DeepsetNvidiaNIMTextEmbedder
Embed strings of text using embedding models by NVIDIA NIM on optimized hardware.
Key Features
- Embeds text strings (typically queries) using NVIDIA NIM models running on hardware optimized for performance by deepset.
- Unlike models hosted on platforms like Hugging Face, these models are not downloaded at query time — you choose a model upfront on the component card.
- The optimized models are only available on Haystack Enterprise Platform. To run this component on your own hardware, use a sentence transformers embedder instead.
- Use in query pipelines to transform a query into a vector for semantic search.
- Configurable truncation and normalization.
Embedding Models in Query Pipelines and Indexes
The embedding model you use to embed documents in your indexing pipeline must be the same as the embedding model you use to embed the query in your query pipeline.
This means the embedders for your indexing and query pipelines must match. For example, if you use CohereDocumentEmbedder to embed your documents, you should use CohereTextEmbedder with the same model to embed your queries.
Configuration
- Drag the
DeepsetNvidiaNIMTextEmbeddercomponent onto the canvas from the Component Library. - Click on the component to open the configuration panel.
- On the General tab:
- Select the NVIDIA NIM embedding model from the list on the component card.
- Go to the Advanced tab to configure
prefix,suffix,truncate,normalize_embeddings,timeout, andbackend_kwargs.
Connections
DeepsetNvidiaNIMTextEmbedder accepts a text string through its text input. It outputs the embedding as a list of floats through its embedding output, plus usage metadata through its meta output.
Connect the Input component's query output to DeepsetNvidiaNIMTextEmbedder's text input. Then connect DeepsetNvidiaNIMTextEmbedder's embedding output to an embedding retriever's query_embedding input.
Usage Examples
Basic Configuration
DeepsetNvidiaNIMTextEmbedder:
type: deepset_cloud_custom_nodes.embedders.nvidia.nim_text_embedder.DeepsetNvidiaNIMTextEmbedder
init_parameters:
model: nvidia/nv-embedqa-e5-v5
prefix: ''
suffix: ''
normalize_embeddings: true
This is an example of a DeepsetNvidiaNIMTextEmbedder used in a query pipeline. It receives the text to embed from Input and sends the embedded query to OpenSearchEmbeddingRetriever:
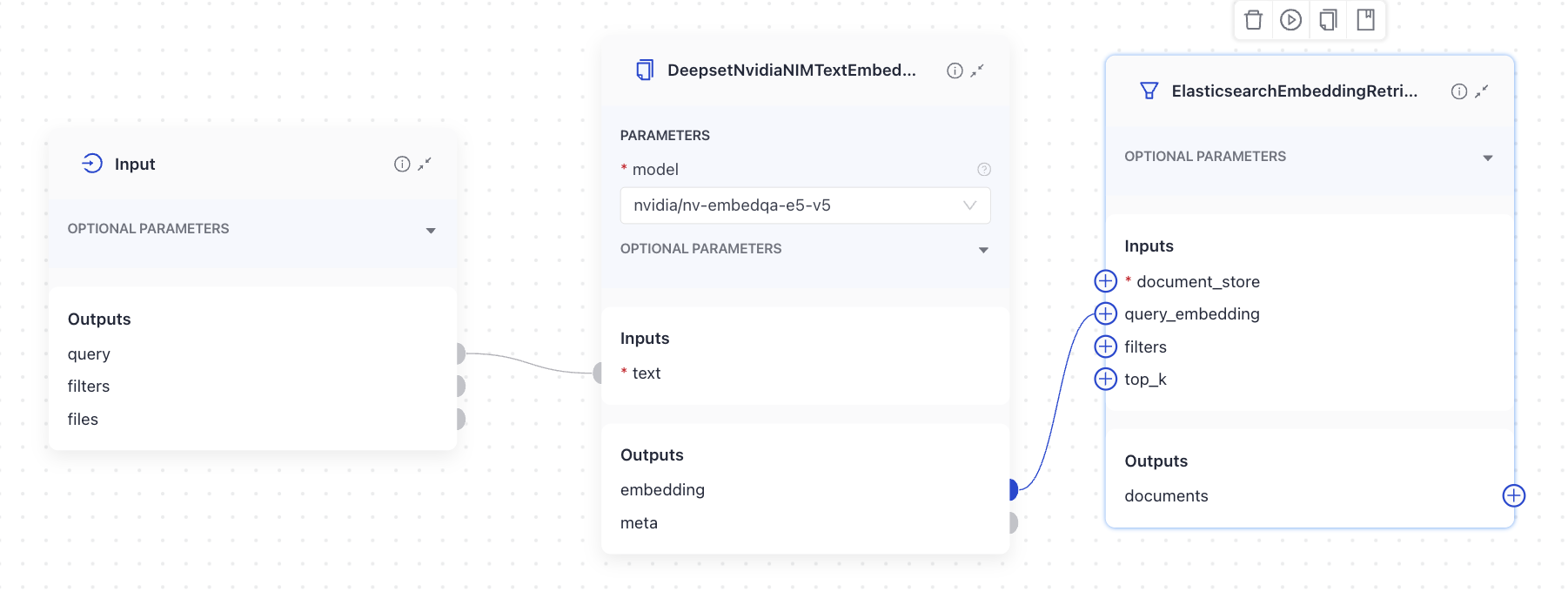
Here's the YAML configuration:
components:
DeepsetNvidiaNIMTextEmbedder:
type: deepset_cloud_custom_nodes.embedders.nvidia.nim_text_embedder.DeepsetNvidiaNIMTextEmbedder
