DeepsetPDFToBase64Image
Convert documents sources from PDF files to base64-encoded images.
This component is deprecated. It will continue to work in your existing pipelines. You can replace it with the PDFToImageContent component.
DeepsetPDFDocumentToBase64Image is a converter used in visual question answering pipelines to extract images from downloaded PDFs. These images are then sent to a visual Generator that can process them. It converts documents accompanied by metadata containing the file_path and the page_number pointing to the location of the image.
Converting documents doesn't happen if:
- The
file_pathdoesn't exist in the metadata. - The
page_numberdoesn't exist in the metadata. - The file path doesn't start with the expected root path.
- The file path doesn't end with
.pdf.
Key Features
- Converts PDF documents to base64-encoded images for use in visual question answering pipelines.
- Outputs both text documents and corresponding
Base64Imageobjects. - Configurable detail level (
auto,low, orhigh) for image processing. - Handles missing page numbers with the
missing_page_numberparameter.
Configuration
- Drag the
DeepsetPDFDocumentToBase64Imagecomponent onto the canvas from the Component Library. - Click on the component to open the configuration panel.
- On the General tab:
- Set the Detail level:
auto(default),low, orhigh. Choosehighfor best results orlowfor lowest inference costs.
- Set the Detail level:
- Go to the Advanced tab to configure
missing_page_numberto control how documents without apage_numberin their metadata are handled.
Connections
DeepsetPDFDocumentToBase64Image receives a list of Document objects from DeepsetFileDownloader through its documents input. It outputs both a list of text documents through its documents output and a list of Base64Image objects through its base64_images output. You typically connect its base64_images output to a visual Generator such as DeepsetAzureOpenAIVisionGenerator.
This is how you connect the components in Builder:
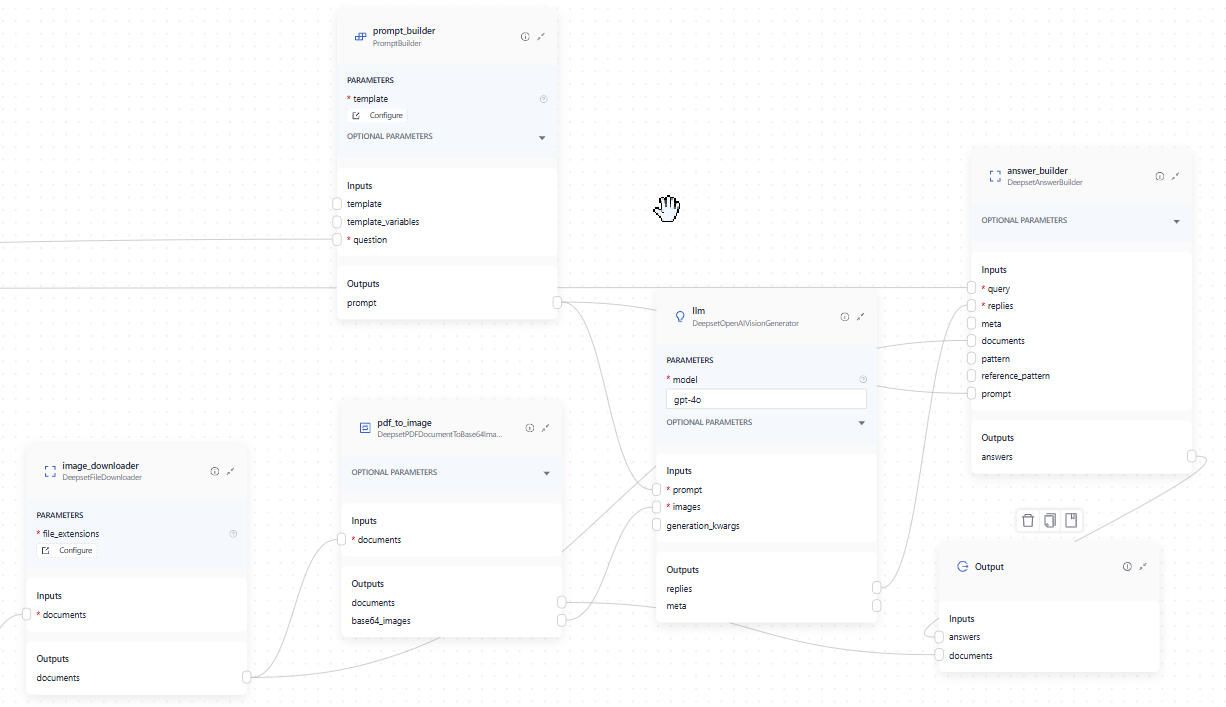
Usage Examples
Basic Configuration
pdf_to_image:
type: deepset_cloud_custom_nodes.converters.pdf_to_image.DeepsetPDFDocumentToBase64Image
init_parameters:
detail: high
Using the Component in a Pipeline
This component is used in our visual question answering templates, where it receives documents from DeepsetFileDownloader and sends them to DeepsetAzureOpenAIVisionGenerator.
