlocal clocks were rolled back one hour at 2014-11-02T02:00,\nintroducing an extra hour in the night between 2014-11-01 and\n2014-11-02.\n\nMany business applications require the use of Python's simplified view\nof local dates. No self-respecting car rental company will charge its\ncustomers more for a week that straddles the end of DST than for any\nother week or require that they return the car an hour early.\n",
"content_type": "text",
"meta": {
"_split_overlap": [
{
"range": [
0,
185
],
"doc_id": "2491a8b58f7bb1979fdf5061006dfc72c54b6e9e287f06f9b8a5dd669967c874"
}
],
"split_idx_start": 0,
"file_name": "pep-0500.txt",
"_file_created_at": "2024-10-18T09:03:51.944443+00:00",
"split_id": 0,
"_file_size": 7045,
"page_number": 1,
"source_id": "5180621105b359308fb5b39c5455b227c26cb8533a69672335202ed14e8d568d"
},
"score": 0.018798828125,
"embedding": null,
"file": {
"id": "cf52312b-26b9-4ded-ac2b-cb6faf344a86",
"name": "pep-0500.txt"
},
"result_id": "623d6f02-476c-4110-83e9-92186bc055b9"
},
{
"id": "d9878e926481ac189a88db4f7ed36cb64cd9e28bd58c450ee11c2731dba935d6",
"content": "One part is the proposal of a\nprotocol for objects to declare and provide support for exposing a\nfile system path representation. The other part deals with changes to\nPython's standard library to support the new protocol. These changes\nwill also lead to the pathlib module dropping its provisional status.\n\nProtocol\n--------\n\nThe following abstract base class defines the protocol for an object\nto be considered a path object::\n\n import abc\n import typing as t\n\n\n class PathLike(abc.ABC):\n\n \"\"\"Abstract base class for implementing the file system path protocol.\"\"\"@abc.abstractmethod\n def __fspath__(self) -> t.Union[str, bytes]:\n \"\"\"Return the file system path representation of the object.\"\"\"raise NotImplementedError\n\n\nObjects representing file system paths will implement the\n``__fspath__()`` method which will return the ``str`` or ``bytes``\nrepresentation of the path. The ``str`` representation is the\npreferred low-level path representation as it is human-readable and\nwhat people historically represent paths as.\n\n\nStandard library changes\n------------------------\n\nIt is expected that most APIs in Python's standard library that\ncurrently accept a file system path will be updated appropriately to\naccept path objects (whether that requires code or simply an update\nto documentation will vary). The modules mentioned below, though,\ndeserve specific details as they have either fundamental changes that\nempower the ability to use path objects, or entail additions/removal\nof APIs.\n\n\nbuiltins\n''''''''\n\n``open()`` [#builtins-open]_ will be updated to accept path objects as\nwell as continue to accept ``str`` and ``bytes``.\n\n\n",
"content_type": "text",
"meta": {
"_split_overlap": [
{
"range": [
1308,
1615
],
"doc_id": "73e62bf9eacb2631fd3da8a9f98313919f5e6851cbc7fcd72f71b8e2ffb578d9"
},
{
"range": [
0,
329
],
"doc_id": "e3149c5c7a835f78b529358fafabe007d0d109d48517de4314d5f6ad45534d7a"
}
],
"split_idx_start": 3824,
"file_name": "pep-0519.txt",
"_file_created_at": "2024-10-18T09:03:49.692777+00:00",
"split_id": 3,
"_file_size": 22105,
"page_number": 1,
"source_id": "cf21ac8366c79d9b83f9fc8a0efd4982b0d4d4e0ae7c2716a5eea2fca6bf00a9"
},
"score": 0.0169219970703125,
"embedding": null,
"file": {
"id": "a8a8d83e-6696-46c7-9ebf-3a953da41132",
"name": "pep-0519.txt"
},
"result_id": "85c4399f-38d4-439d-94b6-ffcfa7c52e67"
}
],
"_debug": null,
"prompts": null
}
]
}
Chain the Requests
Here is a sample code that:
- Calls the
Get Pipelineendpoint. - Extracts the pipeline ID from the response and calls the
Create Search Sessionendpoint to create a search session. - Uses the session ID from the response to start the chat using the
Chatendpoint.