init_parameters:
model: nvidia/nv-embedqa-e5-v5
prefix: ''
suffix: ''
normalize_embeddings: true
retriever:
type: haystack_integrations.components.retrievers.opensearch.embedding_retriever.OpenSearchEmbeddingRetriever
init_parameters:
document_store:
type: haystack_integrations.document_stores.opensearch.document_store.OpenSearchDocumentStore
init_parameters:
hosts:
index: default
top_k: 10
connections:
- sender: DeepsetNvidiaNIMTextEmbedder.embedding
receiver: retriever.query_embedding
max_runs_per_component: 100
inputs:
query:
- DeepsetNvidiaNIMTextEmbedder.text
outputs:
documents: retriever.documents
Parameters
Inputs
| Parameter | Type | Description |
|---|---|---|
text | str | The text to embed. |
Outputs
| Parameter | Type | Description |
|---|---|---|
embedding | List[float] | Embedding of the text. |
meta | Dict[str, Any] | Metadata on usage statistics. |
Init Parameters
These are the parameters you can configure in Pipeline Builder:
| Parameter | Type | Default | Description |
|---|---|---|---|
| model | DeepsetNvidiaNIMEmbeddingModels | DeepsetNvidiaNIMEmbeddingModels.NVIDIA_NV_EMBEDQA_E5_V5 | The model to use for calculating embeddings. Choose a model from the list on the component card. |
| prefix | str | A string to add at the beginning of the string being embedded. Can be used to prepend the text with an instruction, as required by some embedding models, such as E5 and bge. | |
| suffix | str | A string to add at the end of the string being embedded. | |
| truncate | Optional[EmbeddingTruncateMode] | None | Specifies how to truncate inputs longer than the maximum token length. Possible options are: START, END, NONE. If set to START, the input is truncated from the start. If set to END, the input is truncated from the end. If set to NONE, returns an error if the input is too long. |
| normalize_embeddings | bool | True | Whether to normalize the embeddings. Normalization is done by dividing the embedding by its L2 norm. |
| timeout | Optional[float] | None | Timeout for request calls in seconds. |
| backend_kwargs | Optional[Dict[str, Any]] | None | Keyword arguments to further customize model behavior. |
Run Method Parameters
These are the parameters you can configure for the component's run() method. This means you can pass these parameters at query time through the API, in Playground, or when running a job. For details, see Modify Pipeline Parameters at Query Time.
| Parameter | Type | Default | Description |
|---|---|---|---|
| text | str | The text to embed. |
Was this page helpful?