DeepsetMetaFieldDocumentGrouper
Group document lists based on their metadata.
Basic Information
- Type:
deepset_cloud_custom_nodes.augmenters.grouper.DeepsetMetaFieldDocumentGrouper - Components it can connect with:
- Retrievers: It can receive documents from a retriever and group them based on a metadata key.
- Any component that accepts or outputs lists of documents.
Inputs
Name | Type | Description |
|---|---|---|
| List of documents lists | The documents to be grouped. |
Outputs
| Name | Type | Description |
|---|---|---|
document_lists | Lists of documents | Lists of documents grouped by the specified metadata key. |
Overview
DeepsetMetaFieldDocumentGrouper groups nested lists of documents by the metadata key you specify. You can use it in scenarios where you must categorize or cluster documents according to a common attribute. For example, you can use it to group documents the Retriever returns to show only one document per file, or to organize documents by topic or category.
You can specify how to sort documents within each group based on their preset scores or the calculated reciprocal rank fusion scores. It also makes it possible to control the number of document lists and the number of documents within each list.
It first groups documents based on the metadata key and then sorts documents within each group according to their scores. After that, it limits the number of documents per group and the number of groups accoring to the top_k values set. Finally, it orders the groups based on the sum or their document's scores.
Usage Example
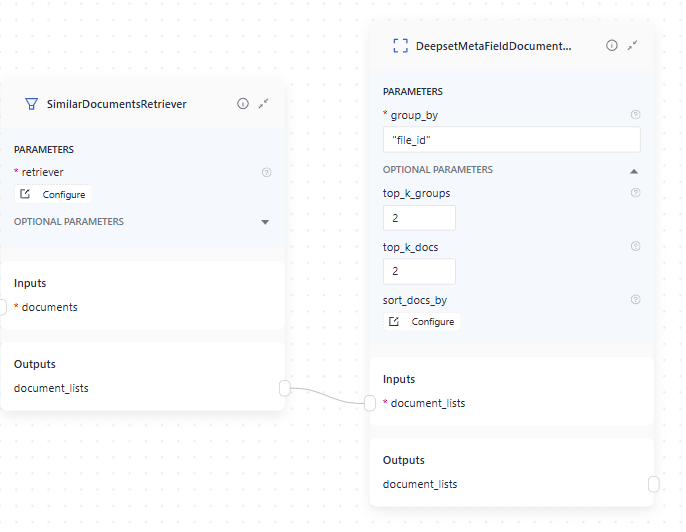
This is an example of DeepsetMetaFieldDocumentGrouper used together with SimilarDocumentsRetriever:
Parameters
Init Parameters
These are the parameters you can configure in Pipeline Builder:
Parameter | Type | Possible Values | Description |
|---|---|---|---|
| String | Default: | The metadata key to group the documents by. |
| Integer | Default: | The maximum number of document groups to return. |
| Integer | Default: | The maximum number of documents to return within each group. |
| Literal |
| Specifies how documents within each aggregation group are sorted. Possible options:
|
Run Method Parameters
These are the parameters you can configure for the component's run() method. This means you can pass these parameters at query time through the API, in Playground, or when running a job. For details, see Modify Pipeline Parameters at Query Time.
Run() method parameters take precedence over initialization parameters.
Parameter | Type | Description |
|---|---|---|
| Lists of | The list of documents to group. |
Updated about 2 months ago