- Python
- cURL
import requests
import json
# Replace your API key and base URL
API_KEY = "<api_key>"
BASE_URL = "https://api.cloud.deepset.ai/api/v1"
WORKSPACE = "legal-chat"
PIPELINE = "rag-chat"
headers = {
"accept": "application/json",
"authorization": f"Bearer {API_KEY}",
"content-type": "application/json"
}
def get_pipeline_id():
url = f"{BASE_URL}/workspaces/{WORKSPACE}/pipelines/{PIPELINE}"
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.json()["pipeline_id"]
else:
raise Exception(f"Failed to get pipeline ID: {response.status_code}")
def create_search_session(pipeline_id):
url = f"{BASE_URL}/workspaces/{WORKSPACE}/search_sessions"
data = {
"pipeline_id": pipeline_id
}
response = requests.post(url, headers=headers, json=data)
if response.status_code == 200:
return response.json()["search_session_id"]
else:
raise Exception(f"Failed to create search session: {response.status_code}")
def start_chat(search_session_id, query):
url = f"{BASE_URL}/workspaces/{WORKSPACE}/pipelines/{PIPELINE}/chat"
data = {
"chat_history_limit": 3,
"debug": False,
"view_prompts": False,
"queries": [query],
"search_session_id": search_session_id
}
response = requests.post(url, headers=headers, json=data)
return response.status_code, response.json()
def main():
try:
# Get the pipeline ID
pipeline_id = get_pipeline_id()
print(f"Pipeline ID: {pipeline_id}")
# Create a search session
search_session_id = create_search_session(pipeline_id)
print(f"Search Session ID: {search_session_id}")
# Start the chat
query = 'How do you present datetime objects in human readable format?"?'
status_code, response_data = start_chat(search_session_id, query)
print(f"Chat Status Code: {status_code}")
print("Chat Response:")
print(json.dumps(response_data, indent=2))
except Exception as e:
print(f"An error occurred: {str(e)}")
if __name__ == "__main__":
main()
#!/bin/bash
API_KEY="<your API key>"
BASE_URL="https://api.cloud.deepset.ai/api/v1"
WORKSPACE="peps"
PIPELINE="rag-chat"
# Get pipeline ID
PIPELINE_ID=$(curl --silent --request GET \
--url "${BASE_URL}/workspaces/${WORKSPACE}/pipelines/${PIPELINE}" \
--header "accept: application/json" \
--header "authorization: Bearer ${API_KEY}" | jq -r .pipeline_id)
echo "Pipeline ID: $PIPELINE_ID"
# Create search session
SEARCH_SESSION_ID=$(curl --silent --request POST \
--url "${BASE_URL}/workspaces/${WORKSPACE}/search_sessions" \
--header "accept: application/json" \
--header "authorization: Bearer ${API_KEY}" \
--header "content-type: application/json" \
--data "{\"pipeline_id\": \"$PIPELINE_ID\"}" | jq -r .search_session_id)
echo "Search Session ID: $SEARCH_SESSION_ID"
# Start chat
curl --request POST \
--url "${BASE_URL}/workspaces/${WORKSPACE}/pipelines/${PIPELINE}/chat" \
--header "accept: application/json" \
--header "authorization: Bearer ${API_KEY}" \
--header "content-type: application/json" \
--data "{
\"chat_history_limit\": 3,
\"debug\": false,
\"view_prompts\": false,
\"queries\": [
\"How do you present datetime objects in human readable format?\"
],
\"search_session_id\": \"$SEARCH_SESSION_ID\"
}"
Start a New Chat
To start a new chat, you must first create a new search session and then start a chat using the ID of the newly created session.
- Call the Create Search Session endpoint.
- Call the Chat endpoint providing the search session ID.
Show Previous Chats
Use the Pipeline Search History endpoint to display previous chats. Use this code snippet as a starting point for the request. Fill in:
- the pipeline and workspace name (in the URL).
- Haystack Platform API key (in headers).
- Python
- cURL
import requests
url = "https://api.cloud.deepset.ai/api/v1/workspaces/peps/pipelines/rag-chat/search_history" #peps is the workspace name, rag-chat is the pipeline name
headers = {
"accept": "application/json",
"authorization": "Bearer <your_api_key>"
}
response = requests.get(url, headers=headers)
print(response.text)
curl --request GET \
--url https://api.cloud.deepset.ai/api/v1/workspaces/legal-chat/pipelines/rag-chat/search_history \
--header 'accept: application/json' \
--header 'authorization: Bearer <your_api_key>'
Example
This is an example Python script that:
- Gets the pipeline ID and starts a new chat in the search session.
- Resets the newly created chat.
- Retrieves and displays a list of previous chats.
The script is available as Google Colab: ![]()
Was this page helpful?