Here's the complete pipeline YAML:
# haystack-pipeline
components:
bm25_retriever: # Selects the most similar documents from the document store
type: haystack_integrations.components.retrievers.opensearch.bm25_retriever.OpenSearchBM25Retriever
init_parameters:
document_store:
type: haystack_integrations.document_stores.opensearch.document_store.OpenSearchDocumentStore
init_parameters:
use_ssl: True
verify_certs: False
hosts:
- ${OPENSEARCH_HOST}
http_auth:
- "${OPENSEARCH_USER}"
- "${OPENSEARCH_PASSWORD}"
embedding_dim: 1024
similarity: cosine
top_k: 20 # The number of results to return
query_embedder:
type: haystack.components.embedders.sentence_transformers_text_embedder.SentenceTransformersTextEmbedder
init_parameters:
model: "BAAI/bge-m3"
tokenizer_kwargs:
model_max_length: 1024
embedding_retriever: # Selects the most similar documents from the document store
type: haystack_integrations.components.retrievers.opensearch.embedding_retriever.OpenSearchEmbeddingRetriever
init_parameters:
document_store:
type: haystack_integrations.document_stores.opensearch.document_store.OpenSearchDocumentStore
init_parameters:
use_ssl: True
verify_certs: False
hosts:
- ${OPENSEARCH_HOST}
http_auth:
- "${OPENSEARCH_USER}"
- "${OPENSEARCH_PASSWORD}"
embedding_dim: 1024
similarity: cosine
top_k: 20 # The number of results to return
document_joiner:
type: haystack.components.joiners.document_joiner.DocumentJoiner
init_parameters:
join_mode: concatenate
ranker:
type: haystack.components.rankers.transformers_similarity.TransformersSimilarityRanker
init_parameters:
model: "BAAI/bge-reranker-v2-m3"
top_k: 5
model_kwargs:
torch_dtype: "torch.float16"
tokenizer_kwargs:
model_max_length: 1024
image_downloader:
type: deepset_cloud_custom_nodes.augmenters.deepset_file_downloader.DeepsetFileDownloader
init_parameters:
file_extensions:
- ".pdf"
pdf_to_image:
type: deepset_cloud_custom_nodes.converters.pdf_to_image.DeepsetPDFDocumentToBase64Image
init_parameters:
detail: "high"
prompt_builder:
type: haystack.components.builders.prompt_builder.PromptBuilder
init_parameters:
template: |-
Answer the question briefly and precisely based on the pictures.
Give reasons for your answer.
When answering the question only provide references within the answer text.
Only use references in the form [NUMBER OF IMAGE] if you are using information from a image.
For example, if the first image is used in the answer add [1] and if the second image is used then use [2], etc.
Never name the images, but always enter a number in square brackets as a reference.
Question: {{ question }}
Answer:
llm:
type: deepset_cloud_custom_nodes.generators.openai_vision.DeepsetOpenAIVisionGenerator
init_parameters:
api_key: {"type": "env_var", "env_vars": ["OPENAI_API_KEY"], "strict": False}
model: "gpt-4o"
generation_kwargs:
max_tokens: 650
temperature: 0.0
seed: 0
answer_builder:
type: deepset_cloud_custom_nodes.augmenters.deepset_answer_builder.DeepsetAnswerBuilder
init_parameters:
reference_pattern: acm
connections: # Defines how the components are connected
- sender: bm25_retriever.documents
receiver: document_joiner.documents
- sender: query_embedder.embedding
receiver: embedding_retriever.query_embedding
- sender: embedding_retriever.documents
receiver: document_joiner.documents
- sender: document_joiner.documents
receiver: ranker.documents
- sender: ranker.documents
receiver: image_downloader.documents
- sender: image_downloader.documents
receiver: pdf_to_image.documents
- sender: pdf_to_image.base64_images
receiver: llm.images
- sender: prompt_builder.prompt
receiver: llm.prompt
- sender: image_downloader.documents
receiver: answer_builder.documents
- sender: prompt_builder.prompt
receiver: answer_builder.prompt
- sender: llm.replies
receiver: answer_builder.replies
inputs: # Define the inputs for your pipeline
query: # These components will receive the query as input
- "bm25_retriever.query"
- "query_embedder.text"
- "ranker.query"
- "prompt_builder.question"
- "answer_builder.query"
filters: # These components will receive a potential query filter as input
- "bm25_retriever.filters"
- "embedding_retriever.filters"
outputs: # Defines the output of your pipeline
documents: "pdf_to_image.documents" # The output of the pipeline is the retrieved documents
answers: "answer_builder.answers" # The output of the pipeline is the generated answers
Parameters
Inputs
| Parameter | Type | Description |
|---|---|---|
documents | List[Document] | A list of documents with image information in their metadata. The expected metadata is: meta = {"file_path": str, "page_number": int}. If this metadata is not present, the document is skipped and the component shows a warning. |
Outputs
| Parameter | Type | Description |
|---|---|---|
documents | List[Document] | A list of text documents. |
base64_images | List[Base64Image] | A list of base64 encoded images corresponding to the documents they were converted from. |
Init Parameters
These are the parameters you can configure in Pipeline Builder:
| Parameter | Type | Default | Description |
|---|---|---|---|
detail | Literal['auto', 'low', 'high'] | auto | Controls how the model processes the image and generates its textual understanding. See OpenAI documentation. |
missing_page_number | Literal['skip', 'all_pages'] | skip | Controls how to handle documents that do not have a page_number in their metadata. skip skips such documents. all_pages extracts images from all pages of the PDF if the page_number is not present. |
Run Method Parameters
These are the parameters you can configure for the component's run() method. This means you can pass these parameters at query time through the API, in Playground, or when running a job. For details, see Modify Pipeline Parameters at Query Time.
| Parameter | Type | Default | Description |
|---|---|---|---|
documents | List[Document] | A list of documents with image information in their metadata. The expected metadata is: meta = {"file_path": str, "page_number": int}. If this metadata is not present, the document is skipped and the component shows a warning. |
Was this page helpful?